












深度学习研究就像武林大会?
没想到,这些看起来啥都搞的科技公司和AI实验室其实,都有一个自己深耕的「流派」。

DeepMind
作为Alphabet的子公司,DeepMind可以说是强化学习的代名词。
从AlphaGo到MuZero以及最近的AlphaFold 2,DeepMind一直在寻求强化学习方面的突破。
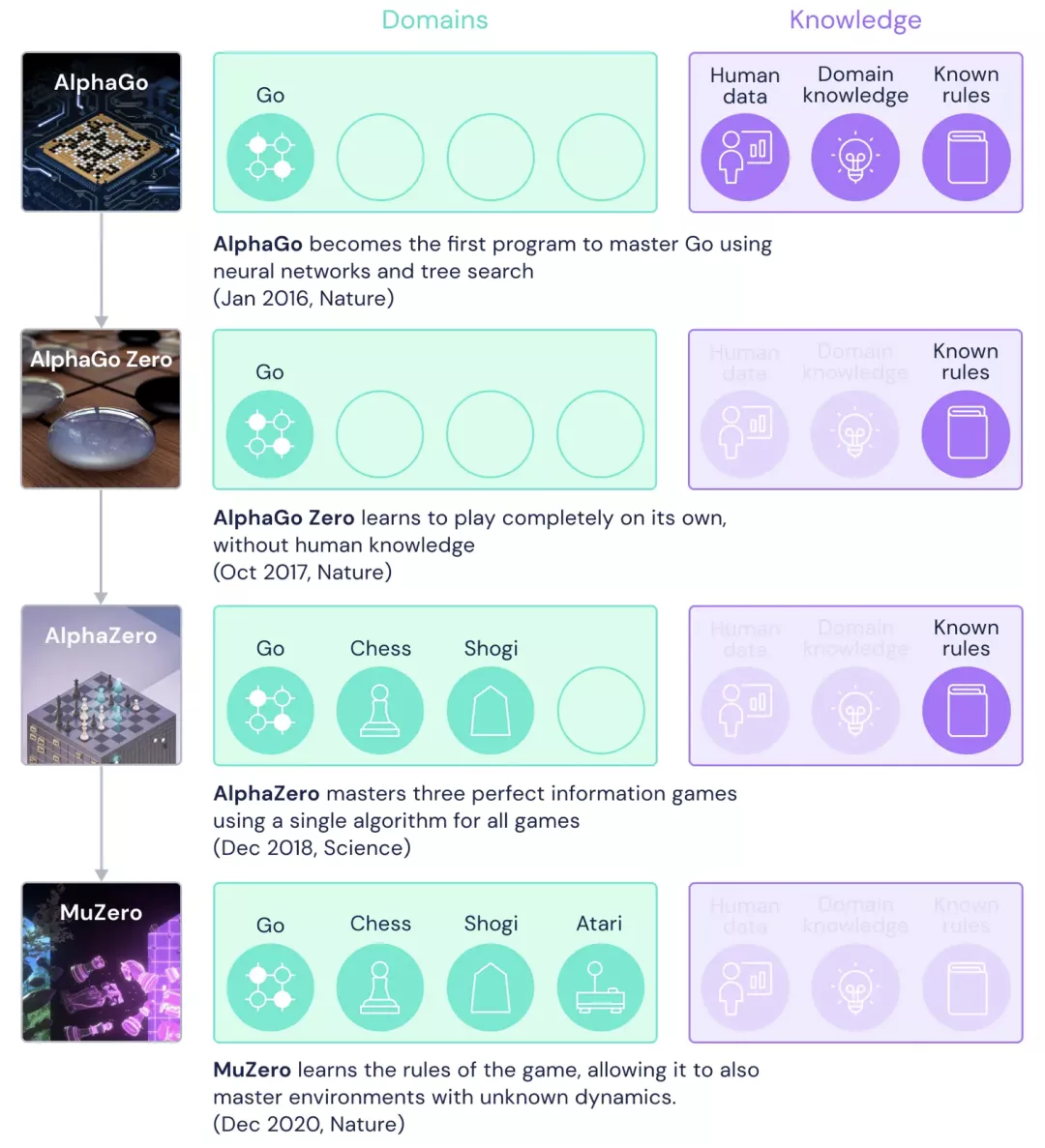
AlphaGo是一个打败专业人类围棋选手的计算机程序。它结合了先进的搜索树和深度神经网络。
MuZero除了在围棋、国际象棋和象棋上达到了AlphaZero的水平之外,同时还掌握了一系列视觉上非常复杂的Atari游戏。
而MuZero在训练的时候没有任何外部的经验,只知道游戏的规则。
https://deepmind.com/blog/article/muzero-mastering-go-chess-shogi-and-atari-without-rules
这些神经网络将围棋棋盘的描述作为输入,并通过不同的层进行处理,这其中则包含了数百万个神经元般的连接。
模型通过一个「策略网络」选择下一步棋,并通过另一个「价值网络」预测游戏的赢家。

此外,DeepMind还推出了一个能够预测蛋白质结构的系统:AlphaFold。
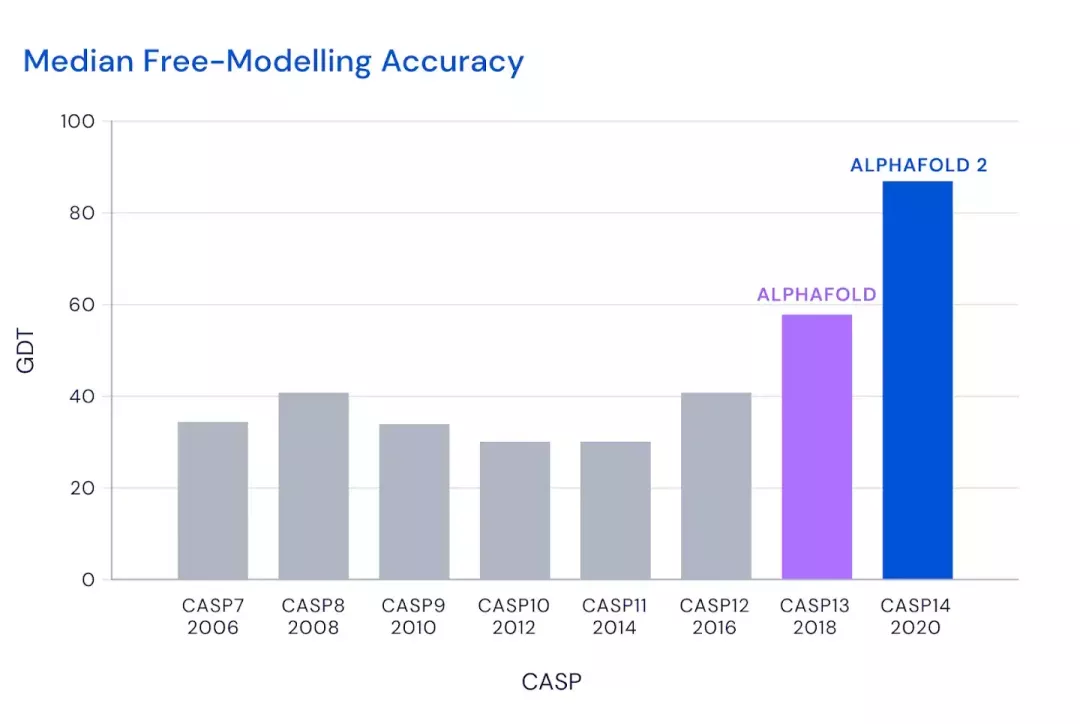
2018年,AlphaFold在国际蛋白质结构预测竞赛(CASP)上首次亮相,在98只参赛队伍中排名第一!
而第二代AlphaFold的突破在于,预测所有原子的3D结构,更快更准确地预测出蛋白质结构。
目前,DeepMind团队将AlphaFold应用到20296种蛋白质,占人类蛋白质组的 98.5%。
AlphaFold几乎是预测了人类蛋白质组里以单个蛋白为单位的空间三维结构,而且结果相当精确!这本身就是结构生物学上的一大突破。
OpenAI
GPT-3是全球谈论最多的Transformer模型之一。
对于即将推出的语言模型GPT-4,虽然规模不会比GPT-3更大,但是会更加侧重代码的生成能力。
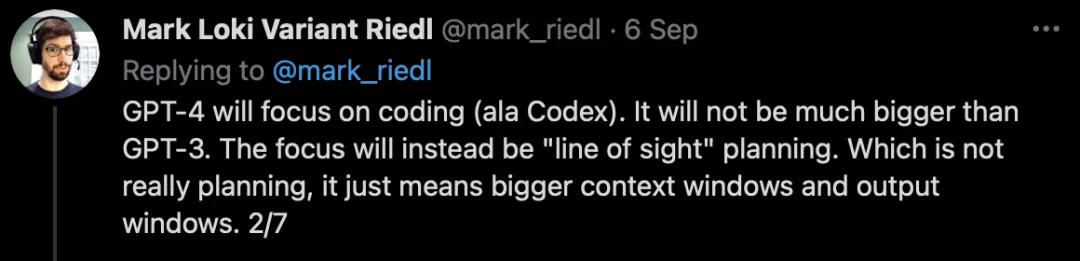
最近,OpenAI推出了OpenAI Codex,一个将自然语言翻译成代码的AI系统。
它是GPT-3的衍生版本,其训练数据既包含自然语言,也包含数十亿行公开来源的源代码,包括公共GitHub存储库的代码。
目前,GPT-3的竞争对手还包括EleutherAI GPT-j、BAAI的Wu Dao 2.0和谷歌的Switch Transformer等。
总而言之,OpenAI希望通过一系列Transformer模型实现AGI。
Facebook通过基础的、开放的科学研究,让跨领域的自监督学习技术改善其产品中的图像、文本、音频和视频理解系统。
基于自监督学习的预训练语言模型XLM-R,利用RoBERTa架构改善了Instagram和Facebook上的多语仇恨言论分类器。

Facebook认为,自监督学习是通往人类水平智能的正确道路。并通过公开分享其最新工作并在顶级会议上发表文章以及同时组织研讨会等,来加速这一领域的研究。
最近的一些工作包括VICReg、无文本NLP、DINO等。
谷歌是自动机器学习(AutoML)的先驱者之一。
它正在高度多样化的领域中推进AutoML,如时间序列分析和计算机视觉。
今年,谷歌大脑的研究人员推出了一种新的基于符号编程的AutoML方法:PyGlove。其应用于Python的通用符号编程库,从而实现AutoML的符号表述。
谷歌在该领域的一些最新产品包括Vertex AI、AutoML视频智能、AutoML自然语言、AutoML翻译和AutoML表格。

Apple
为何iPhone上的Siri在听到我们自己说「Hey Siri」时会有反应,但是对其他人说的都没有反应?
按理来说,训练一个这种模型,会收集我们的声音数据,并且这些数据都会保存在iPhone上。
但其实不然,苹果采用了一种分布式机器学习形式:联邦学习(Federated Learning。
联邦学习可以有效解决数据孤岛问题,在不公布用户数据的前提下,可以将用户的多个数据集中起来汇集成一个统一的模型。
这样既确保边缘的机器学习模型的顺利训练,同时维护用户数据的隐私和安全。
联邦学习是由谷歌研究人员在2016年的论文「Communication Efficient Learning of Deep Networks for Decentralized Data」中首次提出的,现已被业界的各种参与者广泛采用。

https://arxiv.org/pdf/1602.05629.pdf
2019年,苹果与斯坦福大学合作,发表了一篇名为「保护重构及其在私有联合学习中的应用」的研究论文,展示了以前不可能实现的大规模本地私有模型训练的实用方法。

https://arxiv.org/pdf/1812.00984.pdf
该研究还涉及到理论和经验上的方法,以适应大规模的图像分类和语言模型,效用几乎没有下降。
目前,苹果也在研究各种创新方法,通过利用联邦学习和分布式替代技术,开发注重用户隐私的产品和应用程序。
Microsoft
微软研究院是全球顶尖人工智能实验室之一,在计算机视觉和语音分析方面开创了机器教学研究和技术的先河。
随着AI应用的场景越来越丰富,加上数据量小、任务复杂等种种实践中可能出现的挑战,有时机器学习的结果并不理想,而且效率低下。
为此,机器教学(Machine Teaching)便诞生了,人类可以利用自己的专业知识和经验帮助AI进行更有针对性的学习,帮助强化学习算法更快地找到解决方案。
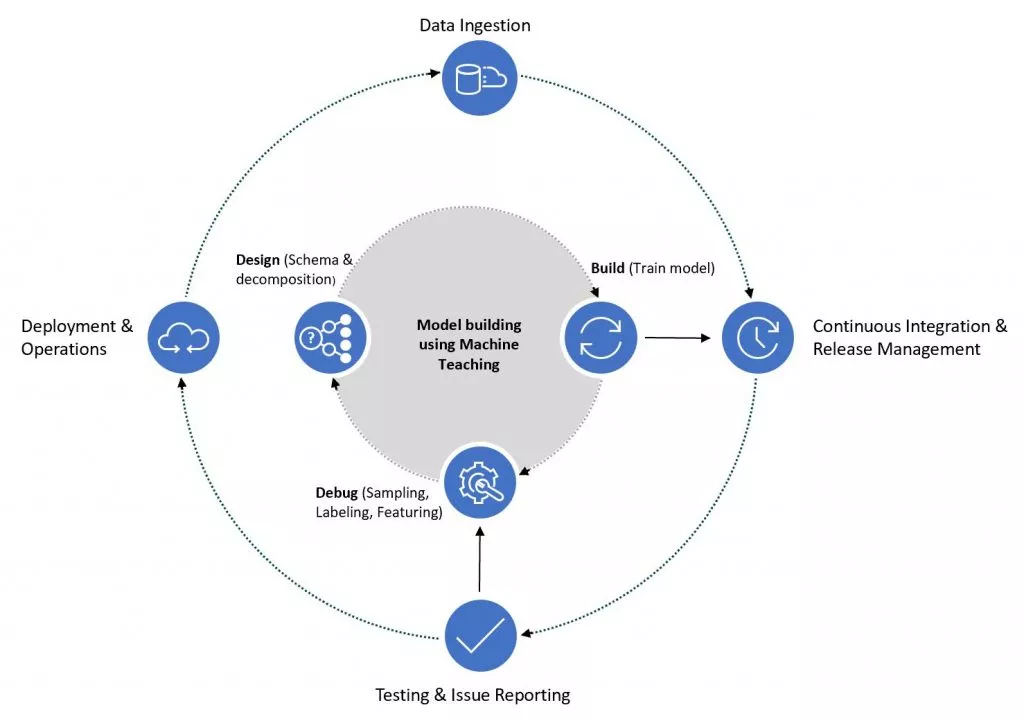
https://www.msra.cn/zh-cn/news/features/machine-teaching
此外,在智能方面,微软涵盖了人工智能、计算机视觉、搜索和信息检索等研究领域。系统方面,则提供量子计算、数据平台和分析、安全、隐私和密码学等方面的资源。
Amazon
由于迁移学习方法在Alexa上的表现十分出色,亚马逊目前已经成为领先研究中心之一。
无论是在不同的语言模型、技术,还是更好的机器翻译中,亚马逊都推动了迁移学习领域的研究。
今年1月,亚马逊的研究人员提出了ProtoDA,一种高效的用于几率意图分类的迁移学习方法。
IBM
尽管IBM在机器学习方面开创了先河,但却失去了其在科技公司中的领先地位。
在1950年,IBM的Arthur Samuel开发了一个用于下棋的计算机程序(深蓝),一个专门分析国际象棋的超级电脑。
1996年2月10日,深蓝首次挑战国际象棋世界冠军卡斯巴罗夫,但以2-4落败。其后研究小组把深蓝加以改良——它有一个昵称叫「更深的蓝」(depper blue)。并在1997年再度挑战卡斯巴罗夫,最终以3.5—2.5击败对手.
到了2020年,IBM则开始推动它在量子机器学习方面的研究。
目前,IBM正在开拓专业硬件并建立电路库,使研究人员、开发人员和企业能够在没有量子计算知识的前提下,通过量子云服务来编码语言,
2023年,IBM期望能提供整套跨域预构建运行,可从基于云的API调用,并用通用的开发框架。
IBM坚信已经同量子内核和算法开发者打下了基础,并将帮助企业开发者独立探索量子计算模型,而无需考虑量子物理。
换句话说,开发人员能自由地在任何云原生混合运行中建构系统、语言和编程框架,或将量子组件集成到任何业务中。




















