













来自中国科学技术大学的研究者提出了一种教育情境感知的认知诊断框架,使用神经网络以及端到端的训练框架,自适应学习不同教育情境信息的量化影响,并结合现有认知诊断工作的方法,增强了诊断的结果。
父母的受教育水平是否与学生的学习表现相关?家庭条件、学校资源到底对学生能力产生多大影响?上课氛围、老师态度与学生的学习效果有怎样的关系?类似的教育情境信息对学生能力到底有怎样的影响,一起跟随中国科学技术大学的刘淇教授智慧教育课题组来一探究竟吧!

- 论文地址:https://doi.org/10.1145/3447548.3467264
- 项目地址:github.com/bigdata-ustc/ECD
- 研究组主页:base.ustc.edu.cn/
教育情境与认知诊断
学生学习过程相关情境信息(如学习习惯,父母受教育程度,家庭条件等),被称为教育情境信息;在教育领域中,这些情境信息对理解教育过程以及解决教育问题(如教学安排,教育公平等)都有很重要的意义。
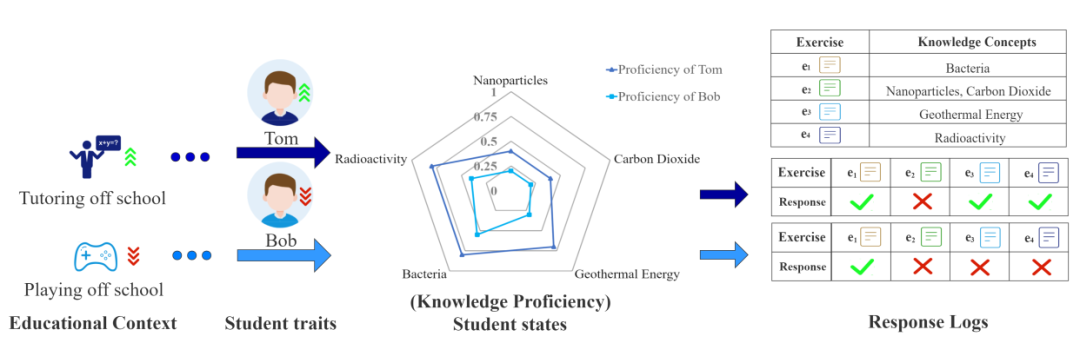
图表 1:教育情境、学生能力与学生表现
在智慧教育中,认知诊断是一项基础而必要的任务;它通过收集学生的信息(通常是答题等行为记录)与试题信息(如试题文本),来推断学生当前的知识状态。如图,学生选择了一些题目进行练习,得到了对应的答题记录,每道试题包含特定的知识点;通过认知诊断可以得到该学生在不同知识点上的掌握程度。例如学生答对了试题e_1,而e_1包含「Bacteria」这个知识点,因此诊断得出该学生对于「Bacteria」知识点的掌握程度较高(例如 0.8 等),反映到诊断报告的雷达图中蓝线的靠近外侧。认知诊断的结果可以用作教育资源推荐、学生表现预测、学习小组分组等后续智慧教育应用的支撑。
背景
情境信息或者说上下文信息目前在信息检索相关领域(如推荐系统,web 搜索,广告等)有着非常广泛的应用,它们反映着一个心理学的通识:情境信息往往通过影响人的内在特质来影响人的外在表现。如推荐系统中,情境信息通过影响用户的内在偏好,从而引导用户的消费行为。而在教育领域,教育情境信息则影响着学生的知识状态,进而反映在学生的练习作答结果中。
教育情境信息在传统教育学中讨论已久,它们主要延续着实证研究的思路(提出假设 - 收集数据 - 实验分析 - 得出结论),先获取学生的得分或者能力作为衡量标准,再使用主成分分析、线性回归等方法对教育情境信息的作用进行分析。其中学生得分可比要求学生所做练习相同,因此在大规模的情境信息分析中,往往采用基于传统认知诊断理论得到的学生能力作为衡量的方式。
认知诊断研究可以追溯到教育心理学领域,代表性的工作有项目反映理论(Item Response Theory,IRT)。近年来,随着人工智能以及智慧教育的兴起,作为智慧教育应用的基础任务之一,基于机器学习、深度学习的认知诊断方法被广泛研究,其中经典的工作有将项目反映理论拓展的多维项目反映理论(Multidimensional Item Response Theory,MIRT),使用神经网络学习认知函数的神经认知诊断框架(Neural Cognitive Diagnosis,NeuralCD)。然而,目前认知诊断的工作往往只关注于试题相关信息(如试题知识点矩阵、知识点的关系、试题文本等)的挖掘,对于学生学习过程相关的教育情境信息则关注很少。
此外,虽然使用认知诊断结果一定程度上能解决教育情境信息分析中的可比性问题,但传统教育领域的研究方式依然存在误差传递、影响难以量化等问题。在这一背景下,该研究提出教育情境感知的认知诊断框架,期望使用神经网络以及端到端的训练框架,自适应学习不同教育情境信息的量化影响,并结合现有认知诊断工作的方法,增强诊断的结果。
教育情境感知的认知诊断
1、问题定义
设学习系统中有 N 个学生,T 个情境信息问题以及 M 个练习。学生集合
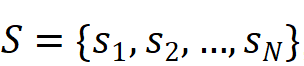
,情境问题集合
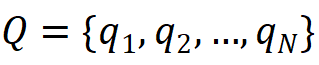
,练习问题集合
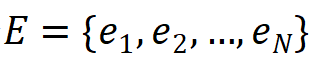
。学生的情境信息记录表示为三元组
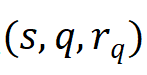
集合R_q;答题记录表示为
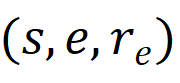
的集合R_e,其中
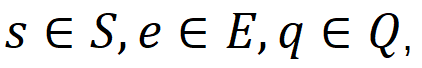
r_q与r_e分别是学生s对情境问题q的回答与在练习e上的得分。
给定学生s的记录
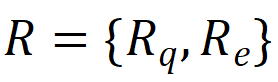
,该研究的目标是通过学生表现预测的过程,获取学生s的知识点掌握程度。
2、情境感知的认知诊断框架
几乎所有传统认知诊断方法都包括学生参数、试题参数、学生与试题交互函数这三个部分,其合理性已被大量工作验证。总体上,学生作答过程可以形式化为
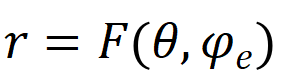
,其中
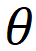
,
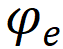
分别代表学生知识状态、练习相关参数(如难度,知识点),F为认知函数,r为学生表现。学生知识状态则可以进一步表示为:
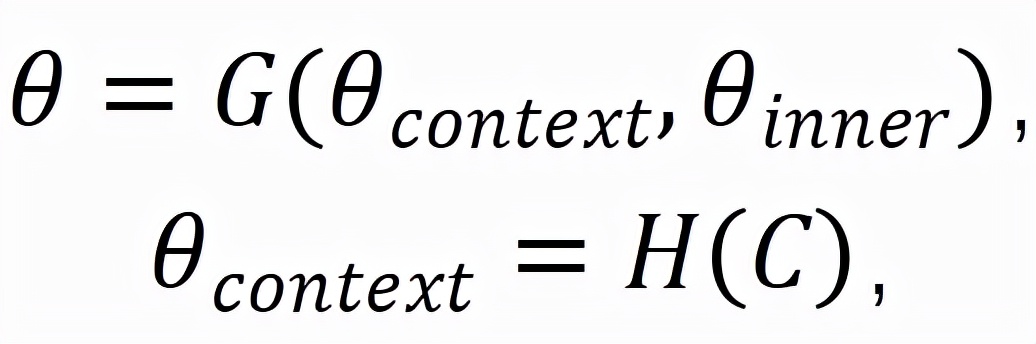
其中C为情境信息输入,H为情境影响函数,

,
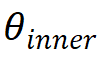
分别代表情境影响的外显特质与历史学习情况影响的学生内在特质,G代表学生特质对知识状态的映射函数。
该研究提出一个两阶段的框架:教育情境建模阶段与诊断强化阶段。
- 首先,在教育情境建模阶段中,该研究提出使用一个分层注意力网络建模情境输入对学生知识状态的外在影响表示 ,即建模情境影响函数H。具体网络结构在下小节介绍。
- 其次,在诊断强化阶段,该研究通过将学生参数(学生知识状态)形式化为情境信息影响的外显特质与历史学习情况影响的内在特质两部分的调和(映射函数G)。
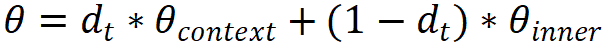
其中,d_t为学生 id 映射的权重参数,由网络学习。这样,情境信息表示能够对现有的认知诊断方法(认知函数F)进行拓展。该研究对认知诊断领域经典的 IRT、MIRT 以及 NeuralCD 方法进行了拓展实现。
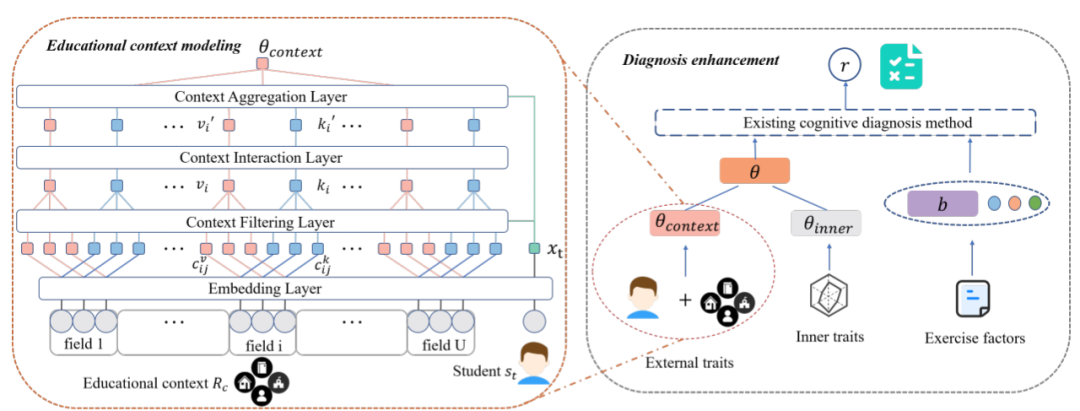
图表 3:ECD 模型框架
3、情境信息建模
教育情境信息主要包括以下特点:内容复杂性,个体差异性,内在相关性。其中内容复杂性指教育情境信息输入包含丰富来源的内容。个体差异性则是指同一情境信息对学生的影响也会因人而异。例如情境信息「接受辅导」对于学生的影响虽然总体上是积极的,但是对于勤奋的学生的影响往往要比贪玩的学生更明显(因为贪玩的学生很可能不会认真学习,从而无法充分利用这一积极条件)。内在相关性则是指不同情境信息之间也可能存在相互影响。比如「家庭条件」也可能影响「接受辅导」的效果。
针对上述特性,该研究首先根据内容将情境信息输入分成不同的分组,分别建模其影响。其次,该研究使用注意力机制计算学生特性与情境信息之间的相性,从而自适应学习不同情境信息对学生的影响权重。接着,该研究使用自注意力机制模块来模拟不同输入之间的相互影响情况。
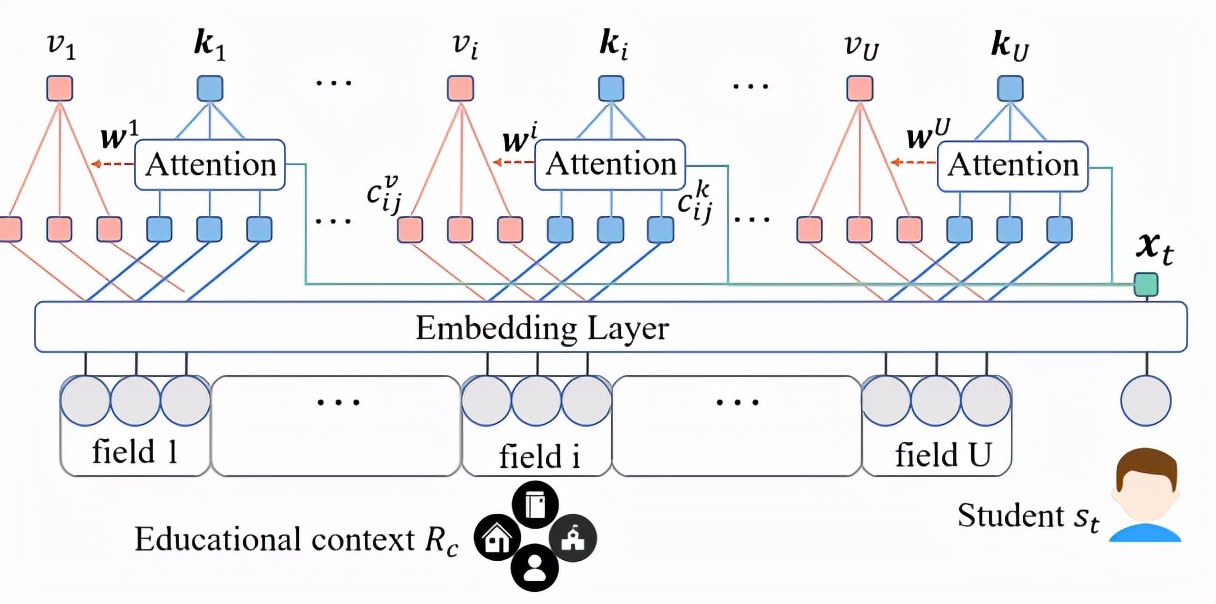
图表 4:Embedding 层与 Context filtering 层
具体来说,情境建模网络包含四层网络结构:嵌入(embedding)层、过滤(context filtering)层、交互(context interaction)层、聚合(context aggregation)层。该研究在嵌入层将每个情境信息输入r_q映射为情境影响向量c^v与情境特性向量c^k,将学生 id 输入t映射为个性向量x_t。在过滤层中,对于某一组情境信息的不同输入,该研究将学生个性表示x_t作为注意力机制中的查询 query,将情境特性表示c^k与情境影响表示c^v分别作为注意力机制中的键 key 与值 value。通过计算学生个性表示x_t与情境特性表示c^k的余弦相似度作为学生与特定情境输入的相性,进而分配组内不同情境输入影响c^v,以及该组情境特性c^k的权重,这样就能得到各组情境输入的影响表示v与特性表示k。
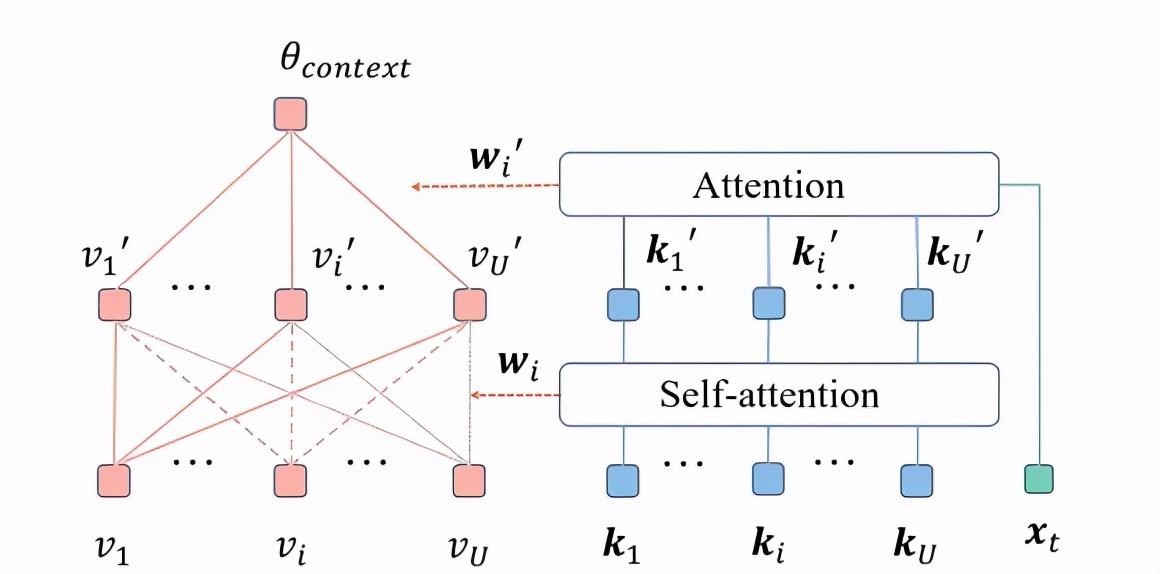
图表 5:Context interaction 层与 Context aggregation 层
在交互层中,类似的,该研究使用各组情境的影响表示v与特性k表示分别作为自注意力机制中的值 value 与键 key,从而得到交互后的各组情境输入的影响表示v'与特性表示k'。最后,在聚合层中,该研究依然使用个性表示x_t作为注意力机制中的查询 query,将各组情境输入的影响表示v'与特性表示k'分别作为自注意力机制中的值 value 与键 key,从而聚合各组情境输入,得到情境输入对学生的最终的影响表示
。
实验
实验使用的数据来自国际学生评估项目(Programme for International Student Assessment,PISA)2015 年的公开数据集(以下简称 PISA2015),包含来自 79 个国家与地区的学生的问卷数据与答题数据。PISA 项目是由世界经合组织(OECD)组织的国际学生评估项目,包含专家设计的与教育情境信息相关的学生问卷数据与学生在数学、科学、阅读等学科的测试作答数据,PISA 2015 的主要测试科目是科学,因此实验中使用学生在科学测试中的作答数据。该研究根据区域,将 PISA2015 的科学作答数据中抽取了三个数据集,分别是 Asia、Europe 与 America,具体的数据预处理可以参考论文内容,下表是数据集统计情况。
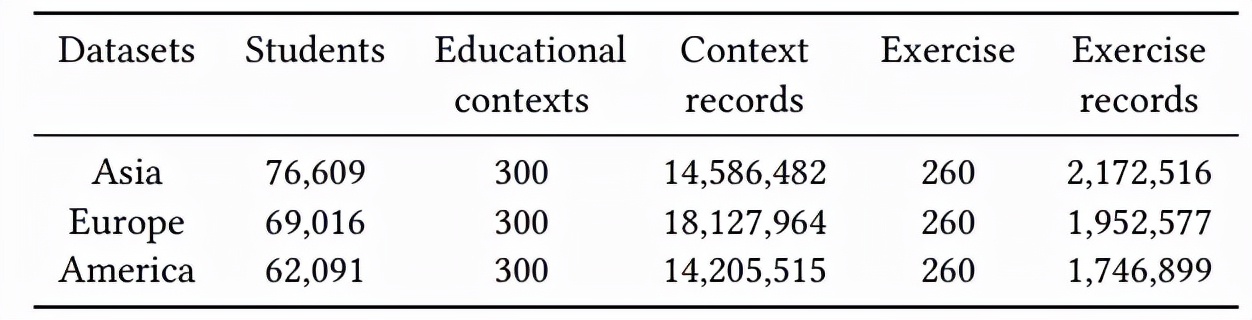
表格 1:数据集统计
1. 学生表现预测
学生真实的知识点熟练度标签是无法获取的,因此该研究采用间接衡量诊断结果准确性的方法,即使用学生的诊断结果来预测学生的在非训练数据中试题的得分,这也是传统认知诊断模型的常规做法。该研究实验的 baseline 包括两类,一类是没有情境信息强化的传统认知针对模型(如 NeuralCD,IRT 以及 MIRT),一类是基于该研究的二阶段框架,使用传统的上下文建模网络(如 Deep FM 与 NeuralFM 网络)对情境信息影响进行建模的模型。实验的结果如下表,该研究的 ECD-NeuralCD、ECD-IRT、ECD-MIRT 模型在不同区域的数据集中相较两类 baseline 取得了较大的提升。此外,随机模型(random)在不同数据集上 AUC 都在 0.5 左右,验证了数据集的样本分布情况是合理的。
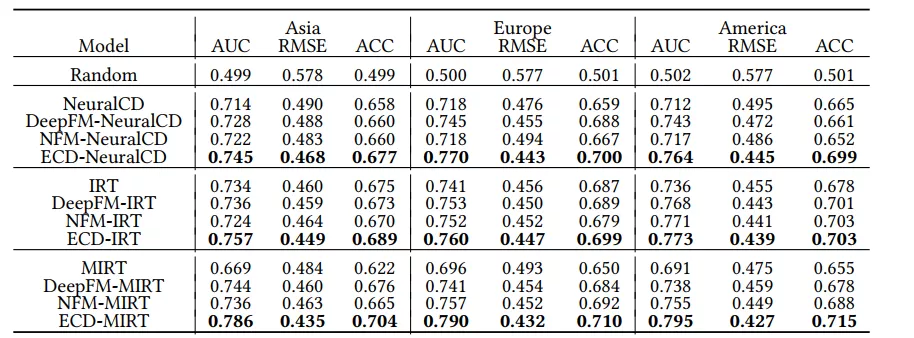
表格 2:学生表现预测
2. 消融实验
为了证明情境建模网络结构的合理性,该研究通过使用求和层代替情境建模网络中的各个网络层进行了消融实验,结果如下表。任何一层网络的取代都会降低最终的实验效果,并且聚合层的影响最为明显。
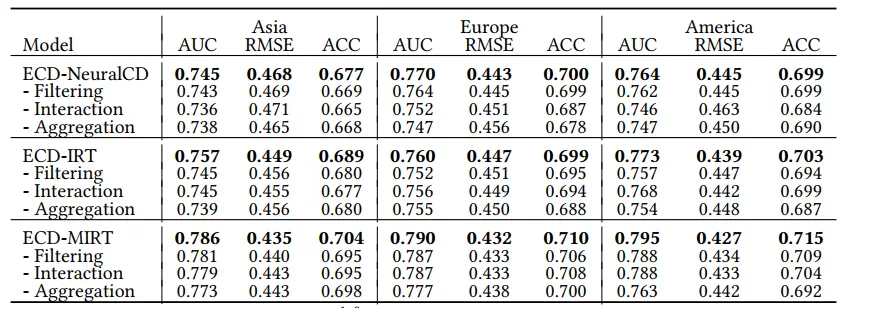
表格 3:消融实验
3. 参数解释性实验
为了进一步说明模型的可解释性,该研究还做了以下参数解释性实验:个性向量的可视化实验,过滤层的注意力模块可视化实验,情境信息影响的外显特质的权重的统计实验。
1)个性向量的可视化实验
该研究首先将学生个性向量使用 t-SNE 进行降维,并可视化为散点;接着对于每个散点,根据该学生在练习上的平均得分率(0~1)进行染色,可视化如图。可以看到,学习的个性向量的分布与学生的平均得分率之间是存在相关性的,这也与研究者的直觉一致。
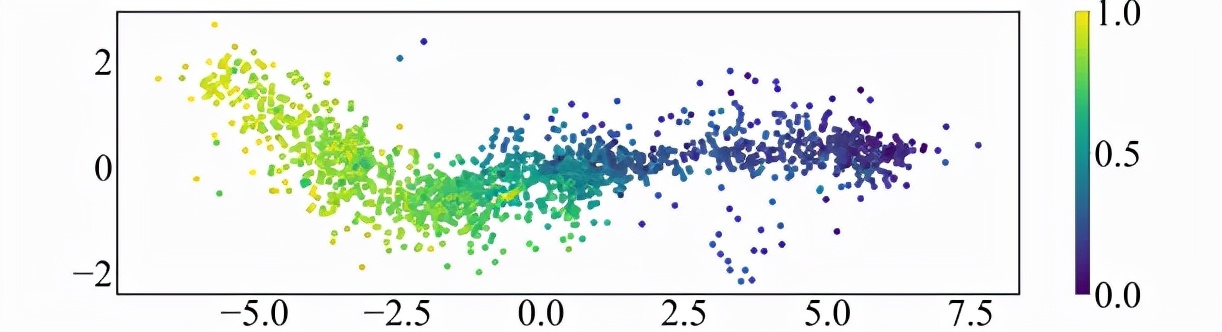
图表 6:学生个性向量可视化分析
2)过滤层注意力模块可视化
该研究选取了部分学生的情境输入的注意力权重进行可视化,其中 NO.0~4 的学生是平均得分率低的学生,NO.5~9 的学生有较高的得分率。研究者将其对应的情境输入编码(同一情境信息,编码越大的输入代表它对于学生的知识状态影响越积极)也可视化在图中。从 “Books” 信息的横向对比,可以看到低得分率的学生关注于较为消极的输入,而高得分率的学生则关注较为积极的输入;从 4、8、9 号学生的纵向对比,也可以得到类似的结论。这说明注意力模块的确模拟了情境信息与学生个性之间的相性。
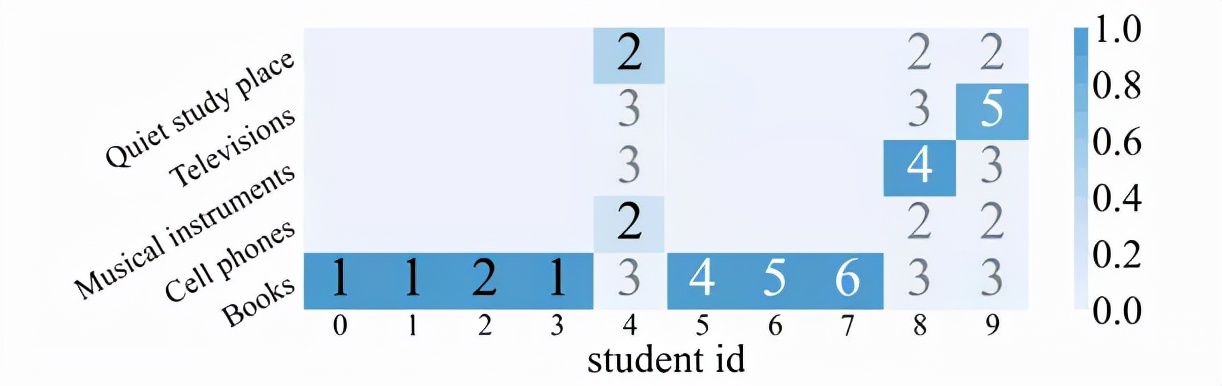
图表 7:注意力可视化
3)情境影响的权重
该研究统计了不同 ECD 模型实现中,以及 ECD-MIRT 中部分地区的各个学生参数的分布情况,结果绝大多数d_t都在 0.5 左右(0.4~0.6),说明情境信息影响的外显特质与学生历史学习情况的内在特质对学生最终的知识状态都有重要的影响。

图表 8:情境权重分析
4. 地区对比实验
最后,该研究也基于聚合(context aggregation)层中不同内容的情境影响的注意力权重,统计了各个学生 top-3 中要的情境信息,并分地区进行统计,结果如下表。其中有一些有意思的发现,教育资源相关情境信息在所有区域都很重要,例如家庭条件(Home ESCS)以及信息通信技术(ICT)相关的情境(PS:United States 区域缺少该部分的情境信息)。中韩地区会关注父母的受教育程度,研究者推测这可能与中韩相似的高考制度与氛围有关。而欧美地区对于在校学习相关的“School learning“与”Teacher Attitude“会比较关注,而亚洲地区对它们则不那么关注,研究者推测这可能与教学模式与教学目标之间的差异有关。
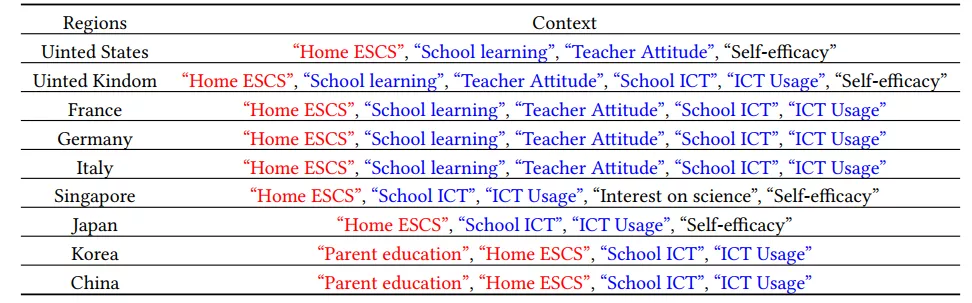
表格 4:不同地区关注的情境信息
随着智慧教育的兴起,认知诊断理论受到广泛的研究与发展。认知诊断结果能够为教育情境信息分析提供灵活的衡量指标,然而传统教育学实证研究的思路由于难以量化、误差传递的缺点,不适应当前的多学科、大数据量的场景。基于端到端的网络框架,用教育情境信息辅助认知诊断,进而分析教育情境信息作用是一个值得探索的方向。

























