【51CTO.com快译】新冠疫情为许多企业带来了更大的推动力,以扩展云原生和分布式环境的运营。为了生存和发展,企业现在必须认真研究易于使用的云原生技术(例如API管理和集成解决方案、云原生产品、集成平台即服务以及低代码平台),加快上市时间,并实现重复使用和共享。然而由于具有的分布式特性,这些云原生应用程序在管理方面更加复杂,并且随着它们的扩展而增加。
将可观察性构建到应用程序中允许企业的团队自动收集和分析数据,以优化应用程序,并解决可能影响用户的潜在问题。此外,它显著减少了应用程序在运行时出现问题的调试时间。这使开发人员可以更多地专注于生产任务,例如开发新功能。
可观察性具有三个关键组件:日志、度量、跟踪。为了全面了解系统的行为,有必要收集这三个组件,而只有一两个组件不足以调试应用程序的复杂行为。
本文将讨论可观察性的重要性,还将研究Choreo(用于云原生工程的集成平台即服务)如何使开发人员能够使用深度可观察性功能来观察应用程序的性能、识别异常和解决问题。
1.自动可观察性
如果想在生产中收集日志、度量、跟踪的数据而不影响应用程序性能,那么在应用程序中构建可观察性需要付出巨大的努力。确保可观察性对性能的影响达到最小是开发可观察性框架时面临的主要挑战之一。如果要跟踪所有请求,那么就会带来很大的性能开销。
为了使应用程序具有可观察性,开发人员需要编写性能优化的可观察性代码,并使用自适应采样等算法,这些算法可以在不同的流量条件下动态控制性能开销。不幸的是,许多应用程序开发人员没有实现收集所有三个可观察性支柱的代码。
这有两个原因:首先,许多开发人员不具备所需的专业知识水平。其次,所需的工作量很大,使其成为一项代价高昂的工作。
而将可观察性集成到应用程序中需要多轮优化和广泛的测试,以确保没有显著的性能开销。
2.Choreo如何提供帮助
Choreo的设计方式使开发人员不必自己开发具有可观察性的应用程序。Ballerina是Choreo的底层编程语言,具有强大的可观察性框架,使用Ballerina编写的程序可以实现完全的可观察性。Choreo使用Ballerina的可观察性框架为其服务收集可观察性数据。
由于Ballerina的可观察性框架经过精心设计以确保最小的性能开销,因此Choreo应用程序可以在打开可观察性的情况下在生产环境中运行。可观察性数据以各种形式的可视化呈现给用户。用户可以使用这些可视化功能来优化应用程序,然后识别和解决可能对用户体验产生不利影响的问题。图1显示了Choreo应用程序的主要可观察性页面。

图1 Choreo中的可观察性的主页
(1)使用平均值调试高响应时间
响应时间是一个关键的性能指标,对用户体验有着直接影响。高响应时间可能会导致用户体验不佳,从而导致用户流失。不幸的是,开发人员在开发应用程序时并没有过多关注应用程序的响应时间(延迟)。只有在生产中部署应用程序之后,他们才会发现此类问题。
即使在开发人员优化响应时间的情况下,工作负载条件也会随时间变化,从而导致响应时间异常。Choreo在不同点收集应用程序的延迟,这使用户能够立即识别其代码中的瓶颈。响应时间过长可能是由于代码中的问题,或者可能与调用外部端点的延迟有关。而在Choreo中,开发人员可以识别并解决这些问题,而无需花费大量时间进行调试。图2显示了在Choreo中开发的应用程序的延迟细分情况。需要注意的是,不同的外部(连接器)调用将如何影响总延迟。
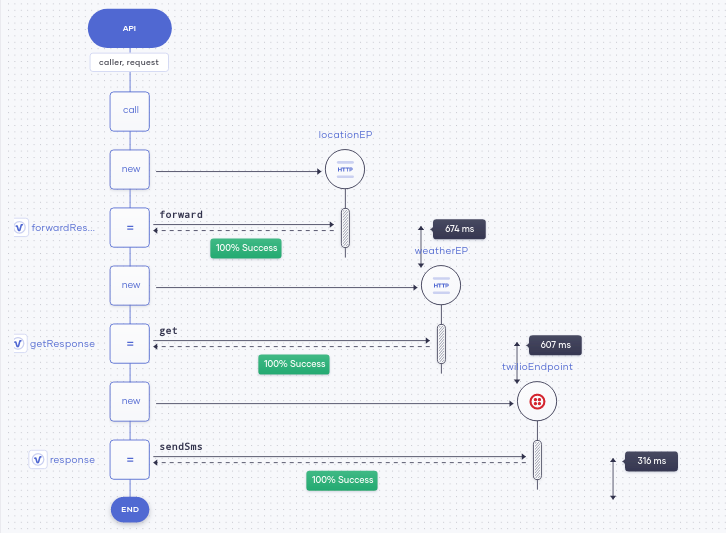
图2在Choreo中开发的应用程序的延迟细分情况
(2)调试单个请求延迟
虽然可以使用指标调试某些延迟行为,但与延迟相关的更复杂问题无法使用图2显示的平均延迟值进行调试。此类问题的示例包括响应时间的逐渐增加、平均响应时间的突然下降或峰值(称为水平偏移),以及在随机时间点出现的延迟峰值等。
Choreo允许开发人员更精细地挖掘数据以检测此类问题。例如,Choreo可观察性收集的跟踪数据允许开发人员通过调查单个请求的延迟细分来调试延迟峰值。图3显示了在Choreo中开发的应用程序的吞吐量和延迟行为。

图3在Choreo中开发的应用程序的吞吐量和延迟行为
在此假设用户了解特定请求的延迟。可以通过点击图表中的特定点来实现。当单击一个点时,就可以获得单个请求的延迟和延迟细分(Choeo显示请求在请求路径中花费时间最多的位置)。图4对此进行了说明。
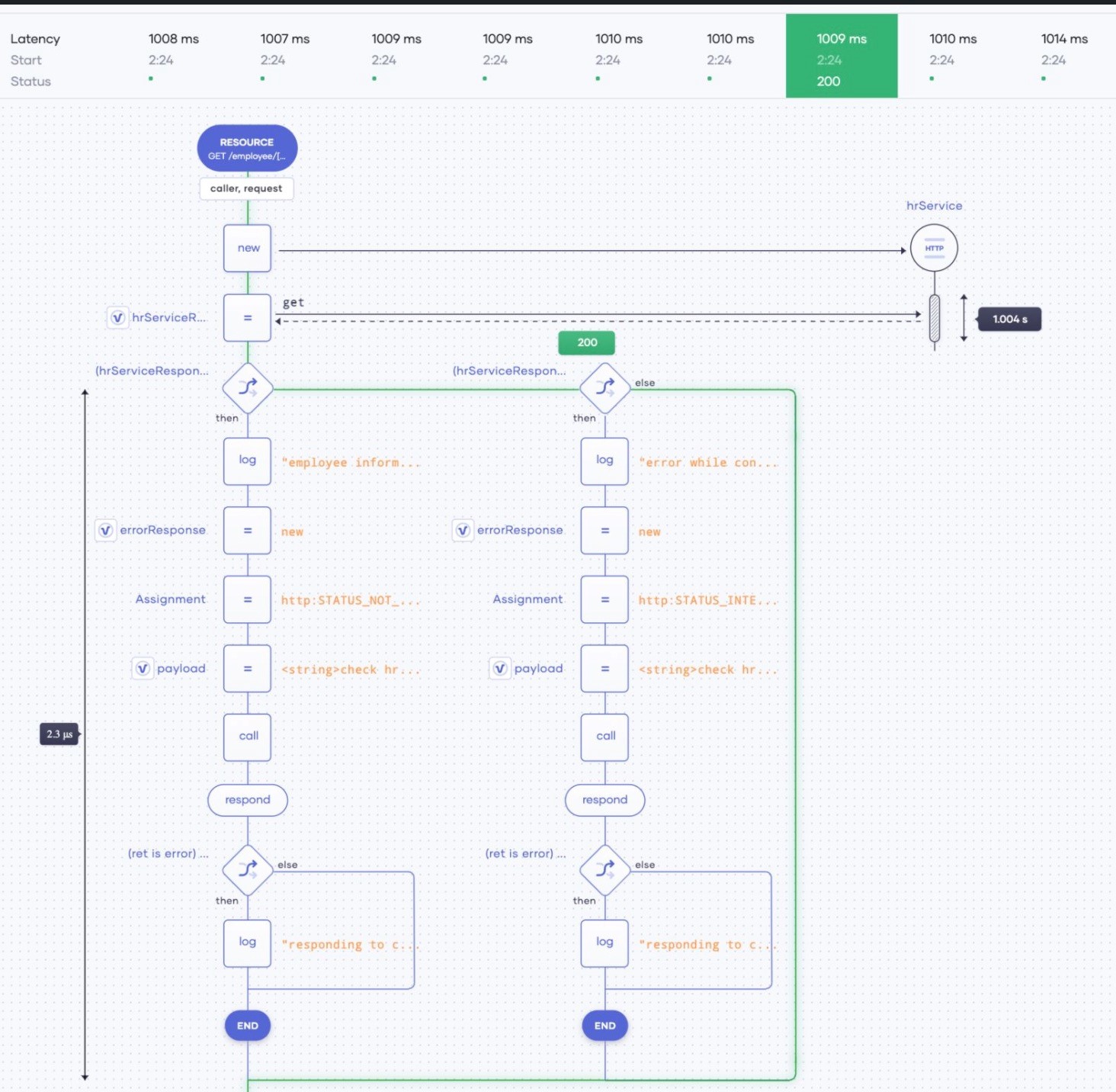
图4 查看请求在请求路径中花费时间最多的位置
(3)调试复杂问题
虽然可以通过分析延迟数据来解决大量问题(例如后端缓慢),但有些问题需要更详细的分析。此类分析要求在统一视图中查看多个指标和日志。这些指标包括系统指标(例如CPU和内存)和应用指标(例如吞吐量、延迟和错误率)。Choreo的诊断视图有助于实现这一点。它允许开发人员深入和调试诸如高CPU使用率之类的行为,并将高CPU使用率与另一个性能指标的变化(例如延迟的增加)联系起来。图5显示了Choreo可观察性的诊断视图。
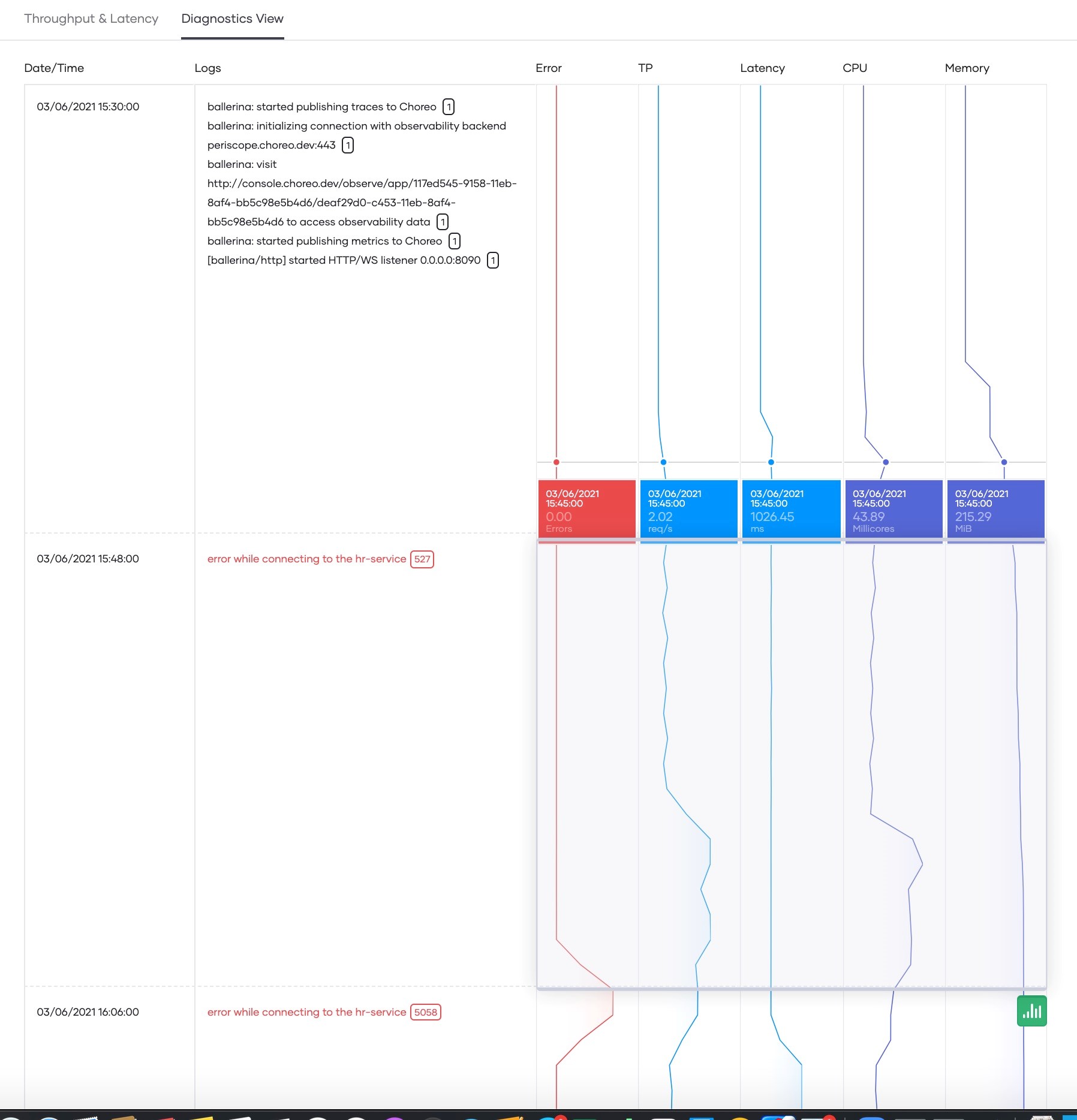
图5 Choreo可观察性的诊断视图
(4)在配置较低环境中调试
由于引入新功能和错误修复等各种原因,开发人员经常需要编写新代码或修改现有代码。在发生这种情况时,可能会将与性能相关的错误引入应用程序。Choreo允许在配置较低的环境中及早发现此类问题。开发人员可以在配置较低的环境中测试他们的应用程序,并将其性能行为与以前版本的性能行为进行比较。如果发现问题,可以在新版本部署到生产中之前解决这些问题。即使是全新的应用程序,开发者仍然可以通过提供示例的测试数据/案例在配置较低的环境中测试应用程序。
(5)性能异常警报
持续监控可观察性仪表板以识别应用程序中的异常行为是不切实际的。因此,很多系统都有自动检测性能异常并提醒相关方的方法。许多警报系统使用基于阈值的方法向用户发送警报。例如,如果CPU利用率高于80%,则会生成并发出警报。基于阈值的方法具有已知的局限性。首先,它们在确定阈值时需要人工配置和专业知识。其次,基于阈值的方法由于无法检测应用程序中的复杂异常模式而具有较低的准确性。
Choreo拥有复杂的异常检测框架,该框架使用先进的机器学习和异常检测算法来检测Choreo用户应用程序中的性能异常。它使用从以前的应用程序收集的可观察性数据来训练这些机器学习模型。
结语
虽然服务网格试图通过收集服务可观察性数据的Sidecar微服务提供可观察性的解决方案,但默认情况下通过这些Sidecar收集的数据不足以执行云原生应用程序的深度调试。这种调试需要在服务内更细粒度的级别收集数据(例如,在服务内的不同点对特定请求的延迟进行细分)。
Choreo拥有一个强大的可观察性框架,可以解决服务网格中的问题。Choreo还收集了其应用程序的所有三个可观察性支柱,而对应用程序性能的影响最小。它以一种可以轻松调试和检测应用程序性能异常的形式向用户呈现这些数据。此外,Choreo拥有先进的基于机器学习的异常检测技术,可以准确检测Choreo应用程序的性能异常。
原文标题:Observability: Let Your IDE Debug for You,作者:Malith Jayasinghe
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】