前言
最近有空看了一点《js 高级程序设计》中变量和内存的章节,对变量和内存问题做了总结整理,其中包含了面试中一些老生常谈的问题,并且穿插了一些看似简单却一不小心就掉坑里的小代码题,假如你在面试中被问到,不知道能不能给面试官留下机敏过人的好印象呢?如果你也感兴趣,那就继续往下看吧。
本文涉及以下知识点
第一部分 变量
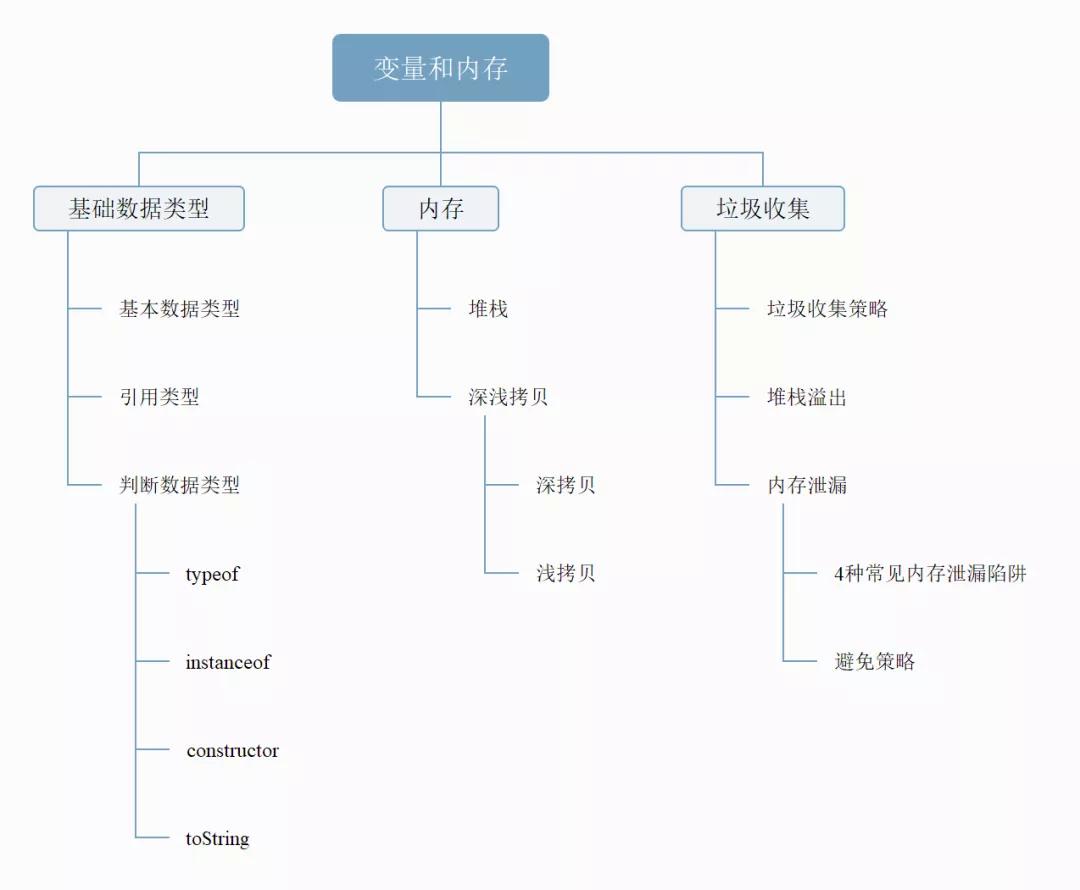
一 基础数据类型
8 种。undefined、Null、Boolean、Number、String、symbol、bigInt、object。
1.1 基本类型
7 种。undefined、Null、Boolean、Number、String、symbol、bigInt。其中两种较为特殊的稍作解释。
symbol
每个从Symbol()返回的 symbol 值都是唯一的。一个 symbol 值能作为对象属性的标识符;这是该数据类型仅有的目的。
- Symbol('1') == Symbol('1') // false
作为构造函数来说它并不完整,因为它不支持语法:new Symbol()。
- Symbol(1) //Symbol(1)
- new Symbol(1) // Uncaught TypeError: Symbol is not a constructor
Q1. 如果一个对象的 key 是用 Symbol 创建的,如何获取该对象下所有的 key ,至少说出两种?
A1. Object.getOwnPropertyNames Object.getOwnPropertySymbols 或者 Reflect.ownKeys
Q2. typeof Symbol 和 typeof Symbol()分别输出什么?
A2.
- typeof Symbol //"function"
- typeof Symbol() //"symbol"
bigInt
BigInt 是一种数字类型的数据,它可以表示任意精度格式的整数。目的是安全地使用更加准确的时间戳,大整数 ID 等,是 chrome 67 中的新功能。Number类型只能安全地表示-9007199254740991 (-(2^53-1)) 和9007199254740991(2^53-1)之间的整数,超出此范围的整数值可能失去精度。
- 9007199254740991 //9007199254740991
- 9007199254740992 //9007199254740992
- 9007199254740993 //9007199254740992 !!
创建BigInt在整数的末尾追加 n,或者调用BigInt()构造函数。
- 9007199254740993n //9007199254740993n
- BigInt('9007199254740993') //9007199254740993n
- BigInt(9007199254740993) //9007199254740992n !!
BigInt 和 Number不是严格相等的,但是宽松相等的。
- 9n == 9
- //true
- 9n === 9
- //false
1.2 引用类型
object 里面包含的 function、Array、Date、RegExp。
1.3 null 和 undefined 的区别
undefined读取一个没有被赋值的变量,null定义一个空对象,是一个不存在的对象的占位符
null和undefined转换成 number 数据类型结果不同。null转成0,undefined转成NaN
- new Number(null) //Number {0}
- new Number(undefined) //Number {NaN}
二 判断数据类型
2.1 typeof
只适用于判断基本数据类型(除null外)。null,表示一个空对象指针,返回object。对于对象来说,除了 function 能正确返回 function,其余也都返回object。
- var a;
- console.log(a);//undefined
- console.log(typeof a); //undefined
- typeof typeof 1 //"string"
2.2 instanceof
判断 A 是否是 B 的实例,A instanceof B,用于判断已知对象类型或自定义类型。
- function Beauty(name, age) {
- this.name = name;
- this.age = age;
- }
- var beauty = new Beauty("lnp", 18);
- beauty instanceof Beauty // true
Q1.
- Object instanceof Function // true
- Function instanceof Object // true
- Object instanceof Object // true
- Function instanceof Function // true
- instanceof 能够判断出 [] 是Array的实例,但它认为[ ] 也是Object的实例,因为它内部机制是通过对象的原型链判断的,在查找的过程中会遍历左边变量的原型链,直到找到右边变量的prototype,找得到就返回true。
- instanceof无法判断通过字面量创建的Boolean,Number,String类型,但是可以判断经new操作符创建的实例。
- instanceof可以判断通过字面量创建的引用类型Array,Object。
2.3 constructor
- constructor 属性返回对创建此对象的数组函数的引用。
constructor 不能用于判断undefined 与 null,因为它们没有构造函数。
实用场景小程序中,WXS 不支持使用 Array 对象,因此我们平常用于判断数组类型[] instanceof Array就不能使用了,而typeof []输出结果是object,并不能满足要求。这个时候就可以用constructor 属性进行类型判断:[].constructor === Array //true。
2.4 toString
Object.prototype.toString.call()判断某个对象属于哪种内置类型。是判断数据类型最严谨通用的方法。
- 判断基本类型
- Object.prototype.toString.call(null); // "[object Null]"
- Object.prototype.toString.call(undefined); // "[object Undefined]"
- Object.prototype.toString.call(true);// "[object Boolean]"
- Object.prototype.toString.call(123);// "[object Number]"
- Object.prototype.toString.call(“lnp”);// "[object String]"
- 判断原生引用类型
- // 函数类型
- Function Beauty(){console.log(“beautiful lnp”);}
- Object.prototype.toString.call(Beauty);//”[object Function]”
- // 日期类型
- var date = new Date();
- Object.prototype.toString.call(date);//”[object Date]”
- // 数组类型
- var arr = [1,2,3];
- Object.prototype.toString.call(arr);//”[object Array]”
- // 正则表达式
- var reg = /^[\d]{5,20}$/;
- Object.prototype.toString.call(arr);//”[object RegExp]”
- 判断原生 JSON 对象
- var isNativeJSON = window.JSON && Object.prototype.toString.call(JSON);
- console.log(isNativeJSON);//输出结果为”[object JSON]”说明 JSON 是原生的,否则不是
Q1.
- ({a:1}).toString() //返回什么
- ({a:1}).__proto__ === Object.prototype
- ({a:1}).toString() // [object Object]
- 对于 Object 对象,直接调用 toString() 就能返回 [object Object] 。而对于其他对象,则需要通过call来调用才能返回正确的类型信息。
小结

第二部分 内存
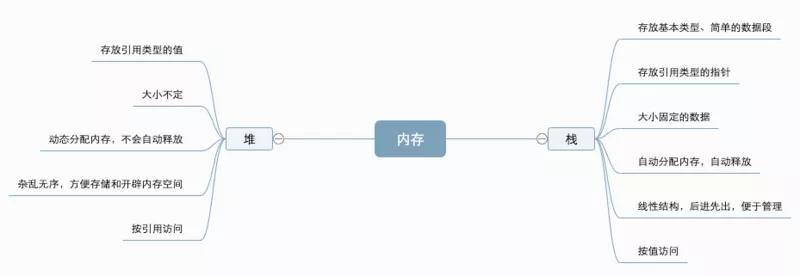
一 堆/栈
基本类型保存在栈内存,引用类型的值保存在堆内存,存储该值的地址(指针)保存在栈内存中,这是因为保存在栈内存的必须是大小固定的数据,而引用类型的大小不固定。
堆和栈的区别
二 深浅拷贝
2.1 数据类型的拷贝
Q1. 以下代码输出什么?
- 1 == 1;
- [] == []; //?
- {} == {}; //?
A1. 答对了吗?
- 1 == 1; //true
- [] == []; //false
- {} == {}; //false
原因:原始值的比较是值的比较,值相等时它们就相等(),值和类型都相等时它们就恒等(=) 对象(数组)的比较是引用的比较,即使两个对象包含同样的属性及相同的值,它们也是不相等的。
基本类型
图片复制的时候,在栈内存中重新开辟内存,存放变量 age2,所以在栈内存中分别存放着变量 age、age2 各自的值,修改时互不影响。
引用类型
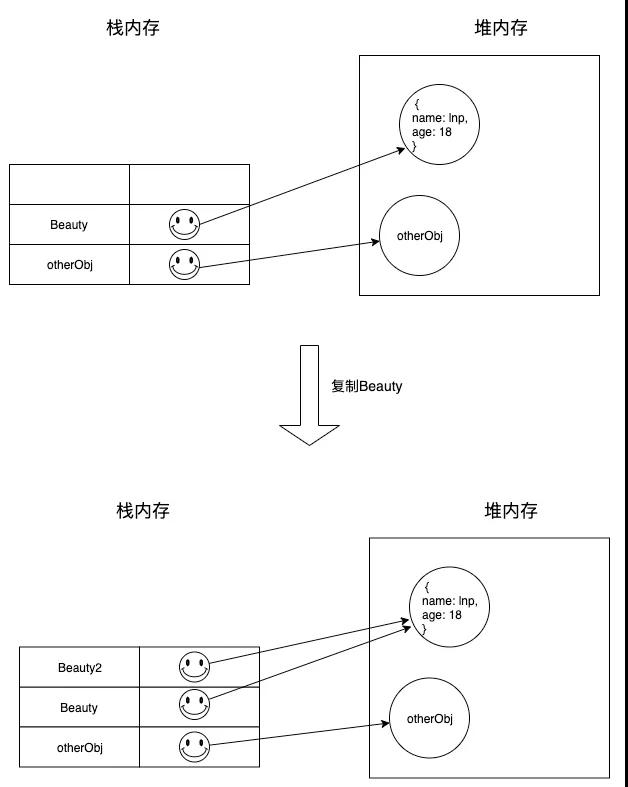
复制的时候,只复制了栈内存中存储的指针,Beauty 和 Beauty2 的指针指向的是堆内存中的同一个值。
连等赋值 a.x = a = {n:2}
理解了吗?那么题目中的问题就要来喽!准备好了吗?请看下面一小段代码... ...
- var a = {n:1};
- var b = a;
- a.x = a = {n:2}
- console.log(a.x);
- console.log(b.x);
- console.log(a);
- console.log(b);
- // 以上代码输出什么?
答(猜)对了吗?
- undefined
- {n: 2}
- {n: 2}
- {n: 1, x: {n: 2}}
解析我们先来还原一下这道题的执行过程。首先var a = {n:1}; 时,为变量 a 在堆内存中开辟了一块内存空间。图片
当var b = a; 时,将变量 b 的指针指向了堆内存中与 a 相同的内存空间。
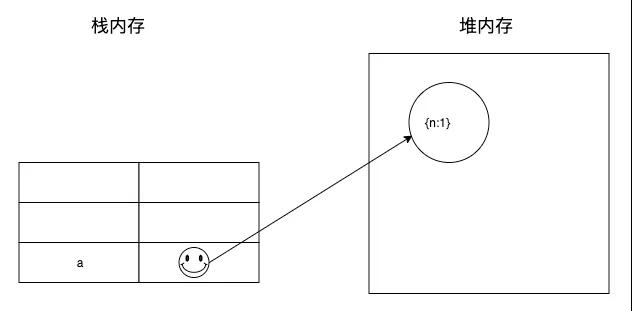
a.x = a = {n:2}中由于“.”是优先级最高的运算符,先计算a.x,a.x尚未定义,所以是undefined。
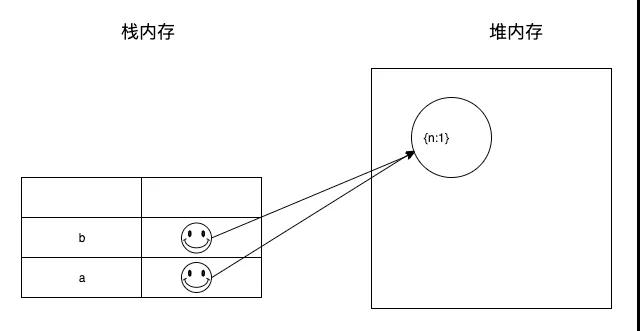
然后赋值运算按照从右往左的顺序解析,执行a = {n:2},a(一层变量)被重新赋值,指向一块新的内存空间。
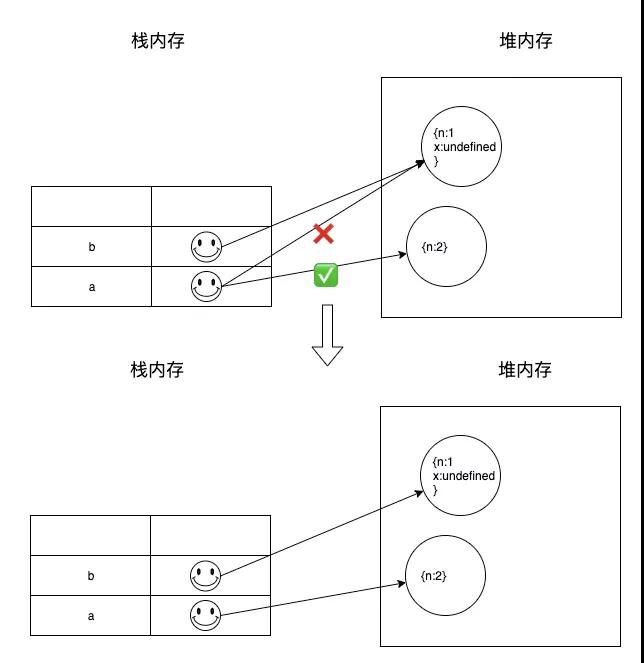
此时a.x,是指堆中已存在的内存 {n:1 x:undefined }的x属性,可以把a.x当作一个整体A,A的指向此时已经确定了,所以a的指向并不会影响a.x,执行a.x = a,则是把{n:2}赋值给{n:1 x:undefined }的x属性。
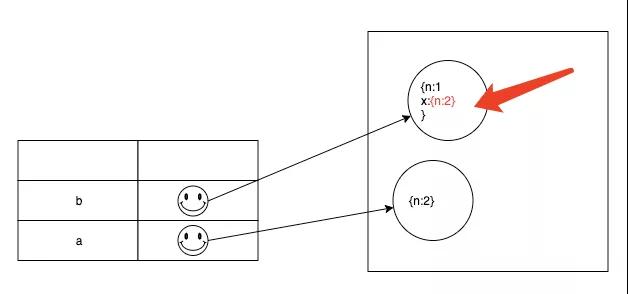
到这里函数执行完毕,那我们来看(a.x); (b.x); (a); (b); 分别指向什么就 一目了然了。
这个题考察以下 2 个知识点:
- object 类型数据在堆栈中的存储和赋值
- Javascript 中运算符的优先级
同理,来看一下把a.x = a = {n:2} 换成a = a.x = {n:2}呢?
- var a = {n:1};
- var b = a;
- a = a.x = {n:2}
- console.log(a.x);
- console.log(b.x);
- console.log(a);
- console.log(b);
答案是一样的,原理同上。
2.2 深拷贝和浅拷贝区别
- 浅拷贝 只复制指向某个对象的指针,而不复制对象本身,拷贝后新旧对象指向堆内存的同一个值,修改新对象对改变旧对象。
- 深拷贝 不但对指针进行拷贝,也对指针指向的值进行拷贝,也就是会另外创造一个一模一样的对象副本,新对象跟旧对象是各自独立的内存空间,修改新对象不会影响旧对象。
2.3 深拷贝和浅拷贝优劣,常用场景
- 深拷贝好处 避免内存泄漏:在对含有指针成员的对象进行拷贝时,使拷贝后的对象指针成员有自己的内存空间。
- 浅拷贝好处 如果对象比较大,层级也比较多,深拷贝会带来性能上的问题。在遇到需要采用深拷贝的场景时,可以考虑有没有其他替代的方案。在实际的应用场景中,也是浅拷贝更为常用。
2.4 实现深浅拷贝的方法和其弊端
深拷贝方法:
JSON.parse()与 JSON.stringify() 针对纯 JSON 数据对象,但是它只能正确处理的对象只有 Number, String, Boolean, Array, 扁平对象。
- let obj = {a:{b:22}};
- let copy = JSON.parse(JSON.stringify(obj));
- postMessage
- 递归
- lodash
浅拷贝方法:
- object.assign
- 扩展运算符...
- slice
- Array.prototype.concat()
2.5 总结
深浅拷贝只针对 Object, Array 这样的复杂对象,浅拷贝只复制一层对象的属性,而深拷贝则递归复制了所有层级。
第三部分 垃圾收集
javaScript 具有自动垃圾收集机制,也就是说,执行环境会负责管理代码执行过程中使用的内存。
那么,是不是我们就可以不管了呢?当然不是啊。开发人员只是无需关注内存是如何分配和回收的,但是仍然要避免自己的操作导致内存无法被跟踪到和回收。
垃圾收集
首先,我们来了解一下 js 垃圾回收的原理。在局部作用域中,函数执行完毕,局部变量就没有存在的必要了,因此可以释放他们的内存以供将来使用。这种情况,js 垃圾回收机制很容易做出判断并且回收。垃圾收集器必须跟踪哪个变量有用哪个没用,把不用的打上标记,等待将来合适时机回收。
js 的垃圾收集机制有两种,一种为标记清除,一种为引用计数。

所以对于全局变量,很难确认它什么时候不再需要。
内存泄漏 vs 堆栈溢出
什么是内存泄漏和堆栈溢出,二者关系是什么?
内存泄露是指你不再访问的变量,依然占据着内存空间。堆栈溢出是指调用即进栈操作过多,返回即出栈不够。关系:内存泄漏的堆积最终会导致堆栈溢出。
内存泄漏会导致什么问题?
运行缓慢,崩溃,高延迟
4 种常见的内存泄露陷阱
- 意外的全局变量,这些都是不会被回收的变量,特别是那些用来临时存储大量信息的变量(除非设置 null 或者被重新赋值)
- 定时器未销毁
- DOM 以外的节点引用
- 闭包(闭包的局部变量会一直保存在内存中)
2 种常见的堆栈溢出
- 递归
- 无限循环
内存泄漏避免策略
- 减少不必要的全局变量,或者生命周期较长的对象,及时解除引用(将不再使用的全局对象、全局对象属性设置为 null)
- 注意程序逻辑,避免“死循环”之类的
- 避免创建过多的对象
- 减少层级过多的引用
刘妮萍: 微医前端工程师。养鱼养花养狗,熬夜蹦迪喝酒。出走半生,归来仍是三年前端工作经验。