












北京航空航天大学、商汤科技、京东探索研究院等
来自北航、商汤科技和京东探索研究院等机构的研究者提出了第一个在大规模数据集 ImageNet 上面向模型结构和训练技巧且针对多种噪音类型的模型鲁棒性评测基准——RobustART。该 benchmark 全面评测了 44 种经典的手工设计和 1200 种 NAS 采样得到的模型架构以及 10 余种模型训练技巧对于鲁棒性的影响。
以深度学习为代表的人工智能技术,在计算机视觉、语音识别、自然语言处理等方向上已经取得了巨大进展,在我们生活中的多个领域得到了广泛的应用并发挥了极其关键的作用。然而,由于现实应用场景的开放性,以大数据训练和经验性规则为基础的传统人工智能(如深度学习)方法面临着输入样本含有噪音的挑战,如:自然噪音、对抗噪音等。这些微小的噪音对于深度学习模型的鲁棒性和安全性产生了很大的挑战,其对于社会稳定甚至是公共安全都可能产生极大的影响。
哪种模型对于噪音更加鲁棒?哪些模型架构和组件对于噪音有更强的抵御能力?对于这些问题的研究能够帮助我们更好地认识和理解模型鲁棒性的本质,从而帮助研究人员进行更加鲁棒的模型架构设计。进一步,这对于推进工业级鲁棒模型的评测和落地应用、并最终服务于国家相关智能模型鲁棒评测标准的推进和开展具有十分重大的意义!因此,来自北京航空航天大学、商汤科技和京东探索研究院的研究人员联合加州大学伯克利分校、牛津大学以及约翰斯 · 霍普金斯大学提出了第一个在大规模数据集 ImageNet 上面向模型结构(ARchitecture Design)和训练技巧(Training Technique)且针对多种噪音类型的模型鲁棒性评测基准——RobustART。
该 benchmark 全面评测了 44 种经典的手工设计和 1200 种 NAS 采样得到的模型架构以及 10 余种模型训练技巧对于鲁棒性(对抗噪音、自然噪音、系统噪音等)的影响。并通过海量且深入的实验探究,得出了大量的有价值实验结果和众多启发性的结论,如:
(1)对于 Transformer 和 MLP-Mixer,对抗训练可以全面提升其全部噪音鲁棒性和任务本身的效果;
(2)在模型大小一致的前提下,对于自然噪音和系统噪音鲁棒性:CNN>Transformer>MLP-Mixer,对于对抗噪音鲁棒性,Transformer>MLP-Mixer>CNN;
(3)对于一些轻量化的模型族,增加其模型大小或者增加训练数据并不能提升其鲁棒性等。这些分析和结论将对人们认识模型鲁棒性机理并设计安全稳固的模型架构产生重要的意义。
RobustART benchmark(1)提供了一个包含 leaderboard、数据集、源码等详实信息在内的开源平台;(2)开放了 80 余种使用不同模型结构和训练技巧的预训练模型,以便于研究人员进行鲁棒性评估;(3)贡献了崭新的视角和大量的分析结论,让研究人员更好地理解鲁棒模型背后的内在机制。
RobustART 将作为核心组成部分,整合到北航团队先前研发的人工智能算法与模型安全评测环境「重明」 系统当中,并发布「重明」2.0 版本(「重明」 是国内领先的智能安全评测环境,曾受邀在国家新一代人工智能开源社区 OpenI 启智开源开放平台发布,并荣获 OpenI 社区优秀开源项目)。在未来,RobustART 将持续为整个社区提供更加完善、易用的开源鲁棒性评估和研究框架。同时也将助力于工业级模型的评测和鲁棒模型的落地应用,最终也希望能够服务于国家相关智能模型鲁棒评测标准的推进和任务的开展。

- 论文地址:https://arxiv.org/pdf/2109.05211.pdf
- RobustART 开源平台网址:http://robust.art/
- 重明平台网址:https://github.com/DIG-Beihang/AISafety
一、概要
目前的鲁棒性 benchmark 主要聚焦于评估对抗防御方法的效果,而忽略了模型结构和训练技巧对于鲁棒性的影响。而这些因素对模型鲁棒性十分重要,一些细微的差别(如训练使用的数据增强方法的不同)就可能掩盖防御方法带来的鲁棒性影响,从而造成对模型鲁棒性的错误评估和认识。因此,该论文提出了 RobustART 来全面地评测不同模型结构和训练技巧对于鲁棒性的影响,并在对抗噪音(AutoAttack、PGD 等)、自然噪音(如 ImageNet-A, -O, -C, -P)和系统噪音(如 ImageNet-S)下进行了全面评估。下表给出了在研究的 44 种经典网络模型中,在不同噪音下鲁棒性前五名的模型(为了公平比较,所有模型的训练设置都已对齐):

二、考虑模型结构和训练技巧的鲁棒性 benchmark
为了更好地探究模型鲁棒性的内在本质,该研究将影响模型鲁棒性的原因划分成模型结构和训练技巧这两个正交因素,进而构建了一套完整的 benchmark 设置,即(1)对不同网络结构的模型,使用同样的训练技巧进行训练(2)对于同一种网络结构的模型,使用不同的训练技巧进行训练。这种细分的消融研究更有助于人们理解某些具体的模型结构或者训练技巧对于鲁棒性的影响。下表分别展示了研究中用到的模型结构、训练技巧、以及噪音类型。

针对模型结构这一因素,该研究尽可能多地覆盖了常用的神经网络模型。对于 CNNs,有经典的大型结构如 ResNet、ResNeXt、WideResNet、DenseNet;轻量化网络如 ShuffleNetV2、MobileNetV2;重参数化的结构 RepVGG;基于神经架构搜索(NAS)的模型如 RegNet、EfficientNet、MobileNetV3 以及使用 BigNAS 超网采样得到的子网络;对于非 CNN 网络,有 ViT 和 DeiT,以及最近的基于 MLP 结构的 MLP-Mixer。总计 44 种典型的手工设计的网络模型和 1200 种超网采样出的子网模型,在实验中它们的训练设置都将被对齐。
针对训练技巧这一因素,该研究选取了较为主流的一些技巧进行探究,有知识蒸馏、自监督训练、权重平均、权重重参数化、标签平滑、Dropout、数据增强、大规模预训练、对抗训练、不同的优化器等。在实验中选取部分模型结构,通过比较使用某训练技巧进行训练和不使用该技巧训练对模型鲁棒性的影响来探究该训练技巧对鲁棒性起到的作用。
为了全面完整地对模型鲁棒性进行评估,该研究选用了三种不同类型的噪音来对模型进行测试:对抗噪音、自然噪音、系统噪音。其中,对于对抗噪音选用了 8 种主流的对抗攻击方法,覆盖了不同的攻击强度和黑白盒攻击:FGSM、PGD-
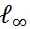
、AutoAttack-
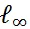
、
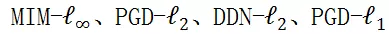
、以及基于迁移的对抗攻击;对于自然噪音选用了 4 种主流的数据集:ImageNet-C、ImageNet-P、ImageNet-A、ImageNet-O;对于系统噪音选用了 ImageNet-S 数据集。此外,对于每种噪音都选择了相应的评估指标进行测评。
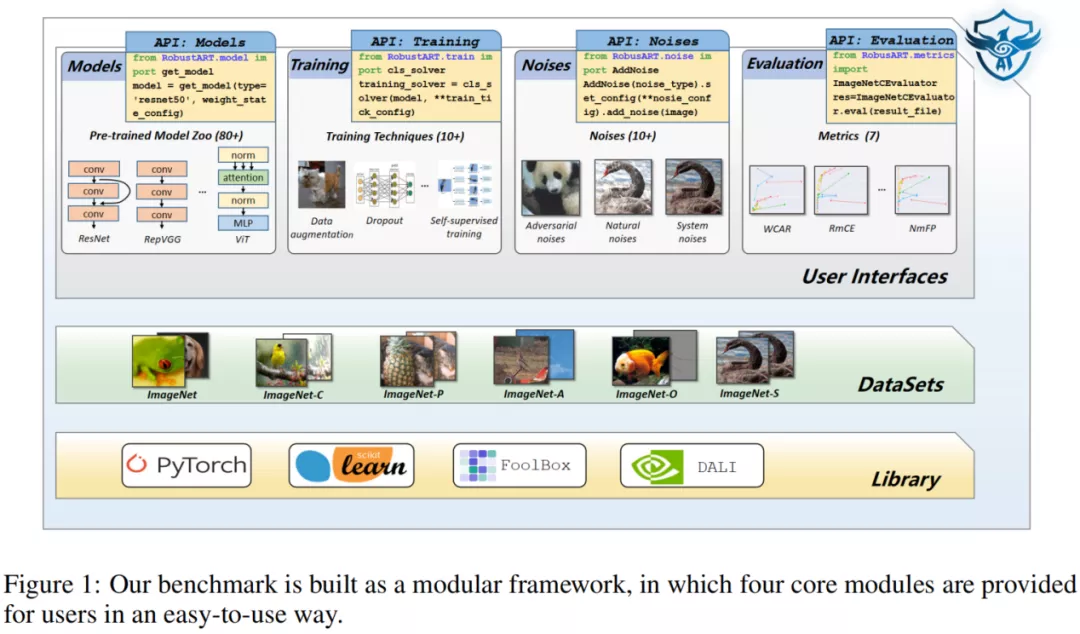
RobustART 整体采用了层次化和模块化的框架设计,如下图所示,底层使用了 Pytorch 作为深度学习框架,并使用了 FoolBox、ART 等对抗工具库,且提供了多种数据集的支持。用户接口层次主要分为 Models、Training、Noises、Evaluation 这四大模块,每个模块提供了可调用的 API 供用户使用。通过使用 RobustART 的开源框架,用户可以(1)方便地使用提供的代码复现结果以及进行更加深入的分析;(2)通过提供的 API 添加新模型、训练技巧、噪音、评估指标等来进行更多的实验;(3)使用提供的预训练模型和研究结果进行下游的应用或者作为比较的基线。
三、实验结果与分析
3.1 模型结构对于鲁棒性的影响
该研究首先选用了来自 13 个模型族的共 44 个典型的网络模型,使用对齐的实验设置对它们进行训练,然后对它们进行鲁棒性评估。下面两张图分别展示了所有模型在各种噪音下模型大小与鲁棒性的关系以及在面对迁移性对抗攻击时的热力图:
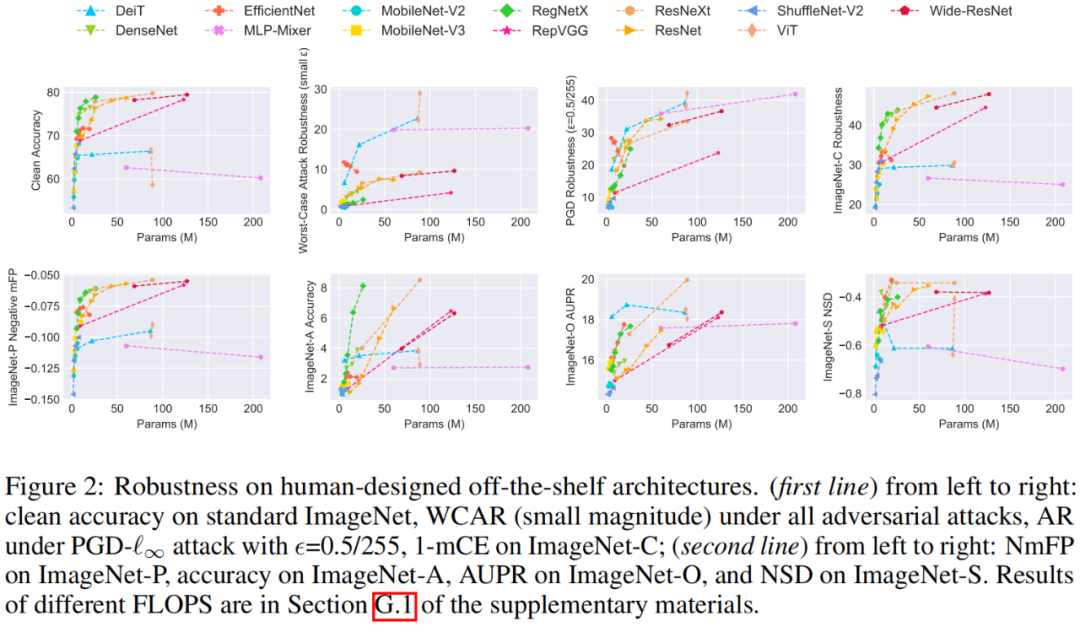
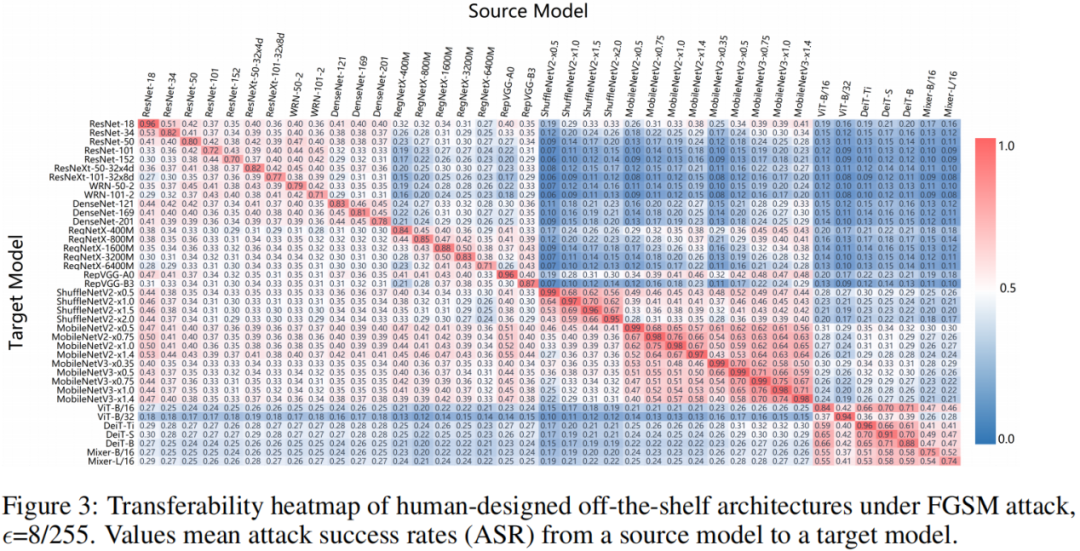
通过图中各模型间鲁棒性的对比,可以看到:
- 对于几乎所有模型族(除了 MobileNetV2 等轻量化的模型族),增大模型大小能够同时提高泛化性以及对于对抗、自然、以及系统噪音的鲁棒性。
- 在模型大小类似的情况下,不同的模型结构可能有着截然不同的鲁棒性,这也意味着模型结构对于鲁棒性是非常重要的。具体的,ViT、MLP-Mixer 这类非 CNN 的模型在对抗噪音下表现更为优秀,而传统的 CNN 模型(如 ResNet、ResNeXt)则对于自然噪音和系统噪音更加鲁棒。
- 不同的噪音对于最终鲁棒性的评估结果影响很大,对于同一类型的噪音(如对抗噪音),不同的攻击方法可能导致不同的模型鲁棒性结果;甚至对于同一种对抗攻击,不同的噪音大小也可能会导致鲁棒性评估结果的不同。
除了 44 个典型的网络模型,该研究还从 BigNAS 超网中采样了 1200 个子网,探究子网模型参数(如模型大小、输入图片大小、深度、卷积核大小等)对于鲁棒性的影响,如下图所示:
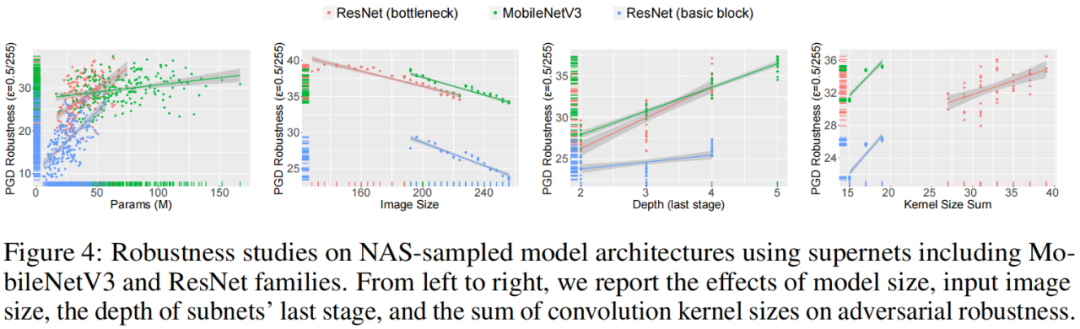
可以看出模型大小、卷积核大小、模型最后一个 stage 的深度对于对抗鲁棒性有着正向的影响,而输入图片的大小则对对抗鲁棒性有负面的影响。
3.2 训练技巧对于鲁棒性的影响
该研究针对 10 余种特定的训练技巧,选取部分模型来评估有 / 无这些技巧对于模型的鲁棒性影响,部分结果如下图所示:
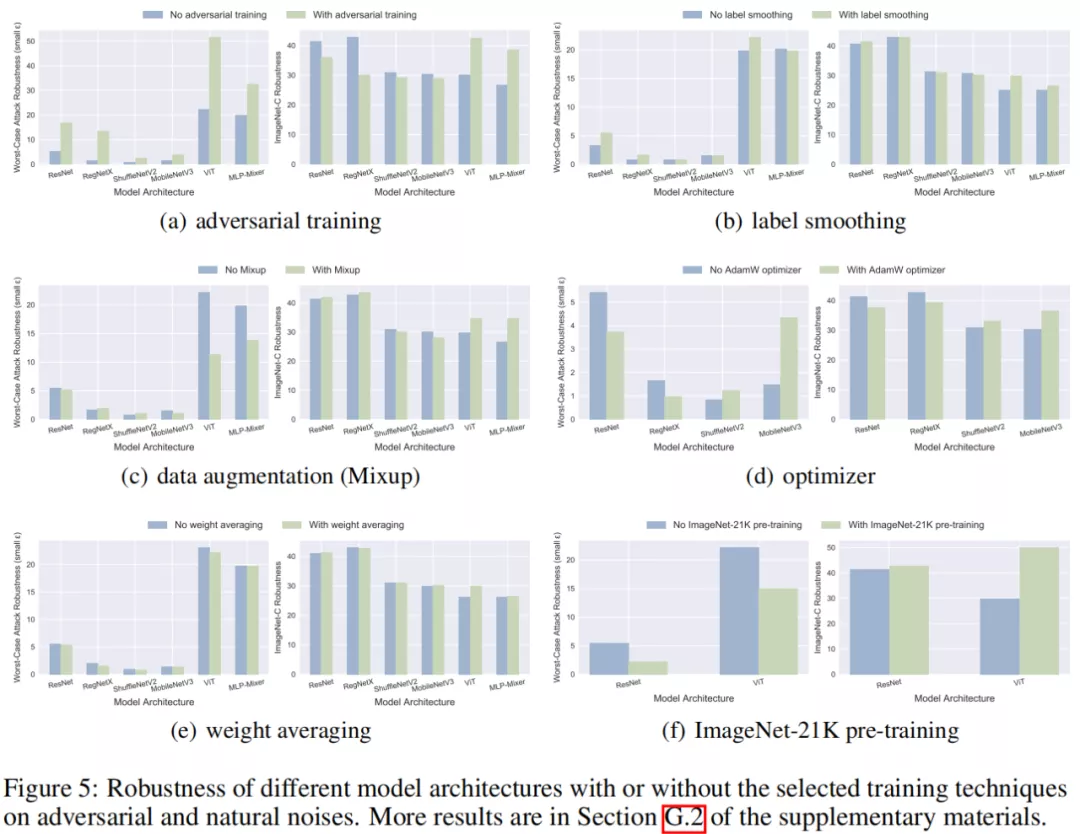
从实验结果可以得出较多有意义的结论,如:
- 对抗训练:对于 CNNs,对抗训练提升了模型的对抗鲁棒性,然而降低了 Clean 数据集上的泛化性以及对于自然噪音和系统噪音的鲁棒性;该研究还首次发现了对于 ViTs 和 MLP-Mixer,对抗训练显著提升了 Clean 数据集上的泛化性以及对于所有三种噪音的鲁棒性,这对于对抗训练在真实场景中的实际应用有重大意义。
- ImageNet-21K 预训练:该技巧提升了模型对于自然噪音的鲁棒性,却降低了对于对抗噪音和系统噪音的鲁棒性。
- 数据增强:该技巧降低了模型在对抗噪音上的鲁棒性,并在大多数情况下提升了模型对于自然噪音的鲁棒性。
- AdamW 优化器:相比于基础的 SGD 优化器,该技巧略微降低了 ResNet、RegNetX 等大型模型的鲁棒性,却明显提升了 MobileNetV3 和 ShuffleNetV2 等轻量化模型在 Clean 数据集上的泛化性以及对于所有三种噪音的鲁棒性。
四、展望
在深度学习模型大量应用于人脸识别、自动驾驶等关键领域的今天,人们越发意识到人工智能安全的重大意义,而人工智能安全相关的研究和标准也亟待进一步推进和落实。本研究所提出的 RobustART 为我们带来了一个全面、标准的模型鲁棒性评估的开源平台和框架,并在此基础上进行了大量的实验研究,得出了大量有启发性的结论。这将帮助我们进一步认识和理解模型鲁棒性与结构、训练技巧之间的关系,让我们对鲁棒性有了更加全面深入的认识。该研究将与现有的面向防御的鲁棒性 benchmark 互补,共同构建完善的鲁棒性基准,推动鲁棒性研究生态系统在机器学习社区中的长远发展。
























