前言
独占锁是一种悲观锁,synchronized就是一种独占锁,会导致其它所有需要锁的线程挂起,等待持有锁的线程释放锁;
而另一个更加有效的锁就是乐观锁。所谓乐观锁就是,每次不加锁而是假设没有冲突而去完成某项操作,如果因为冲突失败就重试,直到成功为止。乐观锁用到的机制就是CAS;
今天我们就来介绍下cas机制;
一、CAS介绍
1、什么是CAS
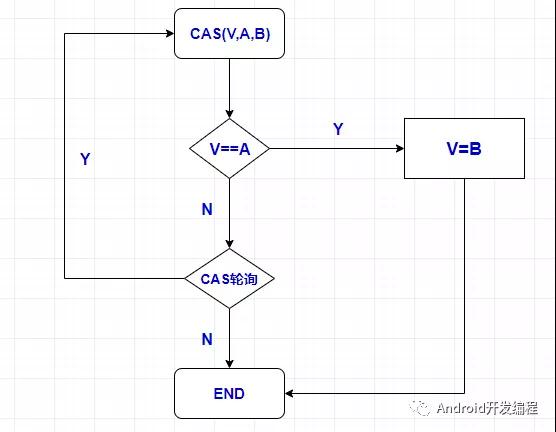
- CAS,compare and swap的缩写,中文翻译成比较并交换。CAS指令在Intel CPU上称为CMPXCHG指令,它的作用是将指定内存地址的内容与所给的某个值相比,如果相等,则将其内容替换为指令中提供的新值,如果不相等,则更新失败从内存领域来说这是乐观锁,因为它在对共享变量更新之前会先比较当前值是否与更新前的值一致,如果是,则更新,如果不是,则无限循环执行(称为自旋),直到当前值与更新前的值一致为止,才执行更新;
- CAS 操作包含三个操作数 —— 内存位置(V)、预期原值(A)和新值(B)。如果内存位置的值与预期原值相匹配,那么处理器会自动将该位置值更新为新值 。否则,处理器不做任何操作。无论哪种情况,它都会在 CAS 指令之前返回该 位置的值;
- 通常将 CAS 用于同步的方式是从地址 V 读取值 A,执行多步计算来获得新 值 B,然后使用 CAS 将 V 的值从 A 改为 B。如果 V 处的值尚未同时更改,则 CAS 操作成功;
- 类似于 CAS 的指令允许算法执行读-修改-写操作,而无需害怕其他线程同时 修改变量,因为如果其他线程修改变量,那么 CAS 会检测它(并失败),算法 可以对该操作重新计算;
2、那些地方采用了 CAS 机制
- 在 java.util.concurrent.atomic 包下,一系列以 Atomic 开头的包装类。例如AtomicBoolean,AtomicInteger,AtomicLong 等,它们就是典型的利用 CAS 机制实现的原子操作类;
- Lock 系列类的底层实现以及 Java 1.6 在 synchronized 转换为重量级锁之前,也会采用到 CAS 机制;
3、synchronized 和 CAS 的区别
- synchronized 采用的是 CPU 悲观锁机制,即线程获得的是独占锁。独占锁就意味着 其他线程只能依靠阻塞来等待线程释放锁。而在 CPU 转换线程阻塞时会引起线程上下文切换,当有很多线程竞争锁的时候,会引起 CPU 频繁的上下文切换导致效率很低。尽管 Java1.6 为 synchronized 做了优化,增加了从偏向锁到轻量级锁再到重量级锁的过度,但是在最终转变为重量级锁之后,性能仍然较低;
- Synchronized(未优化前)最主要的问题是:在存在线程竞争的情况下会出现线程阻塞和唤醒锁带来的性能问题,因为这是一种互斥同步(阻塞同步)。而CAS并不是武断的间线程挂起,当CAS操作失败后会进行一定的尝试,而非进行耗时的挂起唤醒的操作,因此也叫做非阻塞同步。这是两者主要的区别;
- 使用CAS时非阻塞同步,也就是说不会将线程挂起,会自旋(无非就是一个死循环)进行下一次尝试,如果这里自旋时间过长对性能是很大的消耗。如果JVM能支持处理器提供的pause指令,那么在效率上会有一定的提升;
- CAS它当中使用了3个基本操作数:内存地址 V,旧的预期值 A,要修改的新值 B。采用的是一种乐观锁的机制,它不会阻塞任何线程,所以在效率上,它会比 synchronized 要高。所谓乐观锁就是:每次不加锁而是假设没有冲突而去完成某项操作,如果因为冲突失败就重试,直到成功为止;
4、为什么需要CAS机制
我们经常使用volatile关键字修饰某一个变量,表明这个变量是全局共享的一个变量,同时具有了可见性和有序性。但是却没有原子性。比如说一个常见的操作a++。这个操作其实可以细分成三个步骤:
(1)从内存中读取a
(2)对a进行加1操作
(3)将a的值重新写入内存中
在单线程状态下这个操作没有一点问题,但是在多线程中就会出现各种各样的问题了。因为可能一个线程对a进行了加1操作,还没来得及写入内存,其他的线程就读取了旧值。造成了线程的不安全现象;
Volatile关键字可以保证线程间对于共享变量的可见性可有序性,可以防止CPU的指令重排序(DCL单例),但是无法保证操作的原子性,所以jdk1.5之后引入CAS利用CPU原语保证线程操作的院子性;
CAS操作由处理器提供支持,是一种原语。原语是操作系统或计算机网络用语范畴。是由若干条指令组成的,用于完成一定功能的一个过程,具有不可分割性,即原语的执行必须是连续的,在执行过程中不允许被中断。如 Intel 处理器,比较并交换通过指令的 cmpxchg 系列实现;
二、cas底层实现
1、底层依靠Unsafe的CAS操作来保证原子性;
CAS的实现主要在JUC中的atomic包,我们以AtomicInteger类为例:
/**
* Atomically adds the given value to the current value.
*
* @param delta the value to add
* @return the previous value
*/
public final int getAndAdd(int delta) {
return unsafe.getAndAddInt(this, valueOffset, delta);
}
public final int incrementAndGet() {
for (;;) {
int current = get();
int next = current + 1;
if (compareAndSet(current, next))
return next;
}
}
private volatile int value;
public final int get() {
return value;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
代码是一个无限循环,也就是CAS的自旋。循环体当中做了三件事:
获取当前值;
当前值+1,计算出目标值;
进行CAS操作,如果成功则跳出循环(当前值和目标值相等),如果失败则重复上述步骤;
2、Unsafe.class
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while (!this.compareAndSwapInt(var1, var2, var5, var5 + var4));//native方法
return var5;
}
********
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);//底层c++实现
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);//底层c++实现
3、compareAndSwapInt为native方法,对应底层hotspot虚拟机unsage.cpp
UNSAFE_ENTRY(jboolean, Unsafe_CompareAndSwapInt(JNIEnv *env, jobject unsafe, jobject obj, jlong offset, jint e, jint x))
UnsafeWrapper("Unsafe_CompareAndSwapInt");
oop p = JNIHandles::resolve(obj);
jint* addr = (jint *) index_oop_from_field_offset_long(p, offset);
return (jint)(Atomic::cmpxchg(x, addr, e)) == e;
UNSAFE_END
***
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
这里可以看到最终使用了Atomic::cmpxchg来保证原子性,可继续跟进代码
4、Atomic::cmpxchg针对不同平台有不同的实现方式
***
// Adding a lock prefix to an instruction on MP machine
#define LOCK_IF_MP(mp) "cmp $0, " #mp "; je 1f; lock; 1: "
***
inline jint Atomic::cmpxchg (jint exchange_value, volatile jint* dest, jint compare_value) {
int mp = os::is_MP();
__asm__ volatile (LOCK_IF_MP(%4) "cmpxchgl %1,(%3)"
: "=a" (exchange_value)
: "r" (exchange_value), "a" (compare_value), "r" (dest), "r" (mp)
: "cc", "memory");
return exchange_value;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
最重要的指令为 LOCK_IF_MP , MP是指多CPU(multi processors),最终意义为多CPU的情况下需要lock,通过lock的方式来保证原子;
lock解释:
- 确保后续指令执行的原子性;
- 在Pentium及之前的处理器中,带有lock前缀的指令在执行期间会锁住总线,使得其它处理器暂时无法通过总线访问内存,很显然,这个开销很大。在新的处理器中,Intel使用缓存锁定来保证指令执行的原子性,缓存锁定将大大降低lock前缀指令的执行开销;
- 禁止该指令与前面和后面的读写指令重排序;
- 把写缓冲区的所有数据刷新到内存中;
总之:JAVA中我们使用到涉及到CAS操作的底层实现为对应平台虚拟机中的c++代码(lock指令)实现来保证原子性;
三、CAS 的缺点及解决方式
CAS虽然很高效的解决原子操作,但是CAS仍然存在三大问题。ABA问题,循环时间长开销大和只能保证一个共享变量的原子操作;
1、ABA问题:因为CAS需要在操作值的时候检查下值有没有发生变化,如果没有发生变化则更新,但是如果一个值原来是A,变成了B,又变成了A, 那么使用CAS进行检查时会发现它的值没有发生变化,但是实际上却变化了;
ABA问题的解决思路就是使用版本号。在变量前面追加上版本号,每次变量更新的时候把版本号加一,那么A-B-A 就会变成1A-2B-3A;
从Java1.5开始JDK的atomic包里提供了一个类 AtomicStampedReference 来解决ABA问题。这个类的compareAndSet方法作用是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值;
2、循环时间长开销大:在并发量比较高的情况下,如果许多线程反复尝试更新某一个变量,即自旋CAS如果长时间不成功,会给CPU带来非常大的执行开销;
如果JVM能支持处理器提供的pause指令,那么效率会有一定的提升。pause指令有两个作用,第一它可以延迟流水线执行指令(de-pipeline),使CPU不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零。第二它可以避免在退出循环的时候因内存顺序冲突(memory order violation)而引起CPU流水线被清空(CPU pipeline flush),从而提高CPU的执行效率;
代码层面,破坏掉for死循环,当自旋超过一定时间或者一定次数时,return退出;
使用类似ConcurrentHashMap的方法。当多个线程竞争时,将粒度变小,将一个变量拆分为多个变量,达到多个线程访问多个资源的效果,最后再调用sum把它合起来,能降低CPU消耗,但是治标不治本;
3、只能保证一个共享变量的原子操作:当对一个共享变量执行操作时,我们可以使用循环CAS的方式来保证原子操作,但是对多个共享变量操作时,循环CAS就无法保证操作的原子性;
这个时候就可以用锁,或者有一个取巧的办法,就是把多个共享变量合并成一个共享变量来操作。比如有两个共享变量i=2,j=a,合并一下ij=2a,然后用CAS来操作ij;
从Java1.5开始JDK提供了AtomicReference类来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行CAS操作;
四、CAS使用的时机
线程数较少、等待时间短可以采用自旋锁进行CAS尝试拿锁,较于synchronized高效;
线程数较大、等待时间长,不建议使用自旋锁,占用CPU较高;
总结
CAS可以保证多线程对数据写操作时数据的一致性;
CAS的思想:三个参数,一个当前内存值V、旧的预期值A、即将更新的值B,当且仅当预期值A和内存值V相同时,将内存值修改为B并返回true,否则什么都不做,并返回false;