













作为二本上岸大厂的后端应届生,深知没人带一路摸索的艰辛,想把自己的心路历程与经验心得收获分享给大家。后期大厂面试系列持续更新中.....
1前文
之前有同学在面阿里二面被问到:MYSQL是如何实现ACID的?其实,如果叫简单介绍什么是ACID,大家肯定都能回答,但是,想要答好底层如何实现ACID特性的,还得考考功力啦!
今天,笔者简单谈谈自己对ACID特性实现原理的理解。本文主要探讨MYSQL InnoDB引擎下的ACID实现原理,对什么是事务,隔离级别简单回顾一下。
2事务与ACID
何为事务呢?书上给予的概念多而难于理解,笔者对事务的理解:一系列操作组成,要么全部成功,要么全部失败。它具备ACID四大特性,在并发下,可能存在脏读、幻读、不可重复读的并发问题,于是又引出了四大隔离级别。
01事务ACID特性
MYSQL作为一个关系型数据库,以最常见的InnoDB引擎来说,是如何保证ACID的。
(Atomicity)原子性:一些列操作要么全部成功,要么全部失败
(Isolation)隔离性:事务的结果只有提交了其他事务才可见
(Consistency)一致性:数据库总时从一个一致状态变到另一个一致状态(事务修改前后的数据总体保证一致 转账)
(Durability)持久性:事务提交后,对数据修改永久的
02原子性
在聊原子性之前,我得先给大家普及一个东西——undo log,这是啥玩意儿呢?如果想要详细了解或则想知道它具体内部咋实现的可以仔细去看书,这里我就简单分享我的理解,知道这些,面试基本够用啦。
undo log,它是一种回滚日志,既可以用来实现隔离性MVCC,也可以保证原子性。MVCC待会谈论。实现原子性的关键,是事务回滚时能够撤销所有已经成功执行的sql语句。
当事务对数据库进行修改时,InnoDB会生成对应的undo log,undo log会保存事务开始前老版本的数据,当事务发生异常,便会rollback回滚到老版本状态。当发生回滚时,InnoDB会根据undo log的内容做相反逻辑操作。
- insert语句,回滚时会执行 delete;
- delete语句,回滚时会执行insert;
- update语句,回滚时便执行相反的update,把数据改回来。
总之,MYSQL的原子性便是由undo log来保证,undo log的作用我做了一下归纳总结:
作用:undolog记录事务开始前老版本数据,用于实现回滚,保证原子性,实现MVCC,会将数据修改前的旧版本保存在undolog,然后行记录有个隐藏字段回滚指针指向老版本。
03持久性
在聊持久性之前,我们得先知道redo log。老规矩,想深入学习理解看书噢,这里只做笔者面试回答分享。
我们以一个生活小案例来理解一下下:
redo log,是一种物理日志。它类似于一个卸货的小推车,我们卸货若是每下一件物品就拿着去入库,那岂不是特浪费时间(效率低、还要找到合适存库位置)。此时,若有一个小推车,我们将货物首先存放在小推车,当推车满了再往库里存,岂不大大增加了效率。
MYSQL中也用了类似思想,我们再更新数据库时,先将更新操作记录在redo log日志,等redo log满了或则MYSQL空闲了再刷盘。
其实就是MySQL里经常说到的WAL技术,WAL的全称是Write-Ahead Logging,它的关键点就是先写日志,再写磁盘,也就是先装小推车,等不忙的时候再装库。
总之,MYSQL的持久性便是由redo log来保证,redo log的作用我做了一下归纳总结:
redo log
物理日志
作用:会记录事务开启后对数据做的修改,crash-safe
特性:空间一定,写完后会循环写,有两个指针write pos指向当前记录位置,checkpoint指向将擦除的位置,redolog相当于是个取货小车,货物太多时来不及一件一件入库太慢了这样,就先将货物放入小车,等到货物不多或则小车满了或则店里空闲时再将小车货物送到库房。用于crash-safe,数据库异常断电等情况可用redo log恢复。
以下只作了解:
写入流程:先写redo log buffer,然后wite到文件系统的page cache,此时并没有持久化,然后fsync持久化到磁盘
写入策略:根据innodb_flush_log_at_trx_commit参数控制(我的记忆:innodb以事务的什么提交方式刷新日志)
0——>事务提交时只把redo log留在redo log buffer
1——>将redo log直接持久化到磁盘(所以有个双“1”配置,后面会讲)
2——>只是把redo log写到page cache
04隔离性
说到隔离性,我们都知道MYSQL有四种隔离级别,用来解决存在的并发问题。脏读、幻读、不可重复读。
那么不同隔离级别,隔离性是怎样实现的呢?具体实现原理是怎样的呢?接下来我们就谈谈,看不懂没关系,老规矩,结尾会进行总结滴!
一句话:锁+MVCC。
锁
1、表锁
- lock table table_name read/write
- myisam执行select自动加读锁,执行update/delete/insert自动加写锁
- 表加了读锁,不会阻塞其他线程的读操作,阻塞写操作
- 表加了写锁,读写操作都阻塞
2、行锁
锁的类型
- 间隙锁-gap lock:锁定区间范围,防止幻读,左开右开,只在可重复读隔离级别下生效—|—为了阻止多个事务将记录插入到同一范围内,而这会导致幻读问题的产生
- 记录锁-record Lock:锁定行记录,索的索引,索引失效,为表锁
- 临键锁-next-key Lock:record lock+gap lock 左开右闭(解决幻读)
锁的模式
- select .... for update
- 持有写锁,别的不可加读锁,也不可加写锁
- select .... lock in share mode
- 持有读锁,别的可以再加读锁,不可加写锁
- 共享锁-读锁-S锁
- 排他锁-写锁-X锁
- 意向锁:读意向锁+写意向锁
- 自增锁
需要的时候加上,并不是马上释放,等事务提交才释放,两阶段锁协议
3、全局锁——全库逻辑备份
4、死锁
- 两个或多个事务在同一资源上相互占用,并请求加锁时,造成相互等待,无限阻塞
- innodb回滚拥有最少排他行级锁的事务
- 设置锁等待超时时间
乐观锁与悲观锁
- 悲观锁用数据库自带锁机制——写多
- 乐观锁用version版本机制或CAS算法——读多写少,很少发生冲突情况
MVCC
是什么:多版本并发控制。
原理提炼总结:使用版本链+Read View
详解:
版本链:同一行数据可能有多个版本
innodb数据表每行数据记录会有几个隐藏字段,row_id,事务ID,回滚指针。
1、Innodb采用主键索引(聚簇索引),会利用主键维护索引,若表没有主键,就用第一个非空唯一索引,若没有唯一索引,则用row_id这个隐藏字段作为主键索引。
2、事务开启会向系统申请一个事务ID,严格递增,会向行记录插入最近操作它的那个事务的ID
3、undolog会记录事务前老版本数据,然后行记录中回滚指针会指向老版本位置,如此形成一条版本链。因此可以利用undo log实现回滚,保证原子性,同时用于实现MVCC版本链。
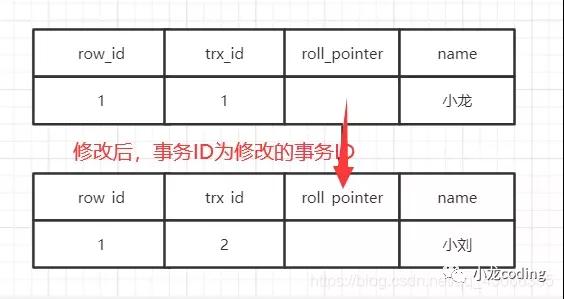
图3 版本链形成
Read View读已提交隔离级别下,会在每次查询都生成一个Read View,可重读读只在事务开始时生成一个Read View,以后每次查询都用这个Read View,以此实现不同隔离界别。
Read View里面包含些什么?(一致性视图)
一个数组+up_limit_id(低水位)+low_limit_id(高水位)(这里的up,low没写错,就是这么定义的)
1、数组里包含事务启动时当前活跃事务ID(未提交事务),低水位就是活跃事务最小ID,高水位就是下一次将分配的事务ID,也就是目前最大事务ID+1。
数据可见性规则是怎样实现的?
数据版本的可见性规则,就是基于数据的row trx_id和这个一致性视图(Read View)的对比结果得到的。
视图数组把所有的trx_id 分成了几种不同的情况
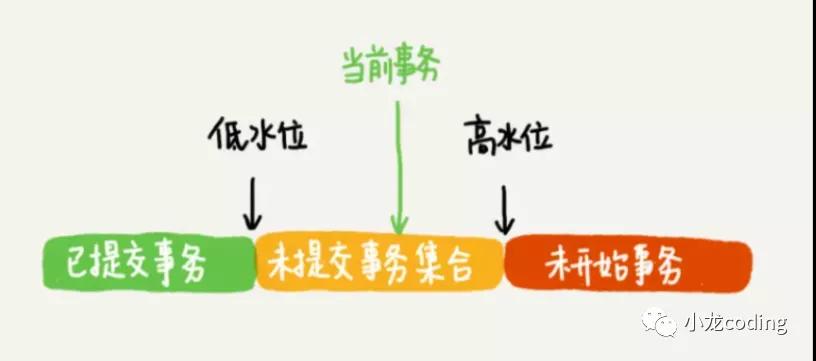
图4 数据版本可见性规则
读取原理:
某事务T要访问数据A,先获取该数据A中的事务id(获取最近操作它的事务的事务ID),对比该事务T启动时刻生成的readview:
1、如果在readview的左边(比readview都小),表示这个事务可以访问这数据(在左边意味着该事务已经提交)
2、如果在readview的右边(比readview都大),表示这个版本是由将来启动的事务生成的,是肯定不可见的;
3、如果当前事务在未提交事务集合中:
a、若 row trx_id在数组中,表示这个版本是由还没提交的事务生成的,不可见;
b. 若 row trx_id不在数组中,表示这个版本是已经提交了的事务生成的,可见。
不可以访问,获取roll_pointer,通过版本链取上一版本。
根据数据历史版本事务ID再重新与视图数组对比。
这样执行下来,虽然期间这一行数据被修改过,但是事务A不论在什么时候查询,看到这行数据的结果都是一致的,所以我们称之为一致性读。
总之,MYSQL的隔离性便是由MVCC+锁来保证,各个隔离级别实现原理我做了一下归纳总结:
隔离级别原理及解决问题分析:
- 读未提交:原理:直接读取数据,不能解决任何并发问题
- 读已提交:读操作不加锁,写操作加排他锁,解决了脏读。原理:利用MVCC实现,每一句语句执行前都会生成Read View(一致性视图)
- 可重复读:MVCC实现,只有事务开始时会创建Read View,之后事务里的其他查询都用这个Read View。解决了脏读、不可重复读,快照读(普通查询,读取历史数据)使用MVCC解决了幻读,当前读(读取最新提交数据)通过间隙锁解决幻读(lock in share mode、for update、update、detete、insert),间隙锁在可重复读下才生效。(默认隔离级别)
- 可串行化:原理:使用锁,读加共享锁,写加排他锁,串行执行
总结:读已提交和可重复读实现原理就是MVCC Read View不同的生成时机。可重复读只在事务开始时生成一个Read View,之后都用的这个;读已提交每次执行前都会生成Read View
05一致性
一致性是事务追求的最终目标,前问所诉的原子性、持久性和隔离性,其实都是为了保证数据库状态的一致性。
当然,上文都是数据库层面的保障,一致性的实现也需要应用层面进行保障。也就是你的业务,比如购买操作只扣除用户的余额,不减库存,肯定无法保证状态的一致。
你把周围的人看作魔鬼,你就生活在地狱;你把周围的人看作天使,你就生活在天堂。
本文转载自微信公众号「小龙coding」,可以通过以下二维码关注。转载本文请联系小龙coding公众号。





























