












让我们来讨论一下如何配置Python应用程序,特别是那些可能存在于多个环境中的应用程序——开发环境、模拟环境、生产环境等等……
应用程序中使用的工具和框架并不是特别重要,因为我将在下面概述的方法是基于普通Python的。这种方法的出现是由于使用Django设置会令人懊恼,此外,这种方法还是我将要处理的任何Python应用程序的首选。
概述:Python模块和包
我最喜欢的Python特性之一是,构成你应用程序的文件和目录与你在代码中导入和使用它们的方式是一一对应的。
例如,给定这个import语句:

我们可以推断出以下目录结构:

许多语言和框架都依赖于这个新概念,包括Clojure和ES6。
在我们的示例中,Python将utils目录视为一个Package。当你在一个目录中放置一个空的__init__.py时,该目录就变成了一个包。
作为一名Python黑客,你可能会遇到这样一个常见的场景,其中有一个utils.py文件最终会变得太大,因此你将它拆分成一个包含许多较小文件的utils//目录。
当遇到这种情况时,我们可以做以下事情:

所以现在我们已经看到了一个Python包是由一个目录中是否存在一个__init__.py文件决定的…但是如果这个文件不是空的呢?
在__init__.py中放入代码
由于它只是一个普通的旧Python文件,你可以把任何你想要的东西放在其中,该文件会在第一次导入包时被执行。
>>>旁注
通常我们不赞成将代码放在__init__.py中,因为它会在导入时带来意想不到的副作用。
你可以自己测试一下。创建一个名为foo的目录,并给它一个空的__init__.py文件。
从相同目录中的Python REPL运行以下代码:

这里没有输出是很好的,这意味着语句成功运行。
现在让我们编辑我们的__init__.py文件以包含以下代码:

sys.exit()通常用于使一个进程以特定的状态退出。
在一个新的REPL中重新运行相同的实验,你将观察到你的Python shell在导入之后会立即退出。在更大的应用程序中,效果会更明显:整个应用程序将退出。
这样,我们了解了基本原理,并了解了如何恶意使用此功能。
也许我们可以用它来做好事?
多个环境&十二因素应用程序
你的应用程序可能存在于多个环境中。你的本地开发环境可能是第一个,并且你可能有一个位于Jenkins或另一个CI平台上的测试环境。你的代码被部署到一个生产或活动环境中。一些系统可能有一个模拟环境,在实际运行之前使用。
即使你只认为自己是一个业余爱好者,在本地开发代码并将其部署到一个vps或类Heroku平台上也意味着你要处理多个环境。
我在构建应用程序时遵循的一个规则是,我应该能够将代码库部署到任何环境中(无需修改),前提是我们有办法告诉系统它在哪里运行。
与此相比,为每个部署目标构建多个部件,需要额外的时间和复杂性来构建和保持。这些部件通常被设计为在单一目标环境中运行,因此在本地或测试模式中运行它们通常是困难的或不可能的。
著名的十二因素方法论也认同这一观点,并且认为所有配置都应该作为环境变量存在。我在一定程度上同意这一点,但有时有一种趋势,就是把所有东西都变成一个环境变量,很快就会变得难以支持。
如果你的系统的每个旋钮和刻度盘都是一个环境变量,那么你将发现,你最终会将各种变量的组合存储在某个地方,以便运行或调试。在这里看到问题了吗?我们将配置从一个区域(代码,通常保存在版本控制中)移出,并将它们移到更容易出现错误和人为错误的区域。
我用来划定界限的一般准则:
- 不经常更改的静态内容,或者显著影响系统行为的内容应该存在于代码中。
- 频繁更改的动态内容或应该保密的内容(API键/凭据)应该存在于代码之外。
我们如何切换环境?
为了让应用程序在不同环境之间改变其行为,我们需要一种方法来告诉它,它正在哪里运行。依赖于环境变量(看到模式了吗?),我倾向于使用ENV(或变体)来实现此目的。
- Ruby/Rails生态系统使用RACK_ENV或RAILS_ENV
- Javascript项目通常会利用NODE_ENV
>>>旁注
在改变底层框架或工具的运行时行为的标志与特定应用程序的操作模式的标志之间划一条线是很重要的。例如,有时一个简单的DEBUG=True/False并不够好。
我最近为一个客户完成一个带有以下约定的项目:
- 我的本地开发环境没有设置一个ENV变量,因此系统默认情况下会推断开发环境。
- AWS CodePipeline上的测试环境使用ENV=test
- EC2上的生产环境使用ENV=production
注意:考虑不设置这个变量的后果是很重要的。这会是灾难性的吗?例如,应用程序能否在生产集群内部以DEV模式启动,并最终向公众显示回溯信息?对于某些应用程序,默认设置应该是production。这里没有正确或错误的答案,但它需要被考虑。
最终的目标
从开发者的角度来看,我们想要像这样访问我们的配置:

上面的导入行不包含任何能提示我们所处环境的内容。我们在任何地方都没有看到development或production这样的词。相反,我们只导入了我们需要的,并允许配置系统来决定它来自何处。
我们利用文件系统和语言本身来提供一个用于读取配置的API。
在幕后,这是config目录在磁盘上的样子:
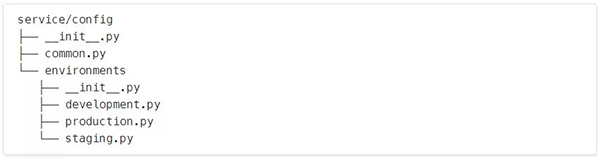
- common.py包含我们所有的公共或共享配置。这些东西在不同的环境中并没有太大的不同。你可以称其为base或shared配置,如果你愿意。
- environments/development.py包含开发配置。该文件可以排除在版本控制之外,这样团队中的每个开发人员都可以实现自己的配置设置。
- environments/(production|staging).py包含每个环境特有的配置。
让我们来看看common.py:

这是一个人为的例子,所以请不要太深入地了解细节。需要注意的是,这是一个相当静态的配置,不会经常改变。
现在让我们来看看environment/development.py:
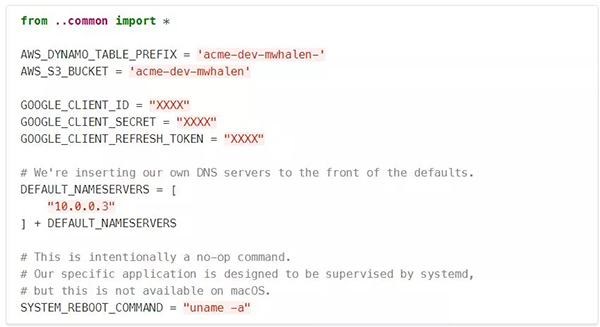
- 我们首先导入common配置,以便在默认情况下继承所有公共配置。现在我们可以添加、替换或增加参数,而不需要从父配置进行复制粘贴。
- 为了支持本地开发, 我可以自定义在我的环境中使用的AWS资源。系统的其余部分没有改变,但是现在我的本地系统使用我自己的Dynamo表和S3 bucket。
- 因为该文件不在版本控制中,所以我可以放心地存储机密信息,比如我自己的GOOGLE_CLIENT_ credentials。
- 因为可以访问公共的DEFAULT_NAMESERVERS,所以我可以扩展它们,而不是复制粘贴任何公共值到我自己的配置中。
- 在生产环境中,systemd命令用于在响应某些管理操作时重新启动应用程序。因为我的Mac没有systemd,所以我用一个简单的no-op替换了system reboot命令,从而完全避免了这个问题。
它是如何工作的
回到我们的config/__init__.py文件,我们可以在这里实现什么来实现它呢?其实很简单:

我们正在利用import-time evaluation来动态地从相应的子环境中获取必要的配置。让我们一步一步来:
1. 首先,我们导入importlib模块(文档),它为我们提供了一些用代码导入代码的方便工具。
2. 使用我们建立的约定—ENV环境变量—我们获取当前运行的环境的名称。
3. 如果没有设置环境,我们就选择development作为默认设置,但是如前所述,这个决定将根据系统的不同而有所不同。
我们甚至可以考虑阻止应用程序启动,除非定义了这个变量。下面是一个这样的例子:

4. 接下来我们使用importlib.import_module函数将包含特定环境代码的模块加载到局部变量module中。
5. 最后,我们更新这个模块的globals,将development.py文件中设置合并到其中。
6. 最终,你将看到一些便利的工具(a-la Rails),使基于环境切换具体的逻辑变得更加容易。它们作为函数保存,以便将实现隔离到此模块,而不是隔离到使用它的任何地方。
这种方法深受Ruby on Rails配置的启发,它实现了一个非常相似的外观,只是底层实现有所不同。
一个真实的例子
为了提供另一个实际的例子,以下是本网站的配置:
首先,这是我的config目录的确切目录结构:
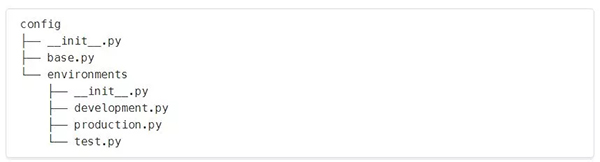
- development.py在本地使用
- production.py用于Heroku
- test.py用于带有pytest的本地单元测试
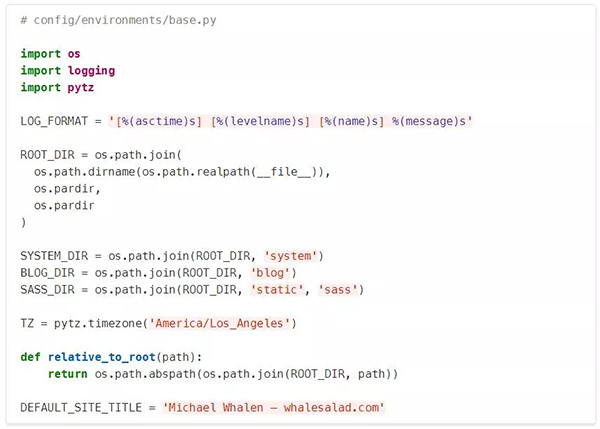
base.py包含静态配置:
- 一个在项目的其他地方使用的集中式日志格式。
- 通用目录和一个使路径相关的工作更容易的助手函数。
- 我的服务的时区。
- 当页面不提供自己的标题时使用的默认标题。
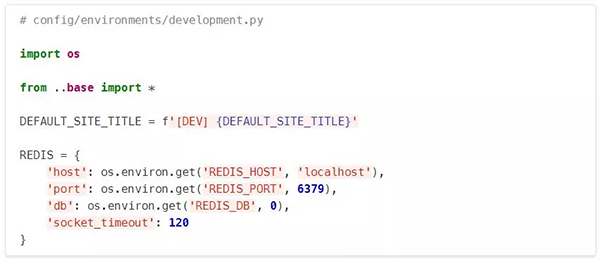
在development.py中,站点标题会被覆盖,这样,当我在编辑的时候,我就知道我正在查看的是一个本地副本。我还定义了一些本地的Redis配置,它们与Production有很大的不同。
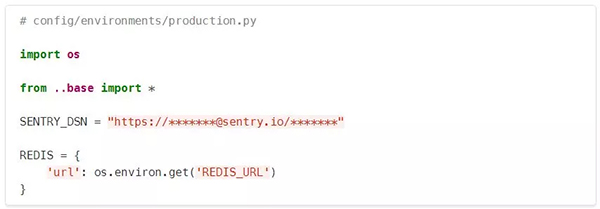
- SENTRY_DSN只在production.py中被定义,而没有在base或其他环境中定义。这是为了防止Sentry(集中式错误日志)在开发或测试情况下被激活。
- 在Heroku上,Redis连接细节来自一个URL,因此我们在这里进行了配置。
最后,为了演示如何在应用程序的其他地方使用这个设置,我们来看看Redis连接是如何建立的:
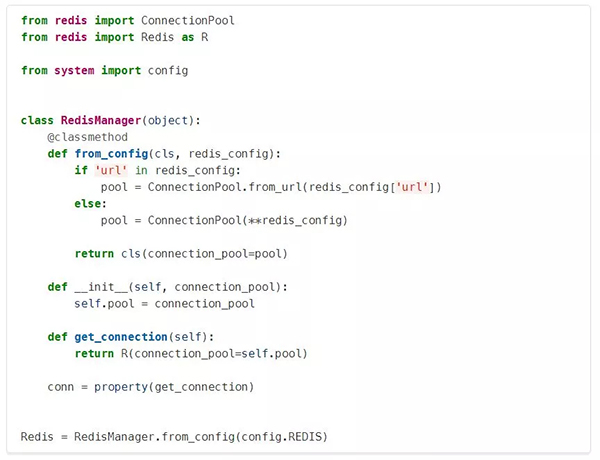
注意最后一行:RedisManager.from_config()用于隔离关注点。RedisManager的其余部分不知道config中的数据是什么样子的,也不需要知道。这是配置层和系统其余部分之间的一个切换点。
结论
我在所有的Python项目中都使用了这种方法,但还没有发现这种方法(或其变体)不起作用的情况。
- 我们有创造无限数量环境的灵活性。例如,如果我们想为一个拉取请求启动一个临时环境:我们只需要使用“cp environments/staging.py environments/PR_402.py and ENV=PR_402”就可以了。
- 当在本地进行开发时,我们可以在生产模式下运行系统,方法是在它前面加上ENV=production,反之亦然,我们也可以在开发或测试模式下在其他任何地方运行软件。
- 开发人员可以通过查看每个环境被覆盖的配置来快速收集每个环境之间的主要差异。这使得将新的团队成员加入到你的代码库中变得更加容易。
- 类似地,团队中的每个开发人员都可以有自己独特的配置。这不会过多地影响中心配置,因为你的系统有一些不同于其他系统的设置。
- 我们可以通过显式地将environments/test.py 中的某些变量设置为None来保护我们的测试环境,以避免意外地访问生产环境资源。
- 我们消除了在各种CLI工具(如Docker等等)之间传递较大键/值配置映射的负担(尽管现在的工具越来越能够从文件中读取env)
- 我们将我们的配置公开为一个普通的Python包,因此与其他Python工具几乎没有学习曲线和互操作性问题。
- 我们避免了支持外部库/依赖项所需要的成本。
总而言之,这种方法并不是很吸引人,而这正是我们在构建可靠、可维护和高效的系统时所想要的。使用一些简单的旧Python和几行特殊代码,我们就已经在我们的系统配置中释放了大量的灵活性和强大功能。










