













昨天有位同学在公众号俱乐部群问了这样一个问题:

他在一个 Scrapy 项目里面,有两个爬虫 A 和 B,他使用命令scrapy crawl B想启动 B 爬虫,但是发现 A 爬虫也自动运行了。
然后,这个同学贴上来他的爬虫代码:

看到这个代码,我就知道是怎么回事了。要解释这个现象,我们需要掌握两个知识点:
Scrapy 是怎么加载爬虫的?
Python 的类变量与实例变量的区别。
Scrapy 是怎么加载爬虫的?
我们知道,Scrapy 的 spiders 文件夹里面,可以定义很多个爬虫文件。只要每个爬虫文件的 name 的值不一样,那么,我们就可以使用scrapy crawl name 的值来启动特定的爬虫。
那么,Scrapy 它是怎么根据这个名字找到对应的类的呢?
实际上,在我们执行scrapy crawl xxx的时候,Scrapy 有几个主要的步骤:
- 首先遍历spiders 文件夹下面的所有文件,在这些文件里面,寻找继承了scrapy.Spider的类
- 获取每个爬虫类的name属性的值
- 添加到一个公共的字典里面{'name1': 爬虫类1, 'name2': '爬虫类2'}
- 获取scrapy crawl xxx具体要启动的那个爬虫的名字,从公共字典里面,找到这个名字对应的爬虫类
- 执行这个爬虫类,得到一个爬虫对象。然后调用爬虫对象的start_requests()方法
从这个过程我们可以知道,spiders 文件夹下面,每一个爬虫类都会被加载。
Python 的类属性和实例属性
在我们定义Python 类的时候,我们其实可以在类里面,所有方法的外面写代码,例如:
- class Test:
- a = 1 + 1
- b = 2 + 2
- if a + b == 6:
- right = True
- else:
- right = False
- def __init__(self):
- self.age = 100
- self.address = '上海'
大家注意这几行代码:
- a = 1 + 1
- b = 2 + 2
- if a + b == 6:
- right = True
- else:
- right = False
他们不在任何方法里面的,这里面初始化的变量,叫做类变量或者类属性。而在__init__里面,初始化的self.age和self.address叫做实例属性。
实例属性只有在类被执行的时候,获得实例对象的时候,才会执行。而类属性,是在类被 Python 加载的时候,就会执行。大家注意下面这段代码:

Python 只是加载了这个类,并没有初始化它,但里面的 print语句已经执行了。
而当我们初始化它以后,实例属性才会执行:
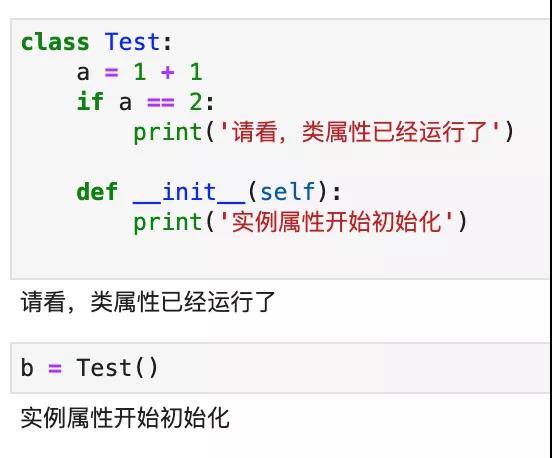
什么情况叫做Python 加载了一个类呢?
例如,当你from xxx import yyy的时候,yyy这个类就被加载了。又比如你可能是使用imortlib.import_module的时候。
所以,回到这个同学的问题。之所以他其中一个爬虫的代码始终会运行,原因就在下面红色圆圈中的代码:

他把这段代码写在了所有方法之外,让他处于了类属性的区域。在这个区域里面的代码,在爬虫类被加载的时候,就会执行。
如果要解决这个问题,只需要把这段代码,放到start_requests()方法里面就可以了。
本文转载自微信公众号「未闻Code」,可以通过以下二维码关注。转载本文请联系未闻Code公众号。























