因为业务需要(项目技术栈为 spark 2+ ),七八月份兴冲冲从学校图书馆借了书,学了 scala + spark ,还写了不少博文,其中有几篇被拿来发推送:Scala,一门「特立独行」的语言!、【疑惑】如何从 Spark 的 DataFrame 中取出具体某一行? ...
但实际操作起来,还是遇到不少问题。
收获经验有二:
- 看书(尤其国内教材)理解理解概念还行,但是对于实际操作没啥大用
- 接触一门新的编程语言,首先应该阅读大量优秀的案例代码,还有理解清楚数据类型
举个例子,我昨天上午一直被这个纠缠着:请你给 spark 中 dataframe 的某一列数 取为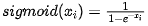 。
。
按理说不难吧。要是 python 的 pandas 就直接上了:
- # pandas
- df['sig_x'] = df['x'].apply(lambda x: 1 / (1 - np.exp(-x)))
但是 spark 不行。
spark 中,新建一列使用的函数是 withColumn ,首先传入函数名,接下来传入一个 col 对象。
这个 col 对象就有讲究了,虽然我今天看来还是比较直观好理解的,但是昨天可就在里面周旋了好一阵子。
首先,如果我想使用列 x ,我不可以直接 "x" ,因为这是一个字符串,我需要调用隐式转换的函数 $ ,而这个 $ 实际上在 spark.implicits._ 中。
值得注意的是, spark 是你的 SparkSession 实例。
上述内容不清楚,则需要花一阵子找资料。
- import spark.implicits._
- val df_new = df.withColumn("x_new", $"x")
上述代码构造了一个新 df_new 对象,其中有 x_new 列与 x 列,两列数值完全一致。
其次,我的运算函数在哪里找呢?
答案是 org.apache.spark.sql.functions ,因为是 col 对象,其可能没有重载与常数数据类型的 + - * / 运算符,因此,如果我们 1 - $"x" 可能会报错:因为 #"x" 是 col ,而 1 只是一个 Int 。
我们要做的就是把 1 变成一个 col :苦苦查阅资料后,我找到了 lit 方法,也是在 org.apache.spark.sql.functions 中。最终的方案如下。
- import spark.implicits._
- import org.apache.spark.sql.functions.{fit, exp, negate}
- val df_result = df_raw_result
- .withColumn("x_sig",
- lit(1.0) / (lit(1.0) + exp(negate($"x")))
- )
其实,实际的代码比上面的还要复杂,因为 "x" 列里面其实是一个 vector 对象,我直接 $"x"(0) 无法取出 $"x" 列中的向量的第一个元素,最后查到用 udf 可以实现列的函数。
- import spark.implicits._
- import org.apache.spark.sql.functions.{fit, exp, negate, udf}
- // 取向量中的第一个元素
- val getItem = udf((v: org.apache.spark.ml.linalg.DenseVector, i: Int) => v(i))
- val df_result = df_raw_result
- .withColumn("x_sig",
- lit(1.0) / (lit(1.0) + exp(negate(getItem($"x", lit(0)))))
- )
python 和 scala ?
看起来,似乎 python 下的操作更加简洁优雅,但我更喜欢用 scala 书写这种级别的项目。
原因很简单, scala 对于类型的严格要求已经其从函数式编程那里借鉴来的思想,让代码写得太爽了。大部分问题,编译期就能发现,而且配合上 IDEA 的自动补全,真的很舒服。
目前为止,还没有弄懂 udf 代表着什么,基础语法与框架思想这里还是有待查缺补漏。