一、Python 生态的重要性
Why Python
Python has grown to become the dominant language both in data analytics, and general programming。
根据技术问答网站stack overflow统计,Python、C#、Javascript、java、php、C++、SQL、R、statistics这些编程语言从2009年至2021年的趋势图如下图所示。可以看出Python的趋势是呈现上涨趋势,特别是在数据分析和数据科学领域,几乎是top one的编程语言。这是Python生态的发展趋势。当然,在数据分析数据科学机器学习这个领域,不只是有编程语言这一个因素。
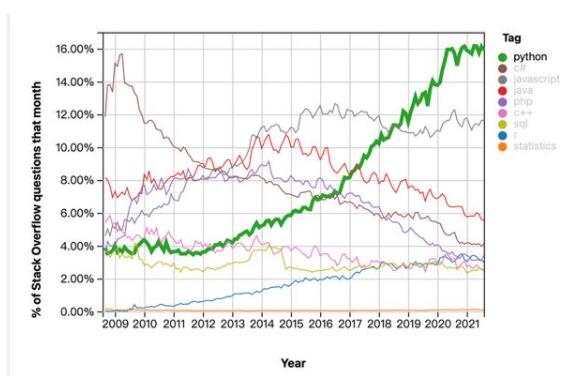
统计来自 https://insights.stackoverflow.com/trends
数据科学技术栈
在数据科学领域编程语言只是一个方面,语言不止包含Python,也有数据分析人员用SQL,或者传统分析语言R,或者是函数式编程语言Scala。第二个方面需要有数据分析对应的库,比如NumPy、pandas等,或者是基于可视化的库会在里面。Python运行的集群还会有一些运维的技术栈在里面,比如可以运行在docker或者是kubernetes上。如果要做数据分析数据科学,前期需要对数据进行清洗,有一些ETL的过程。有一些清洗不只是一两步能完成的,需要用工作流去完成整体的ETL的过程。里面涉及到最流行的组件比如Spark,整个工作流调度Airflow,最终结果做一个呈现,就需要存储,一般用PostgreSQL数据库或者内存数据库redis,对外再连接一个BI工具,做最终结果的展示。还有比如机器学习的一些组件或者平台,TensorFlow、PyTorch等。如果是设计到Web开发,快速搭建起一个前端平台,还会用的比如Flask等。最后包括一个商业智能的软件,比如有BI工具tableau、Power BI,或者是数据科学领域经常用到的软件SaaS。
这就是整个数据科学技术栈比较完整的一个视图。我们从编程语言切入,发现如果要实现大规模数据的数据科学是需要方方面面的考量。

二、MaxCompute 分布式 Python 能力介绍
MaxCompute 分布式 Python 技术 - PyODPS
MaxCompute是一款SaaS模式的云数据仓库,基于MaxCompute是有兼容Python的能力。
PyODPS 是 MaxCompute 的 Python 版本的 SDK, 它提供了对 MaxCompute 对象的基本操作;并提供了 DataFrame 框架(二维表结构,可以进行增删改查操作),能在 MaxCompute 上进行数据分析。
PyODPS 提交的 SQL 以及 DataFrame作业都会转换成 MaxCompute SQL 分布式运行;如果第三方库,能以 UDF+SQL 的形式运行,也可以分布式运行。
如果需要 Python 把作业拆成子任务分布式来运行,比如大规模的向量计算原生 Python 没有分布式能力,这时候推荐用 MaxCompute Mars。是可以把Python任务拆分成子任务进行运行的框架。
自定义函数中使用三方包
假如不是单纯运行Python,需要借助一些Python第三方包,这个MaxCompute也是支持的。
流程如下:
Step1
确定使用到的第三方包
sklearn,scipy
Step2
找到对应报的所有依赖
sklearn,scipy,pytz,pandas,six,python-dateutil
Step3
下载对应的三方包(pypi)
python-dateutil-2.6.0.zip,
pytz-2017.2.zip, six-1.11.0.tar.gz,
pandas-0.20.2-cp27-cp27m-manylinux1_x86_64.zip,
scipy-0.19.0-cp27-cp27m-manylinux1_x86_64.zip,
scikit_learn-0.18.1-cp27-cp27m-manylinux1_x86_64.zip
Step4
上传资源变成MaxCompute的一个Resource对象。
这样我们去创建函数,再引用自定义函数,就能够使用到第三方包。
自定义函数代码
- def test(x): from sklearn import datasets, svm from scipy import misc import numpy as np iris = datasets.load_iris() clf = svm.LinearSVC() clf.fit(iris.data, iris.target) pred = clf.predict([[5.0, 3.6, 1.3, 0.25]]) assert pred[0] == 0 assert misc.face().shape is not None return x
MaxCompute 分布式 Python 技术 - Mars
项目名字 Mars
最早是 MatrixandArray;登陆火星
为什么要做 Mars
为大规模科学计算设计的:大数据引擎编程接口对科学计算不太友好,框架设计不是为科学计算模型考虑的
传统科学计算基于单机,大规模科学计算需要用到超算
Tips科学计算:计算机梳理数据: Excel-> 数据库 (MySQL)-> Hadoop, Spark, MaxCompute 数据量有 了很大变化,计算模型没有变化,二维表,投影、切片、聚合、筛选和排序,基于关系代数,集合论;科学计算基础结构不是二维表:例如图片2维度,每个像素点不是一个数字(RGB+α 透明通道)
传统 SQL 模型处理能力不足:线性代数,行列式的相乘,现有数据库效率低
现状 R,Numpy 单机基于单机; Python 生态的 Dask 大数据到科学计算的桥梁
案例
客户A MaxCompute 现有数据,需要针对这些 百亿数据 TB 级别的数据相乘;现有 MapReduce 模式性能低;用 Mars 就可以高效的解决;目前是唯一一个大规模科学计算引擎
加速数据科学的新方式
加速数据科学的方式如下图所示。
基于DASK或者是 MaxCompute Mars其实是 Scale up 和 Scale out 兼容的方式。在下图左下代表单机运行Python 的库做数据科学的一个方式。大规模超算的思路是Scale up,也就是线上垂直扩散,增加硬件能力,比如可以利用多核,当前每台电脑或服务器上不止一核,包括GPU、TPU、NPU等做深度学习的硬件。可以把Python移植到这些硬件上做一些加速。这里的技术包含比如Modin是做多核加速pandas。在右下,也有一些框架在做分布式Python,比如RAY是蚂蚁的一款框架服务,本质上Mars是可以运行在RAY上,相当于Python生态的一个调度,一个kubernetes。DASK也是在做分布式Python,包括Mars。当然,最佳的模式是 Scale up 和 Scale out 两种做一个组合。这样的好处是,可以做分布式,在单节点上也可以利用硬件能力。Mars当前只能在大规模集群上,单机配置在GPU集群。
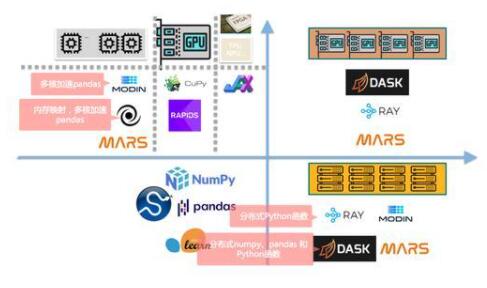
分布 Python 的设计逻辑
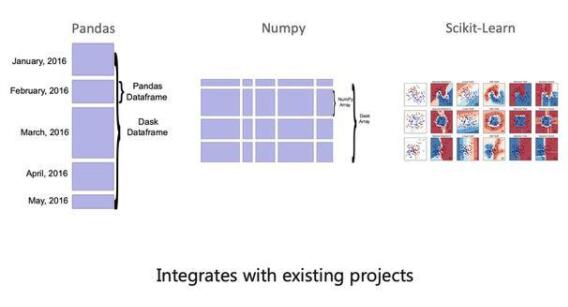
Mars本质上设计思路是把数据科学库分布式化掉,比如Python,可以把Dataframe做一个拆分,包括Numpy,Scikit-Learn。
把大规模作业拆分成小作业来做分布式计算。本身框架就是拆成作业用的,首先客户端提交一个作业,Mars框架把作业拆分,做一个DAG图,最后汇总收集计算结果。
Mars 场景1 CPU和GPU混合计算
1、安全和金融领域,传统大数据平台挖掘周期长,资源紧张,等待周期长。
2、Mars DataFrame加速数据处理:大规模排序;统计;聚合分析。
3、Mars learn 加速无监督学习;Mars拉起分布式深度学习计算。
4、 使用 GPU 加速特定计算。
Mars 场景2 可解释性计算
1、广告归因&洞察特征的解释算法,本身计算量巨大,耗时长。
2、使用 Mars Remote 将计算用数十台服务器进行加速,提升百倍性能。
Mars场景3 大规模k-最邻近算法
1、Embedding 的流行使得用向量表述实体非常常见。
2、Mars 的NearestNeighbors算法兼容 scikit-learn。暴力算法在300万向量和300万向量计算top10相似计算(9万亿次向量比对)中,用20个worker两个小时计算完成,大数据平台基于SQL+UDF的方式无法完成计算。更小规模 Mars 相比大数据平台性能提升百倍。
3、Mars 支持分布式的方式加速Faiss、Proxima(阿里达摩院向量检索库),达到千万和亿级别规模。
三、最佳实践
Mars本身会集成一些Python第三方包,基本主流机器学习和深度学习的库都包含在里面。下方Demo讲一个使用Mars做智能推荐,用lightgbm做一个分类算法,比如有一些优惠判断是不是给某些用户做推送。
Mars 包括的第三方包:
https://pyodps.readthedocs.io/zh_CN/latest/mars-third-parties.html
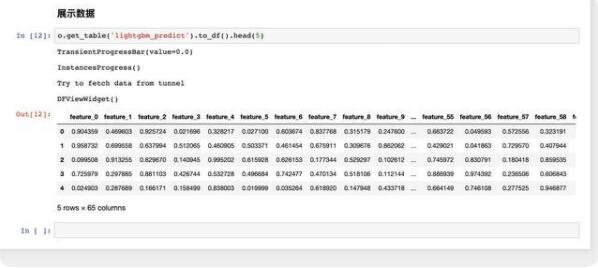
第一张图上主要步骤是通过 AK、project 名字、Endpoint 信息连接到 MaxCompute。接下来创建一个4节点,每个节点8 core,32G 的集群,应用 extended 扩展包,并生成 100w 用户 64维度描述信息的训练数据。
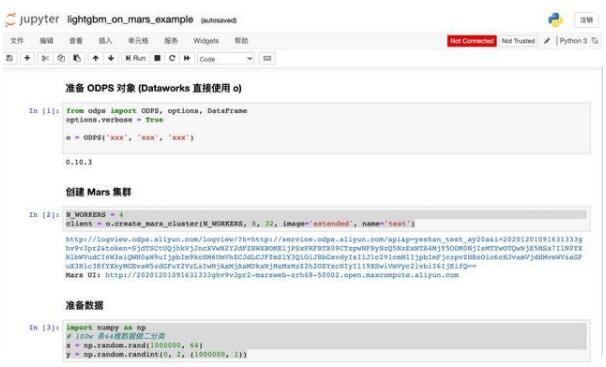
利用 Lightgbm 2分类算法的模型训练:
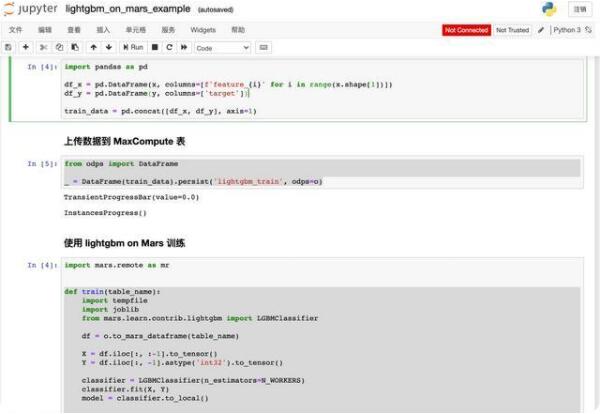
将模型以 Create resource 方式传到 MaxCompute 作为 resource 对象,准备测试集数据

使用测试测试集数据验证模型,得出分类: