本文转载自微信公众号「小菜良记」,作者蔡不菜丶。转载本文请联系小菜良记公众号。
大家好,我是小菜。一个希望能够成为 吹着牛X谈架构 的男人!如果你也想成为我想成为的人,不然点个关注做个伴,让小菜不再孤单!
最近在面试的路上愈走愈远了,Redis肯定是一个热门面试方向。像有几种数据结构?如何实现延迟队列?淘汰机制是怎么样的?都快问到麻木,这些问题还常绕脑梁。那我们这篇就举一个比较常见且难度适中的面试题来聊聊。Redis 的持久化策略是怎么样的?
开局问个问题,相信被问到 Redis 持久化 的同学肯定不在少数,答对的同学肯定也不在少数,有些小伙伴说到 Redis持久化 肯定张口就来,毕竟也就 AOF 和 RDB 两个概念,只要你准备了面试,就不会被问的太惨。但是你是真的懂还是只是为了应付面试而去应付记忆?你知道 AOF 和 RDB 两个词是什么单词的缩写吗?你落地实施过吗?你真以为面试官听不出来你是背题还是实操吗?如果 4 个问题你中了一半,那不妨往下看看,也许会有些收获,起码答面试题的时候心中有小菜~!
Redis 持久化
什么是Redis持久化?
咱们先别记得往解决方向前行,先明白这道题的意思。
持久化 就是要让数据永久的保存下去。那什么是 Redis 持久化 ?那就是把Redis保存在内存的数据写到磁盘中,防止服务宕机了内存数据丢失问题。那有些小伙伴就说了,那磁盘损坏了,数据怎么持久化?就算多点备份能解决磁盘损坏问题,那如果来个多点丢失怎么整?停住停住,咱们这篇讲的是Redis内存数据->磁盘的持久化问题,可别指望靠这个问题跟面试官扯半个小时~!
咱们这篇从几个点来说明 Redis持久化 问题。
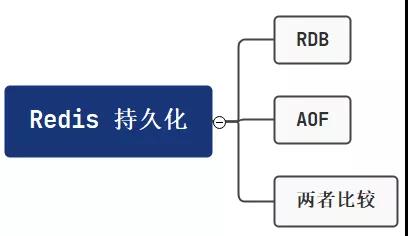
也就三点大的方向,三步走战略解决你的持久化问题。
一、RDB
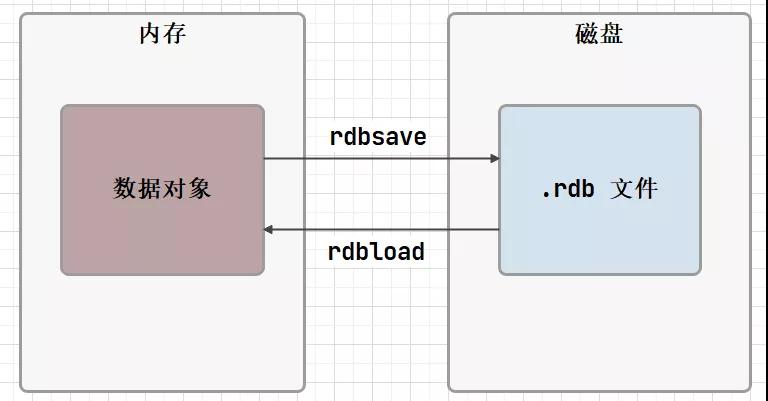
先来解决开局的问题之一,RDB 是什么单词的全称。RDB(Redis Database Backup file)--- Redis 数据备份文件,也称为 Redis 数据快照。
这个玩意就是用来将内存中的所有数据都记录到磁盘中,当 Redis 实例故障重启后,从磁盘读取快照文件,从而恢复数据。内心狂喜,看来学的第一个概念就可以解决 Redis 持久化问题~
在学 RDB 之前,我们先明白两个核心概念 fork 和 cow,下面我们会解释,这里先卖个关子。
RDB 是 Redis 中默认的持久化机制,按照一定的时间将内存中的数据以快照的方式保存到磁盘中,它会产生一个特殊类型的文件 .rdb 数据文件,同时可以通过配置文件中的 save 参数来定义快照的周期.
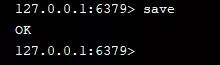
我们从配置文件中的两个配置参数入手,首先是 save 配置。
这个指令是由 Redis 主进程来执行RDB,会阻塞所有命令
我们在配置文件中找到有关于 sava 的配置
- dbfilename dump.rdb
该配置项的作用便是用来定义 rdb 文件名(需要注意该名称不能定义为路径,只能定义为文件名称)
当我们执行完 save 命令后,便可在 redis 文件夹中看到一个 dump.rdb 文件

- save <seconds> <changes>
该配置项的作用是用来定义多长时间内发生多少次变化便会执行 bgsave,如果是 save "" 则表示禁用 RDB。
我们接下来打开 save 配置进行测试
- dbfilename dump-test.rdb # 文件名为 dump-test.rdb
- save 3600 1 # 在 3600 秒内发生一次更改,便会执行 bgsave
我们通过 redis-cli 进入操作
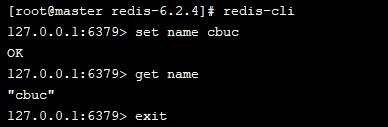
然后我们退出后便可在当前目录下看到刚刚生成的 dump-test.rdb 文件

说明我们配置是生效的,接着我们直接重启 Redis ,看是否还存在我们刚刚保存的数据

看到我们的数据,就说明 redis 持久化成功了。然后我们把刚刚生成的 dump-test.rdb 文件删除后重启 redis

这可以说明Redis 启动时是靠 .rdb 来恢复文件数据的。那我们上面一直说到的 bgsave,那 bgsave 又是如何执行的呢?
我们在前面有说过两个概念 fork 和 cow,不知道是否还有印象,这两个概念便是关键~!
bgsave 开始的时候会 fork 主进程得到一个新的子进程,而 子进程 是 共享 主进程的内存数据的。子进程会将数据写到磁盘上的一个临时的 .rdb 文件中,当子进程写完临时文件后,会将原来的 .rdb文件替换掉。这个就是 fork 的核心,那什么是 cow 呢?cow 全称 copy-on-write 技术,当主进程执行读操作的时候是访问共享内存的,而主进程执行写操作的时候,则会拷贝一份数据,执行写操作。
具体流程如下:
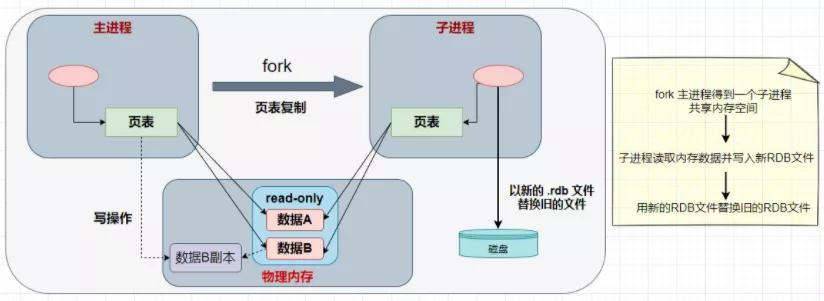
这种持久化方式有什么优点呢?
- 方便持久化,只有一个 dump.rdb 文件
- 容灾性好,可以将文件保存到安全的磁盘中
- 性能最大化,fork 子进程来完成写操作,让主进程继续处理命令,将 IO 最大化,保证 Redis 的高性能
缺点也是有的:
- 数据安全性低,RDB 是间隔一段时间来持久化 (save) ,如果持久化期间 Redis 发生故障,那么就会造成数据丢失,所以这种方式适用于数据要求不是很严谨的情况下使用
- 保存时间长,如果数据量很大,保存快照的时间就会很长,会占用磁盘空间
优劣均沾,斟酌使用
二、AOF
AOF 全称 Append Only File (追加文件)。作用便是 Redis 处理的每一个写命令都会记录在 AOF 文件中,可以看做是命令日志文件。
该功能默认是关闭的,我们可以在 redis.conf 文件中查看有关于 AOF 相关的配置项
- appendonly yes # 开启 AOF 日志记录功能,默认是关闭的
- appendfilename "appendonly.aof" # AOF 文件的名称
以上两个配置项便是用来开启 AOF 日志记录,那么还有个额外的配置项也需要了解
- appendfsync everysec # AOF 命令记录的频率
该配置项有三个可选值
| 配置项 | 刷盘时机 | 优点 | 缺点 |
|---|---|---|---|
| Always | 同步刷盘 | 可靠性高,几乎不会丢失数据 | 性能影响较大 |
| everysec | 每秒刷盘 | 性能适中 | 最多丢失1秒的数据 |
| no | 操作系统控制 | 性能最好 | 可靠性较差,可能丢失大量的数据 |
有了解 Mysql 中 relay log 日志的同学,就不会对这种模型很陌生。
原理:它是将写命令追加到 AOF 文件的末尾,使用 AOF 持久化需要设置同步选项,从而确保写命令同步到磁盘文件上的时机,这是因为对文件进行写入并不会马上将内存同步到磁盘上,而是先存储到缓存区中,然后由操作系统决定什么时候同步到磁盘。
我们开启 AOF 记录功能查看下:
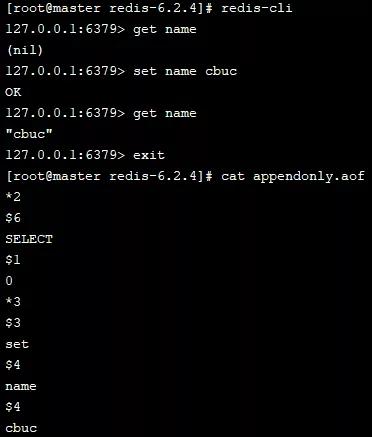
可以看出我们的每一个操作都已经记录到 AOF 文件中,我们这边通过重启 Redis 也一样能获取到刚刚存储的数据,说明持久化是有生效的~
我们看到上面的 AOF 记录文件是不是觉得很规整?但是在线上环境中越规整反而不好,因为这文件主要是给机器看的,而不是跟我们看的,因此我们最好能够进行压缩。
为了解决AOF文件体积不断增大的问题,用户可以向Redis发送 bgrewriteaof命令,这个命令会通过 通过移除AOF文件中的冗余命令 来重写(rewrite)AOF文件,使AOF文件的体积变得尽可能地小。bgrewriteaof的工作原理和 bgsave 创建快照的工作原理非常相似:Redis会创建一个子进程,然后由子进程负责对AOF文件进行重写。因为AOF文件重写也需要用到子进程,所以快照持久化因为创建子进程而导致的性能问题和内存占用问题,在AOF持久化中也同样存在。
既然存在手动触发压缩,那也存在自动触发压缩,这就得说到配置文件中的两个配置项
- auto-aof-rewrite-percentage 100
- auto-aof-rewrite-min-size 64mb
该配置项的意思为当AOF文件的体积大于64MB,并且AOF文件的体积比上一次重写之后的体积大了至少一倍(100%)的时候,Redis将执行bgrewriteaof命令。
总结下,它的优点如下:
- 数据安全。AOF 持久化可以配置 appendfsync 属性中的 always,每进行一次写命令操作就会记录到 AOF 文件中一次
- 一致性。通过 append 模型写文件,即使中途服务器宕机,也可以通过 redis-check-aof 工具来解决数据一致性问题
缺点如下:
- AOF 文件比 RDB 文件大,而且恢复速度慢
- 数据集大的时候比 RDB 文件启动效率低
同样是优劣均沾,斟酌使用
三、两者区别
分别介绍了两者,我们回顾一下两者有什么区别?
| 方面 | RDB | AOF |
|---|---|---|
| 持久化方式 | 定时对整个内存做快照 | 记录每一次执行的命令 |
| 数据完整性 | 不完整,两次备份之间会丢失 | 相对完整。取决于刷盘策略 |
| 文件大小 | 会有压缩,文件体积小 | 记录命令,文件体积很大 |
| 宕机恢复速度 | 很快 | 慢 |
| 数据恢复优先级 | 低,因为数据完整性不如AOF | 高,因为数据完整性更高 |
| 系统资源占用 | 高,大量CPU和内存消耗 | 低,主要是磁盘IO资源。且 AOF 重写时会占用大量CPU和内存资源 |
| 使用场景 | 可以容忍数分钟的数据丢失,追求更快的启动速度 | 对数据安全性要求较高 |
看完上面后,想必对两种持久化机制都有一定的了解了。两者都有优劣势,那我们该如何选择?这里给出几点意见~
如果可以忍受一小段时间内的数据丢失,可以使用 RDB 机制,定时生成 RDB 快照, 并且 RDB 恢复数据集的速度也要比 AOF 恢复的速度要快
但是如果单单使用 RDB 机制,可能导致丢失很多数据,因此我们需要综合使用 AOF 和 RDB 两种持久化机制,用 AOF 来保证数据不丢失,作为数据恢复的第一选择;用 RDB 来做不同程度的冷备份,在 AOF 文件都丢失或损坏不可用的情况下,可以使用 RDB 来进行快速的数据恢复
我们可以利用 RDB 来快速恢复数据,并用 AOF 来补全数据
我们到这里就讲述了 Redis 持久化机制的配置,通过这篇文章的学习,我相信到时候面试的时候遇到这个问题也不至于那么手足无措~!
不要空谈,不要贪懒,和小菜一起做个吹着牛X做架构的程序猿吧~点个关注做个伴,让小菜不再孤单。咱们下文见!