【51CTO.com快译】

深度强化学习是人工智能最令人关注的分支之一。它是人工智能领域一些技术最显著成就的背后支撑,包括在棋盘和电子游戏、自动驾驶汽车、机器人和人工智能硬件设计方面中击败人类冠军。
深度强化学习利用深度神经网络的学习能力来解决传统 RL 技术无法解决的复杂问题。深度强化学习比机器学习的其他分支复杂得多,在这篇文章中,将在不涉及技术细节的情况下揭开它的神秘面纱。
状态、奖励和行动
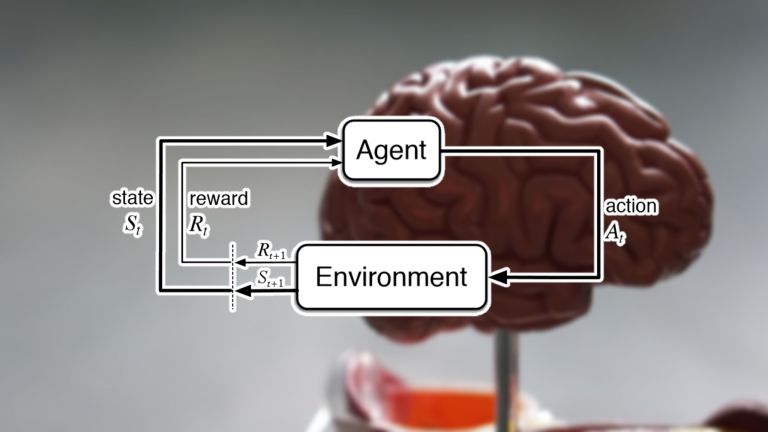
每个强化学习问题的核心都是一个 agent (代理)和一个环境。环境提供是有关系统状态的信息。代理是用来观察这些状态并通过执行操作与环境进行交互,其动作可以是离散的(如拨动开关)或连续的(如转动旋钮)。这些操作会促使环境过渡到一个新状态。并且根据新状态是否与系统目标相关,代理将获得奖励(如果将代理远离其目标,奖励也可以为零或负)。
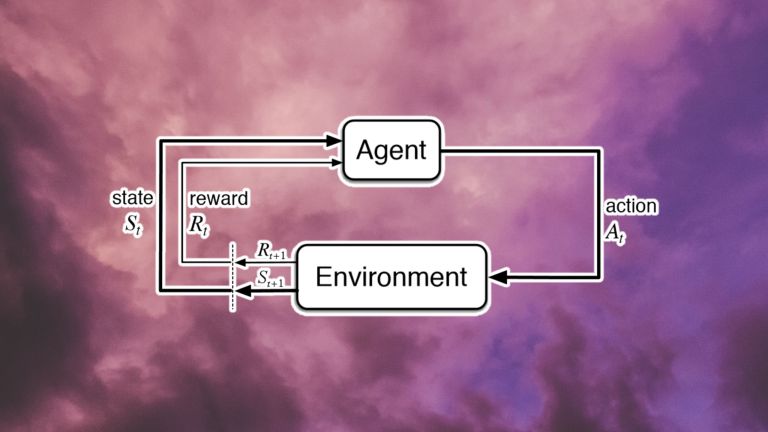
状态-动作-奖励循环图
状态-动作-奖励的每一个循环都称为一个步骤。强化学习系统继续循环迭代,直到达到所需的状态或达到最大步骤数为止。这一系列的步骤称为一集。在每一片段开始时,环境被设置为初始状态,代理的奖励重置为零。
强化学习的目标是训练代理采取行动,以其回报最大化,且代理的动作生成功能被称为策略。一个代理通常需要很多情节来学习一个好的策略。对于简单的问题,几百个情节可能足以让代理学习一个不错的策略。对于更复杂的问题,代理可能需要数百万次训练才可以实现。
强化学习系统有更微妙的细微差别。例如,RL 环境可以是确定性的或非确定性的。在确定性环境中,多次运行一系列状态-动作对总是会产生相同的结果。相比之下,在非确定性 RL 问题中,环境状态可能会因代理行为以外的事物(例如,时间的流逝、天气、环境中的其他代理)而发生变化。
强化学习应用

为了更好地理解强化学习的组成部分,通过下面几个例子进行讲解。
国际象棋:在这里,环境就是棋盘,环境的状态是棋子在棋盘上的位置。RL 代理可以是其中一名玩家(或者,两名玩家可以是在同一环境中分别训练的RL 代理)。每一盘棋都是一集,这一集从初始状态开始,黑板和白板的边缘排列着黑色和白色的棋子。在每一步中,代理都会观察棋盘(状态)并移动其中的一个部分(采取行动),从而将环境转换为新状态。该代理会因达到将死状态而获得奖励,否则将获得零奖励。国际象棋的一个关键挑战是,棋手在将对手将死之前不会得到任何奖励,这使得机器学习变得很困难。
Atari Breakout: Breakout 是一款玩家控制球拍的电子游戏。有一个球在屏幕上移动,每次击中球拍,它就会反弹到屏幕的顶部,那里排列着一排排的砖块。每次球拍碰到砖块时,砖块就会被破坏,随之球会反弹回来。在 Breakout 中,环境就是游戏屏幕。状态是球拍和砖块的位置,以及球的位置和速度。代理可以执行的操作有向左移动、向右移动或着不移动。每次球击中砖块时,代理都会收到正奖励,如果球越过球拍并到达屏幕底部,则代理会收到负奖励。
自动驾驶汽车:在自动驾驶中,代理就是汽车,环境就是汽车行驶的空间。RL 代理通过摄像头、激光雷达和其他传感器观察环境状态。代理可以执行导航操作,例如加速、刹车、左转或右转等。RL 代理会因为保持正常驾驶、避免碰撞、遵守驾驶规则和遵守交通路线而获得奖励。
强化学习功能
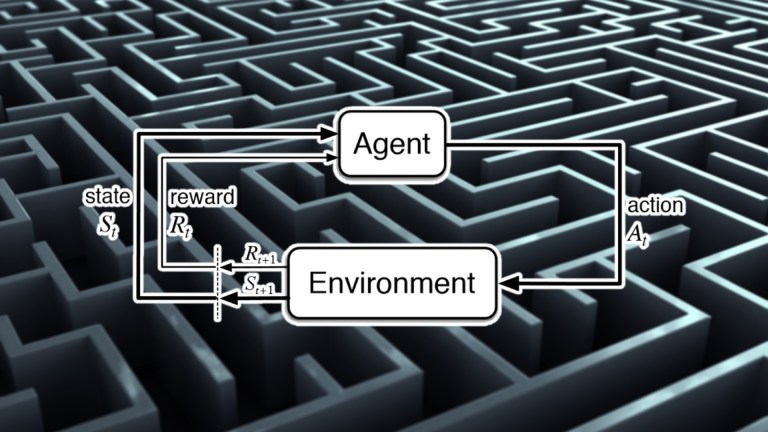
基本上,强化学习的目标是以最大化奖励的方式将状态映射到动作。但是 RL 代理究竟学习了什么?
RL 系统有三种学习算法:
基于策略的算法:这是最常见的优化类型。策略将状态映射到操作。学习策略的 RL 代理可以创建从当前状态到目标的动作轨迹。
例如,实现一个正在优化策略以通过迷宫导航并到达出口的代理。首先,它进行随机移动,但不会收到任何奖励。在其中一集中,它最终到达出口并获得出口奖励。它回溯其轨迹,并根据代理与最终目标的接近程度重新调整每个状态-动作对的奖励。在下一集中,RL 代理将更好地了解给定每个状态要采取的操作,从而逐渐调整策略,直到收敛到最优解。
REINFORCE 是一种流行的基于策略的算法。基于策略的函数的优势在于可以应用于各种强化学习问题。基于策略的算法的权衡在于,它们的样本效率低,并且在收敛到最佳解决方案之前需要大量训练。
基于值的算法:基于值的函数学习评估状态和动作的值。基于值的函数可帮助 RL 代理评估当前状态和操作的未来回报是多少。
基于值的函数有两种变体:Q 值和 V 值。Q 函数是估计状态-动作对的预期回报。V 函数仅估计状态的值。Q 函数更常见,因为它更容易将状态-动作对转换为 RL 策略。
两种流行的基于值的算法是 SARSA 和 DQN。基于值的算法比基于策略的 RL 具有更高的样本效率。它们的局限性在于它们仅适用于离散动作空间(除非对其进行一些更改)。
基于模型的算法:基于模型的算法采用不同的方法进行强化学习。他们不是评估状态和动作的价值,而是预测给定当前状态和动作的环境状态。基于模型的强化学习允许agent在采取任何行动之前模拟不同的轨迹。
基于模型的方法为代理提供了远见,并减少了手动收集数据的需要。在收集训练数据和经验既昂贵又缓慢的应用中非常有利(例如,机器人和自动驾驶汽车)。
但基于模型的强化学习的关键挑战是,创建环境的真是模型可能非常困难。非确定性环境,如现实世界,很难建模。在某些情况下,开发人员设法创建近似真实环境的模拟。但是,即使是学习这些模拟环境的模型,也非常困难。
尽管如此,基于模型的算法在诸如国际象棋和围棋等确定性问题中变得流行。蒙特卡罗树搜索 (MTCS) 是一种流行的基于模型的方法,可应用于确定性环境。
组合方法:为了克服各类强化学习算法的缺点,科学家们开发了组合不同类型学习函数元素的算法。例如,Actor-Critic 算法结合了基于策略和基于值的函数的优点。这些算法使用来自价值函数(评论家)的反馈来引导策略学习者(参与者)朝着正确的方向改进,从而产生一个更具样本效率的系统。
为什么要进行深度强化学习?

到目前为止,还没有谈到深度神经网络。事实上,可以以任何方式实现上述所有算法。例如,Q-learning是一种经典的强化学习算法,它在agent与环境交互时创建了一个状态-动作-奖励值表。在处理状态和操作数量非常少且非常简单的环境时,此类方法可以很好地工作。
但是,当处理一个复杂的环境时,在这个环境中,动作和状态的组合数量可能会达到巨大的数量,或者环境是不确定的,并且可能具有几乎无限的状态,评估每个可能的状态-动作对就变得不可能了。
在这些情况下,需要一个近似函数,该函数可以根据有限的数据学习最优策略,这就是人工神经网络所做的。给定正确的结构和优化函数,深度神经网络可以学习最优策略,而无需遍历系统的所有可能状态。深度强化学习代理仍然需要大量数据(例如,在Dota和星际争霸中进行数千小时的游戏),但它们可以解决经典强化学习系统无法解决的问题。
例如,深度强化学习模型可以使用卷积神经网络从视觉数据中提取状态信息,例如摄像机输入和视频游戏图形。而递归神经网络可以从帧序列中提取有用的信息,比如球的方向,或者汽车是否停放或移动。这种复杂的学习能力可以帮助 RL 代理理解更复杂的环境,并将其状态映射到动作。
深度强化学习可与机器监督学习相媲美。该模型生成动作,并根据来自环境的反馈调整其参数。然而,深度强化学习也有一些独特的挑战,使其不同于传统的监督学习。
与监督学习不同,在监督学习问题中,模型具有一组标记数据,RL 代理只能访问其自身经验的结果。它能够根据在不同训练阶段收集的经验来学习最佳策略。但也可能错过许多其他导致更好政策的最佳轨迹。强化学习还需要评估状态-动作对的轨迹,这比每个训练示例与其预期结果配对的监督学习问题更难学习。
这种增加的复杂性增加了深度强化学习模型的数据要求。但监督学习不同的是,深度强化学习模型在训练期间收集数据,监督学习可以提前管理和准备数据。在某些类型的 RL 算法中,在一个片段中收集的数据必须在之后被丢弃,并且不能用于进一步加快未来片段中的模型调整过程。
深度强化学习与通用人工智能
人工智能社区对深度强化学习的推动程度存在分歧。一些科学家认为,使用正确的 RL 架构,就可以解决任何类型的问题,包括通用人工智能。这些科学家相信,强化学习与产生自然智能的算法相同,如果有足够的时间和精力以及适当的奖励,我们可以重新创造人类水平的智能。
其他人则认为强化学习不能解决人工智能的一些最基本的问题。另一部分人认为,尽管深度强化学习代理有很多好处,但需要明确定义问题,并且无法自己发现新问题和解决方案。
无论如何,不可否认的是,深度强化学习已经帮助解决了一些非常复杂的挑战,并且将继续成为 人工智能社区目前感兴趣和研究的一个重要领域。
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】