在《基于数据分类分级和敏感数据保护,保障企业数据安全》一文中,我们讲解了Dataphin中资产安全的主要应用场景和基本概念,那么如何利用Dataphin的安全能力,来保障企业的数据安全呢?
我们来看一个最常见的案例:消费者隐私数据保护。
场景介绍
近几年,随着消费者个人意识的崛起和对隐私的重视,数据安全成为了一个越来越热门的话题,国家也陆续发布了一些相关规定,来规范数据的采集和使用。在企业的发展过程中,如果不重视敏感数据的保护,不重视数据安全体系的建设,那么一旦发生了敏感数据泄漏事件,轻则企业口碑受损,业务受影响;重则会直接触法律,受到主管部门的处罚和制裁。
而在企业领域的敏感信息中,个人敏感信息是绝对的大头,包括个人的身份信息(姓名、身份证号码)、联系方式(手机、邮箱、地址)、个人财产信息、生物识别信息等等,都属于个人敏感数据。这些数据一旦泄漏,对用户的个人生活以及对企业的业务运行,都会产生非常大的损害,所以在企业的业务运转中,要对消费者的个人隐私数据进行脱敏保护。
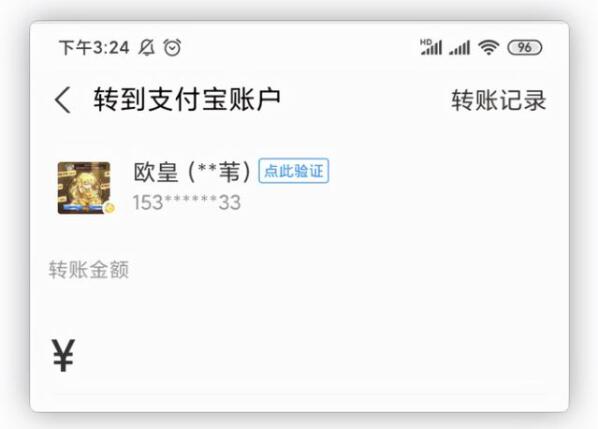
图片:支付宝中,对用户姓名与用户账号的脱敏保护
主要流程
首先,我们回顾一下在Dataphin上,实现敏感数据保护的主要流程:
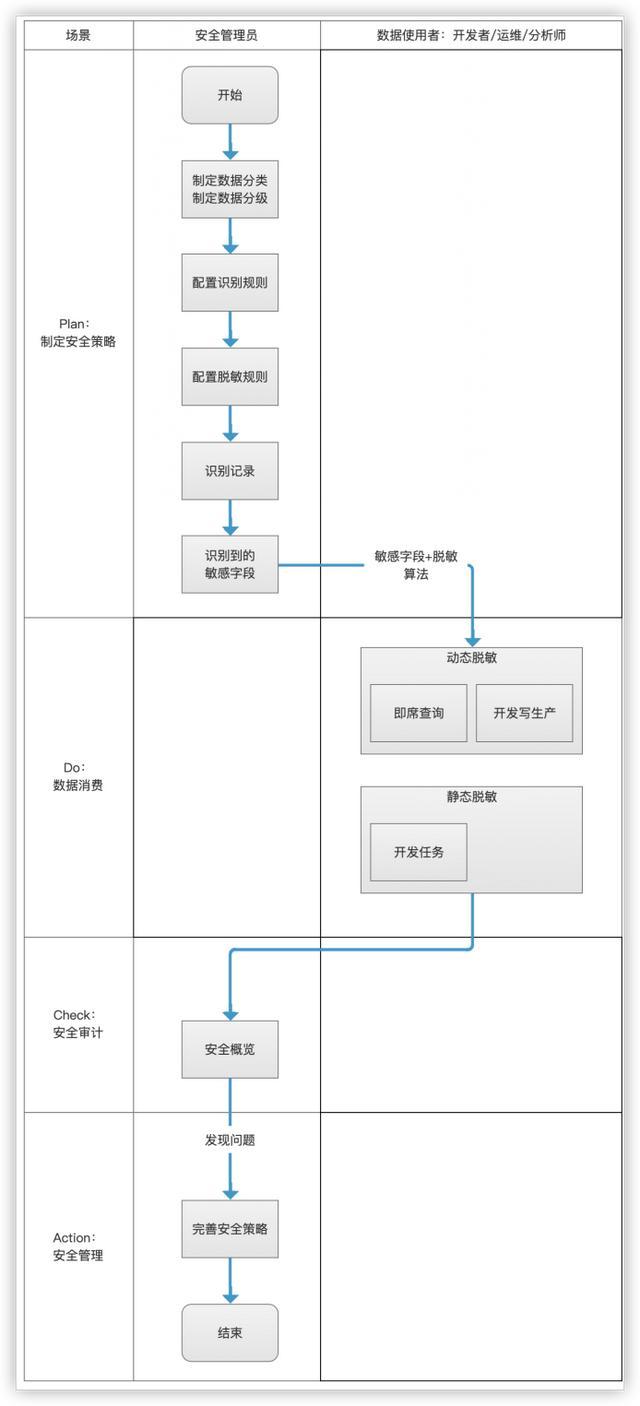
在Dataphin中,实现敏感数据保护,主要可以分为以下三个步骤:
1、识别敏感数据:即设定数据分类、数据分级、识别规则等内容
2、设置敏感数据保护方式:为识别的敏感数据选择合适的脱敏算法、设定脱敏规则
3、数据消费:在即席查询、开发数据写生产等场景进行数据消费时脱敏
详细步骤
接下来,我们以用户敏感信息中,最常见的用户姓名为例,展示如何一步步的首先用户姓名的识别和脱敏保护。
1、识别敏感数据
假设我们已经建立好了数据分类和数据分级(Dataphin会内置通用的分类和分级标准,支持开箱即用),我们直接进入新建识别规则的模拟步骤:
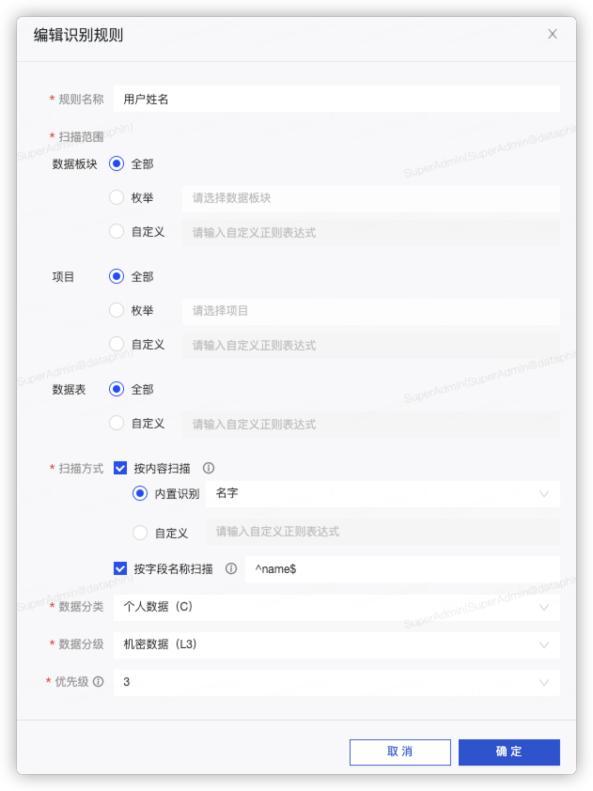
新建一个【用户姓名】的识别规则;
扫描范围选择【全部】;
扫描方式选择【内置识别】-【名字】(如果用户姓名的字段都叫【name】,也可以配置正则规则【^name$】);
数据分类选择【个人数据(C)】;
数据分级选择【机密数据(L3)】(根据自己企业的情况灵活调衡);
优先级选择【3】(中间优先级,根据自己企业的情况灵活调整);
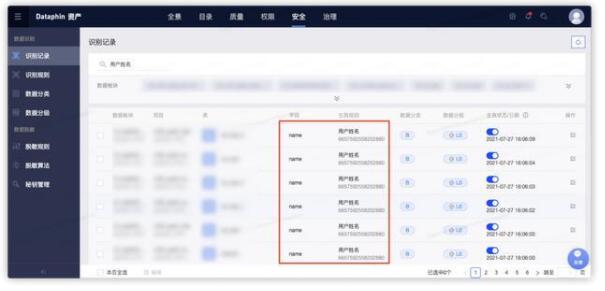
配置完成识别规则后,我们可以触发一次【手动规则扫描】,或者等到第二天,系统会自动执行一次全局扫描。最终敏感数据识别的结果,都可以在【识别记录】页面看到:
2、设置敏感数据保护方式
识别到敏感数据之后,下一步就是给敏感数据设置合适的保护方式,从而保证数据不泄漏。
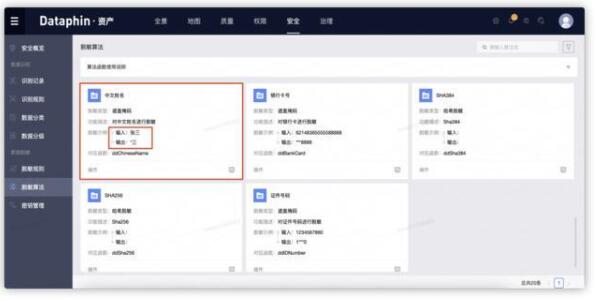
Dataphin当前内置了多种遮盖脱敏规则(如【张三】,显示成【*三】)、哈希脱敏规则(如【张三】,显示为【615DB57AA314529AAA0FBE95B3E95BD3】),可以满足大部分业务场景下的数据保护需求,并在未来支持加解密算法和用户自定义脱敏算法。
这里建议大家根据业务需求,选择合适的算法。比如对于用户姓名,在大部分的业务场景中(如支付宝转账),都是不能显示完整的名称,但是可以显示一部分,用于身份确认,这样就可以选择内置的【中文姓名】的脱敏算法
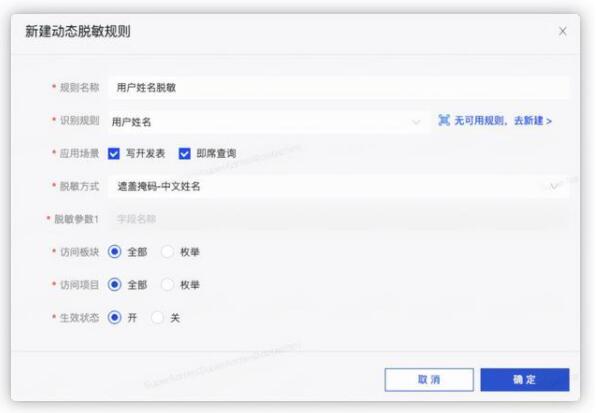
选择好合适的脱敏算法之后,我们就可以配置动态脱敏规则了,还是以用户姓名为例:
新建一个【用户姓名脱敏】的脱敏规则;
绑定已经建好的敏感数据识别规则【用户姓名】;
应用场景选择【写开发表】、【即席查询】;
脱敏方式选择【遮盖掩码-中文姓名】;
生效范围选择【全部】
至此,我们的敏感数据识别和保护就已经完全配置完成了,接下来在数据消费的过程中,就可以对数据进行保护了。
3、数据消费
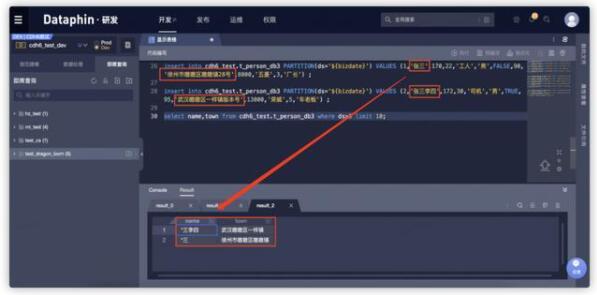
下面已即席查询为例,展示敏感数据识别和脱敏的效果:
可以看到,我们开始往表格里写入的数据是【张三】,因为写入了敏感数据【name】字段,也就是【用户姓名】,所以在数据读取的时候,系统自动的进行了脱敏,操作的同学只能够看到【*三】,从而防止敏感数据泄漏,保护了数据安全。
结语
上面通过用户姓名这样一个非常很简单的案例,串讲了整个敏感数据识别和脱敏的主流程,相信能帮助您理解整个数据安全保护的机制;而在主流程之外,还有数据分类分级的制定、审核识别记录并手动修改、脱敏白名单等流程。同时,在企业实际的数据安全保护中,还有更多的系统工作要做,比如制定符合企业的数据分类分级体系、建立完整的数据识别体系等等。