












本文转自雷锋网,如需转载请至雷锋网官网申请授权。
深度学习的诞生,可以追溯到1958年。
那一年,时任康奈尔大学航空实验室研究心理学家与项目工程师的 Frank Rosenblatt 受到大脑神经元互连的启发,设计出了第一个人工神经网络,并将其称为一项"模式识别设备"。
这项设备完成后,被嫁接在庞大的 IBM 704 计算机中,经过50次试验,能够自动区分标志在左边或右边的卡片。这使 Frank Rosenblatt 倍感惊喜,他写道:
"能够创造出一台具有人类品质的机器,一向是科幻小说的热门题材,而我们即将见着这样一台能够感知、并在没有任何人工控制的情况下识别周围环境的机器的诞生。"
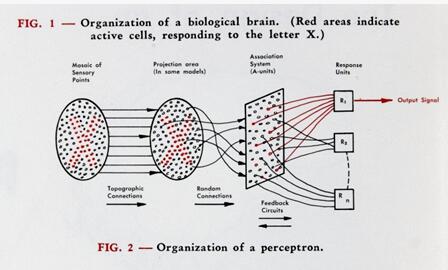
图注:感知机的运作原理
不过,与此同时,Frank Rosenblatt 也深知,当时的计算机能力无法满足神经网络的运算需求。在他的开创性工作中,他曾感叹:"随着神经网络中的连接数量不断增加……传统数字计算机的负载将会越来越重。"
图注:Frank Rosenblatt。2004年,IEEE特地成立了"IEEE Frank Rosenblatt Award",以表纪念
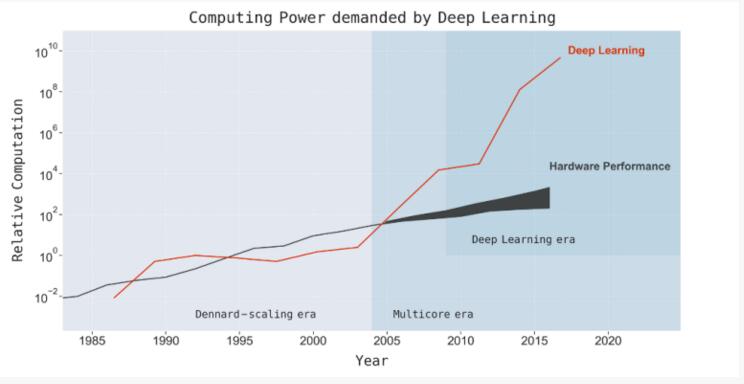
所幸,经过数十年的发展,在摩尔定律与其他计算机硬件的改进加持下,计算机的计算能力有了质的飞跃,每秒可执行的计算量增加了1000万倍,人工神经网络才有了进一步发展的空间。得益于计算机的强大算力,神经网络拥有了更多的连接与神经元,也具备了更大的、对复杂现象建模的能力。这时,人工神经网络新增了额外的神经元层,也就是我们熟知的"深度学习"。
如今,深度学习已被广泛应用于语言翻译、预测蛋白质折叠、分析医学扫描与下围棋等任务。神经网络在这些应用中的成功,使深度学习一项默默无名的技术,成为了如今计算机科学领域的领头羊。
但是,今天的神经网络/深度学习似乎又遇到了与数十年前一致的发展瓶颈:计算能力的限制。
近日,IEEE Spectrum 发表了一篇论文,对深度学习的发展未来进行了一番探讨。为什么算力会成为当今深度学习的瓶颈?可能的应对方法是什么?如果实在无法解决计算资源的限制,深度学习应该何去何从?
1、算力:福兮,祸之所倚
深度学习被誉为现代人工智能的主流。早期,人工智能系统是基于规则,应用逻辑与专业知识来推理出结果;接着,人工智能系统是依靠学习来设置可调参数,但参数量通常有限。
今天的神经网络也学习参数值,但这些参数是计算机模型的一部分:如果参数足够大,它们会成为通用的函数逼近器,可以拟合任何类型的数据。这种灵活性使得深度学习能被应用于不同领域。
神经网络的灵活性来源于(研究人员)将众多输入馈送到模型中,然后网络再以多种方式将它们组合起来。这意味着,神经网络的输出是来自于复杂公式的应用,而非简单的公式。也就是说,神经网络的计算量会很大,对计算机的算力要求也极高。
比方说,Noisy Student(一个图像识别系统)在将图像的像素值转换为图像中的物体概率时,它是通过具有 4.8 亿个参数的神经网络来实现。要确定如此大规模参数的值的训练更是让人瞠目结舌:因为这个训练的过程仅用了 120 万张标记的图像。如果联想到高中代数,我们会希望得到更多的等式,而非未知数。但在深度学习方法中,未知数的确定才是解决问题的关键。
深度学习模型是过度参数化的,也就是说,它们的参数量比可用于训练的数据点还要多。一般来说,过度参数也会导致过度拟合,这时,模型不仅仅会学习通用的趋势,还会学习训练数据的随机变幻。为了避免过度拟合,深度学习的方法是将参数随机初始化,然后使用随机梯度下降方法来迭代调整参数集,以更好地拟合数据。实验证明,这个方法能确保已学习的模型具有良好的泛化能力。
深度学习模型的成功在机器翻译中可见一斑。数十年来,人们一直使用计算机软件进行文本翻译,从语言 A 转换为语言 B。早期的机器翻译方法采用的是语言学专家设计的规则。但是,随着一项语言的可用文本数据越来越多,统计方法,比如最大熵、隐马尔可夫模型与条件随机场等方法,也逐渐应用在机器翻译中。
最初,每种方法对不同语言的有效性由数据的可用性和语言的语法特性决定。例如,在翻译乌尔都语、阿拉伯语和马来语等语言时,基于规则的方法要优于统计方法。但现在,所有这些方法都已被深度学习超越。凡是深度学习已触及的领域,几乎都展示了这项机器学习方法的优越性。
一方面,深度学习有很强的灵活性;但另一方面,这种灵活性是基于巨大的计算成本的。
如下图显示,根据已有研究,到2025年,为识别 ImageNet 数据集中的目标物体而设计的最佳深度学习系统的错误水平应该降低到仅 5%:
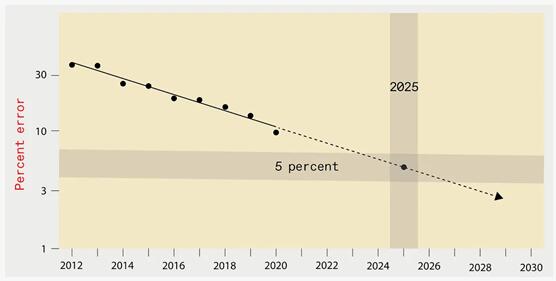
但是,训练这样一个系统所需的计算资源和能耗却是巨大的,排放的二氧化碳大约与纽约市一个月所产生的二氧化碳一样多:
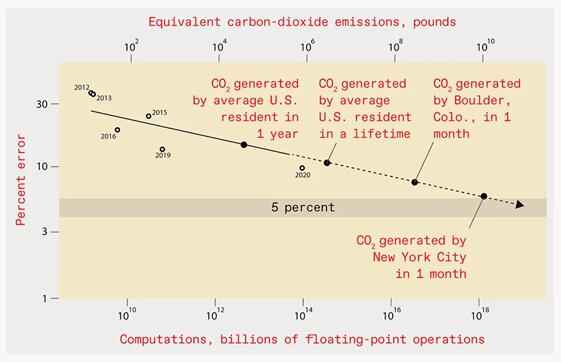
计算成本的提升,主要有两方面的原因:1)要通过因素 k 来提高性能,至少需要 k 的 2 次方、甚至更多的数据点来训练模型;2)过度参数化现象。一旦考虑到过度参数化的现象,改进模型的总计算成本至少为 k 的 4 次方。这个指数中的小小的“4”非常昂贵:10 倍的改进,就至少需要增加 10,000 倍计算量。
如果要在灵活性与计算需求之间取一个平衡点,请考虑一个这样的场景:你试图通过患者的 X 射线预测 TA 是否患有癌症。进一步假设,只有你在 X 射线中测量 100 个细节(即“变量”或“特征”),你才能找到正确的答案。这时,问题的挑战就变成了:我们无法提前判断哪些变量是重要的,与此同时,我们又要在大量的候选变量中做选择。
基于专家知识的系统在解决这个问题时,是让有放射科与肿瘤学知识背景的人来标明他们认为重要的变量,然后让系统只检查这些变量。而灵活的深度学习方法则是测试尽可能多的变量,然后让系统自行判断哪些变量是重要的,这就需要更多的数据,而且也会产生更高的计算成本。
已经由专家事先确认重要变量的模型能够快速学习最适合这些变量的值,并且只需少量的计算——这也是专家方法(符号主义)早期如此流行的原因。但是,如果专家没有正确标明应包含在模型中的所有变量,模型的学习能力就会停滞。
相比之下,像深度学习这样的灵活模型虽然效率更低,且需要更多的计算来达到专家模型的性能,但通过足够的计算(与数据),灵活模型的表现却可以胜过专家模型。
显然,如果你使用更多的计算能力来构建更大的模型,并使用更多数据训练模型,那么你就可以提升深度学习的性能。但是,这种计算负担会变得多昂贵?成本是否会高到阻碍进展?这些问题仍有待探讨。
2、深度学习的计算消耗
为了更具体地回答这些问题,来自MIT、韩国延世大学与巴西利亚大学的研究团队(以下简称“该团队”)合作,从1000多篇研究深度学习的论文中搜集数据,并就深度学习在图像分类上的应用进行了详细探讨。

论文地址:https://arxiv.org/pdf/2007.05558.pdf
在过去的几年,为了减少图像分类的错误,计算负担也随之增大。比如,2012 年,AlexNet 模型首次展示了在图形处理单元 (GPU) 上训练深度学习系统的能力:仅仅 AlexNet 的训练就使用了两个 GPU、进行了五到六天的训练。到了 2018 年,NASNet-A 将 AlexNet 的错误率降低了一半,但这一性能的提升代价是增加了 1000 多倍的计算。
从理论上讲,为了提升模型的性能,计算机的算力至少要满足模型提升的 4 次方。但实际情况是,算力至少要提升至 9 次方。这 9 次方意味着,要将错误率减半,你可能需要 500 倍以上的计算资源。
这是一个毁灭性的代价。不过,情况也未必那么糟糕:现实与理想的算力需求差距,也许意味着还有未被发现的算法改进能大幅提升深度学习的效率。
该团队指出,摩尔定律和其他硬件的进步极大地提高了芯片的性能。这是否意味着计算需求的升级无关紧要?很不幸,答案是否定的。AlexNet 和 NASNet-A 所使用的计算资源相差了 1000,但只有 6 倍的改进是来自硬件的改进;其余则要依靠更多的处理器,或更长的运行时间,这也就产生了更高的计算成本。
通过估计图像识别的计算成本与性能曲线后,该团队估计了需要多少计算才能在未来达到更出色的性能基准。他们估计的结果是,降低 5% 的错误率需要 10190 亿次浮点运算。
2019年,马萨诸塞大学阿默斯特分校的团队发表了“Energy and Policy Considerations for Deep Learning in NLP”的研究工作,便首次揭示了计算负担背后的经济代价与环境代价,在当时引起了巨大轰动。

论文地址:https://arxiv.org/pdf/1906.02243.pdf
此前,DeepMind也曾披露,在训练下围棋的深度学习系统时花了大约 3500 万美元。Open AI 在训练 GPT-3时,也耗资超过400万美元。后来,DeepMind在设计一个系统来玩星际争霸 2 时,就特地避免尝试多种方法来构建一个重要的组建,因为训练成本实在太高了。
除了科技企业,其他机构也开始将深度学习的计算费用考虑在内。一家大型的欧洲连锁超市最近便放弃了一个基于深度学习的系统。该系统能显着提高超市预测要购买哪些产品的能力,但公司高管放弃了这一尝试,因为他们认为训练和运行系统的成本太高。
面对不断上升的经济和环境成本,深度学习的研究者需要找到一个完美的方法,既能提高性能,又不会导致计算需求激增。否则,深度学习的发展很可能就此止步。
3、现有的解决方法
针对这个问题,深度学习领域的研究学者也在不断努力,希望能解决这个问题。
现有的策略之一,是使用专为高效深度学习计算而设计的处理器。这种方法在过去十年中被广泛使用,因为 CPU 已让位于 GPU,且在某种情况下,CPU 已让位于现场可编程门阵列和为特定应用设计的 IC(包括谷歌的TPU)。
从根本上说,这些方法都牺牲了计算平台的通用性来提高专门处理一类问题的效率。但是,这种专业化也面临着收益递减的问题。因此,要获取长期收益将需要采用完全不同的硬件框架——比如,可能是基于模拟、神经形态、光子或量子系统的硬件。但到目前为止,这些硬件框架都还没有产生太大的影响。
另一种减少计算负担的方法是生成在执行时规模更小的神经网络。这种策略会降低每次的使用成本,但通常会增加训练成本。使用成本与训练成本,哪一个更重要,要取决于具体情况。对于广泛使用的模型,运行成本在投资总额中的占比最高。至于其他模型,例如那些经常需要重新训练的模型,训练成本可能是主要的。在任何一种情况下,总成本都必须大于训练成本。因此,如果训练成本太高,那么总成本也会很高。也就是说,第二种策略(减少神经网络规模)的挑战是:它们并没有充分降低训练成本。
比如,有一种方法是允许训练大规模网络、但代价是在训练过程中会降低复杂性,还有一种方法是训练一个大规模网络、然后"修剪"掉不必要的连接。但是,第二种方法是通过跨多个模型进行优化来找到尽可能高效的架构,也就是所谓的“神经架构搜索”。虽然每一种方法都可以为神经网络的运行带来明显提升,但对训练的作用都不大,不足以解决我们在数据中看到的问题。但是,在大部分情况下,它们都会增加训练的成本。
有一种可以降低训练成本的新兴技术,叫做“元学习”。元学习的观点是系统同时学习各种各样的数据,然后应用于多个领域。比如,元学习不是搭建单独的系统来识别图像中的狗、猫和汽车,而是训练一个系统来识别图像中的所有物体,包括狗、猫和汽车,且可以多次使用。
但是,MIT 的研究科学家 Andrei Barbu 与他的合作者在2019年发表了一项工作(“Objectnet: A large-scale bias-controlled dataset for pushing the limits of object recognition models”),揭示了元学习的难度。他们发现,即使原始数据与应用场景之间存在极小差距,也会严重降低模型(Objectnet)的性能。他们的工作证明,当前的图像识别系统在很大程度上取决于物体是以特定的角度拍摄,还是以特定的姿势拍摄。所以,即使是识别不同姿势拍摄的相同物体,也会导致系统的准确度几乎减半。
UC Berkeley 的副教授 Benjamin Recht 等人在“Do imagenet classifiers generalize to imagenet?”(2019)中也明确地说明了这一点:即使使用专门构建的新数据集来模仿原始训练数据,模型的性能也会下降 10% 以上。如果数据的微小变化会导致性能的大幅下降,那么整个元学习系统所需的数据可能会非常庞大。因此,元学习的前景也暂时未能实现。雷锋网
还有一种也许能摆脱深度学习计算限制的策略是转向其他可能尚未发现或未被重视的机器学习类型。如前所述,基于专家的洞察力所构建的机器学习系统在计算上可以更高效,但如果这些专家无法区分所有影响因素,那么专家模型的性能也无法达到与深度学习系统相同的高度。与此同时,研究人员也在开发神经符号方法与其他技术,以将专家知识、推理与神经网络中的灵活性结合起来。雷锋网
不过,这些努力都仍在进行中。雷锋网(公众号:雷锋网)
正如 Frank Rosenblatt 在神经网络诞生之初所面临的难题一样,如今,深度学习也受到了可用计算工具的限制。面对计算提升所可能带来的经济和环境负担,我们的出路只有:要么调整深度学习的方式,要么直面深度学习停滞的未来。
相形之下,显然调整深度学习更可取。
如能找到一种方法,使深度学习更高效,或使计算机硬件更强大,那么我们就能继续使用这些灵活性更高的深度学习模型。如果不能突破计算瓶颈,也许我们又要重返符号主义时代,依靠专家知识来确定模型需要学习的内容了。




















