前言:在 Serverless 架构下,虽然更多精力是关注业务代码,但是实际上对一些配置和成本也是需要关注的,并且必要的时候还需要根据配置与成本对 Serverless 应用进行配置和代码优化。
Serverless 应用开发观念的转变
Serverless 架构带来的除了一种新的架构、一种新的编程范式,还包括思路上的转变,尤其是开发过程中的一些思路转变。有人说要把 Serverless 架构看成一种天然的分布式架构,需要用分布式架构的思路去开发 Serverless 应用。诚然,这种说法是正确的。但是在一些情况下,Serverless 还有一些特性,所以要转变开发观念。
1、文件上传方法
在传统 Web 框架中,上传文件是非常简单和便捷的,例如 Python 的 Flask 框架:
f = request.files['file']f.save('my_file_path')
但是在 Serverless 架构下,文件却不能直接上传,原因如下:
一般情况下,一些云平台的API网关触发器会将二进制文件转换成字符串,不便直接获取和存储;
一般情况下,API 网关与 FaaS 平台之间传递的数据包有大小限制,很多平台限制数据包大小为 6MB 以内;
FaaS 平台大多是无状态的,即使存储到当前实例中,也会随着实例释放而使文件丢失。
所以,传统 Web 框架中常用的上传文件方案不太适合在 Serverless 架构中直接使用。在 Serverless 架构中,上传文件的方法通常有两种:一种是转换为 Base64 格式后上传,将文件持久化到对象存储或者 NAS 中,但 API 网关与 FaaS 平台之间传递的数据包有大小限制,所以此方法通常适用于上传头像等小文件的业务场景。
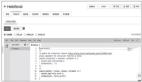
另一种上传方法是通过对象存储等平台来上传,因为客户端直接通过密钥等来将文件直传到对象存储是有一定风险的,所以通常是客户端发起上传请求,函数计算根据请求内容进行预签名操作,并将预签名地址返给客户端,客户端再使用指定的方法上传,上传完成之后,通过对象存储触发器等来对上传结果进行更新等,如下图所示。
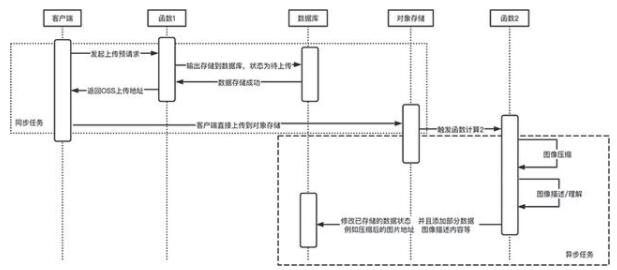
在 Serverless 架构下文件上传文件示例
以阿里云函数计算为例,针对上述两种常见的上传方法通过 Bottle 来实现。在函数计算中,先初始化对象存储相关的对象等:
初始化对象存储相关的对象等:
- AccessKey = { "id": '', "secret": ''}OSSConf = { 'endPoint': 'oss-cn-hangzhou.aliyuncs.com', 'bucketName': 'bucketName', 'objectSignUrlTimeOut': 60}#获取/上传文件到OSS的临时地址auth = oss2.Auth(AccessKey['id'], AccessKey['secret'])bucket = oss2.Bucket(auth, OSSConf['endPoint'], OSSConf['bucketName'])#对象存储操作getUrl = lambda object, method: bucket.sign_url(method, object, OSSConf['object SignUrlTimeOut'])getSignUrl = lambda object: getUrl(object, "GET")putSignUrl = lambda object: getUrl(object, "PUT")#获取随机字符串randomStr = lambda len: "".join(random.sample('abcdefghijklqrstuvwxyz123456789 ABCDEFGZSA' * 100, len))
第一种上传方法,通过 Base64 上传之后,将文件持久化到对象存储:
- #文件上传# URI: /file/upload# Method: POST@bottle.route('/file/upload', "POST")def postFileUpload(): try: pictureBase64 = bottle.request.GET.get('picture', '').split("base64,")[1] object = randomStr(100) with open('/tmp/%s' % object, 'wb') as f: f.write(base64.b64decode(pictureBase64)) bucket.put_object_from_file(object, '/tmp/%s' % object) return response({ "status": 'ok', }) except Exception as e: print("Error: ", e) return response(ERROR['SystemError'], 'SystemError')
第二种上传方法,获取预签名的对象存储地址,再在客户端发起上传请求,直传到对象存储:
- #获取文件上传地址# URI: /file/upload/url# Method: GET@bottle.route('/file/upload/url', "GET")def getFileUploadUrl(): try: object = randomStr(100) return response({ "upload": putSignUrl(object), "download": 'https://download.xshu.cn/%s' % (object) }) except Exception as e: print("Error: ", e) return response(ERROR['SystemError'], 'SystemError')
HTML 部分:
- <div style="width: 70%"> <div style="text-align: center"> <h3>Web端上传文件</h3> </div> <hr> <div> <p> 方案1:上传到函数计算进行处理再转存到对象存储,这种方法比较直观,问题是 FaaS 平台与 API 网关处有数据包大小上限,而且对二进制文件处理并不好。 </p> <input type="file" name="file" id="fileFc"/> <input type="button" onclick="UpladFileFC()" value="上传"/> </div> <hr> <div> <p> 方案2:直接上传到对象存储。流程是先从函数计算获得临时地址并进行数据存储(例如将文件信息存到 Redis 等),然后再从客户端将文件上传到对象存储,之后通过对象存储触发器触发函数,从存储系统(例如已经存储到Redis)读取到信息,再对图像进行处理。 </p> <input type="file" name="file" id="fileOss"/> <input type="button" onclick="UpladFileOSS()" value="上传"/> </div></div>
通过 Base64 上传的客户端 JavaScript 实现:
- function UpladFileFC() { const oFReader = new FileReader(); oFReader.readAsDataURL(document.getElementById("fileFc").files[0]); oFReader.onload = function (oFREvent) { const xmlhttp = window.XMLHttpRequest ? (new XMLHttpRequest()) : (new ActiveXObject("Microsoft.XMLHTTP")) xmlhttp.onreadystatechange = function () { if (xmlhttp.readyState == 4 && xmlhttp.status == 200) { alert(xmlhttp.responseText) } } const url = "https://domain.com/file/upload" xmlhttp.open("POST", url, true); xmlhttp.setRequestHeader("Content-type", "application/json"); xmlhttp.send(JSON.stringify({ picture: oFREvent.target.result })); }}
客户端通过预签名地址,直传到对象存储的客户端 JavaScript 实现:
- function doUpload(bodyUrl) { const xmlhttp = window.XMLHttpRequest ? (new XMLHttpRequest()) : (new Active XObject("Microsoft.XMLHTTP")); xmlhttp.open("PUT", bodyUrl, true); xmlhttp.onload = function () { alert(xmlhttp.responseText) }; xmlhttp.send(document.getElementById("fileOss").files[0]); } function UpladFileOSS() { const xmlhttp = window.XMLHttpRequest ? (new XMLHttpRequest()) : (new Active XObject("Microsoft.XMLHTTP")) xmlhttp.onreadystatechange = function () { if (xmlhttp.readyState == 4 && xmlhttp.status == 200) { const body = JSON.parse(xmlhttp.responseText) if (body['url']) { doUpload(body['url']) } } } const getUploadUrl = 'https://domain.com/file/upload/url' xmlhttp.open("POST", getUploadUrl, true); xmlhttp.setRequestHeader("Content-type", "application/json"); xmlhttp.send();}
整体效果如图中所示。

Serverless 架构下文件上传实验 Web 端效果
此时,我们可以在当前页面进行不同类型的文件上传方案实验。
2、文件读写与持久化方法
应用在执行过程中,可能会涉及文件的读写操作,或者是一些文件的持久化操作。在传统的云主机模式下,可以直接读写文件,或者将文件在某个目录下持久化,但是在 Serverless 架构下并不是这样的。
由于 FaaS 平台是无状态的,并且用过之后会被销毁,因此文件并不能直接持久化在实例中,但可以持久化到其他的服务中,例如对象存储、NAS 等。
同时,在不配置 NAS 的情况下,FaaS 平台通常情况下只具备 /tmp 目录可写权限,所以部分临时文件可以缓存在 /tmp 文件夹下。
3、慎用部分 Web 框架的特性
(1) 异步
函数计算是请求级别的隔离,所以可以认为这个请求结束了,实例就有可能进入一个静默状态。而在函数计算中,API 网关触发器通常是同步调用(以阿里云函数计算为例,通常只在定时触发器、OSS 事件触发器、MNS 主题触发器和 IoT 触发器等几种情况下是异步触发)。
这就意味着当 API 网关将结果返给客户端的时候,整个函数就会进入静默状态,或者被销毁,而不是继续执行完异步方法。所以通常情况下像 Tornado 等框架就很难在 Serverless 架构下发挥其异步的作用。当然,如果使用者需要异步能力,可以参考云厂商所提供的异步方法。
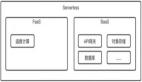
以阿里云函数计算为例,阿里云函数计算为用户提供了一种异步调用能力。当函数的异步调用被触发后,函数计算会将触发事件放入内部队列,并返回请求 ID,而不会返回具体的调用情况及函数执行状态。如果用户希望获得异步调用的结果,可以通过配置异步调用目标来实现,如图所示。
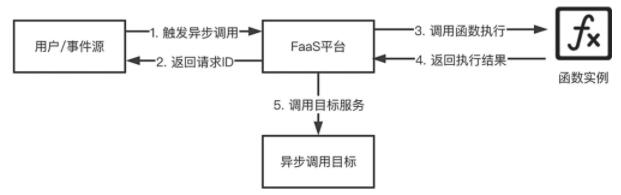
函数异步功能原理简图
(2) 定时任务
在 Serverless 架构下,应用一旦完成当前请求,就会进入静默状态,甚至实例会被销毁,这就导致一些自带定时任务的框架没有办法正常执行定时任务。函数计算通常是由事件触发,不会自主定时启动。例如 Egg 项目中设定了一个定时任务,但是在实际的函数计算中如果没有通过触发器触发该函数,该函数不会被触发,也不会从内部自动启动来执行定时任务,此时可以使用定时触发器,通过定时触发器触发指定方法来替代定时任务。
4、要注意应用组成结构
(1) 静态资源与业务逻辑
在 Serverless 架构下,静态资源更应该在对象存储与 CDN 的加持下对外提供服务,否则所有的资源都在函数中。通过函数计算对外暴露,不仅会让函数的业务逻辑并发度降低,也会造成更多的成本。尤其是将一些已有的程序迁移到 Serverless 架构上,例如 Wordpress 等,更要注意将静态资源与业务逻辑进行拆分,否则在高并发情况下,性能与成本都将会受到比较严峻的考验。
(2) 业务逻辑的拆分
在众多云厂商中,函数的收费标准都是依靠运行时间、配置的内存以及产生的流量收费的。如果一个函数的内存设置不合理,会导致成本成倍增加。想要保证内存设置合理,更要保证业务逻辑结构的可靠性。
以阿里云函数计算为例,一个应用有两个对外接口,其中有一个接口的内存消耗在 128MB 以下,另一个接口的内存消耗稳定在 3000MB 左右。这两个接口平均每天会被触发 10000 次,并且时间消耗均在 100 毫秒。如果两个接口写到一个函数中,那么这个函数可能需要将内存设置在 3072MB,同时用户请求内存消耗较少的接口在冷启动情况下难以得到较好的性能;如果两个接口分别写到函数中,则两个函数内存分别设置成 128MB 以及 3072MB 即可,如表所示。

通过上表可以明确看出合理、适当地拆分业务会在一定程度上节约成本。上面例子的成本节约近 50%。