大家好,我是对白。
由于最近对比学习实在太火了,在ICLR2020上深度学习三巨头 Bengio 、 LeCun和Hinton就一致认定自监督学习(Self-Supervised Learning)是AI的未来,此外,在各大互联网公司中的业务落地也越来越多,且效果还非常不错(公司里亲身实践),于是写了两篇有关对比学习的文章:
一篇是对比学习在CV与NLP领域中的研究进展,写得比较系统与全面,里面介绍了对比学习是什么,以及该技术如何应用在各个领域中,包括MoCo、SimCLR、BYOL、SwAV、SimCSE等;
另一篇则梳理了ICLR2021上对比学习在NLP领域六大方向中的应用,均收获了很多小伙伴们的私信,感兴趣的同学也可以看一看:
1.对比学习(Contrastive Learning)在CV与NLP领域中的研究进展
2.ICLR2021对比学习(Contrastive Learning)NLP领域论文进展梳理
本篇文章则梳理了对比学习在ICLR2021、ICLR2020和NIPS2020中非常值得大家一读的一些经典论文,构思非常巧妙,涵盖了CV和NLP领域,且与之前两篇文章中介绍的模型均不重叠。后续等NIPS2021论文公开后,也会持续更新并分享给大家,话不多说,开始进入正题叭。
对比学习(ICLR2021/2020)
值得一读的八篇论文
1.PCL

论文标题:Prototypical Contrastive Learning of Unsupervised Representations
论文方向:图像领域,提出原型对比学习,效果远超MoCo和SimCLR
论文来源:ICLR2021
论文链接:https://arxiv.org/abs/2005.04966
论文代码:https://github.com/salesforce/PCL
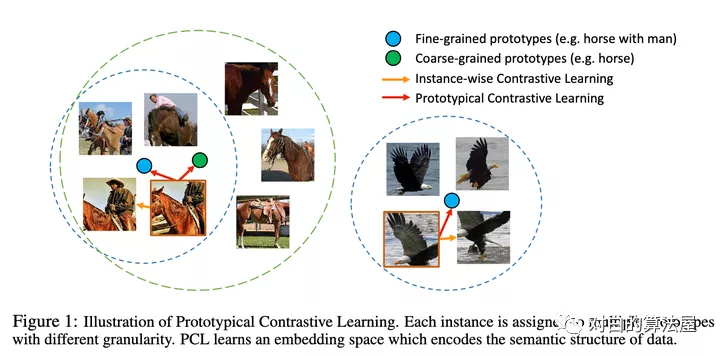
作者提出了原型对比学习(PCL),它是无监督表示学习的一种新方法,综合了对比学习和聚类学习的优点。
在 PCL 中,作者引入了一个「原型」作为由相似图像形成的簇的质心。将每个图像分配给不同粒度的多个原型。训练的目标是使每个图像嵌入更接近其相关原型,这是通过最小化一个 ProtoNCE 损失函数来实现的。
在高层次上,PCL 的目标是找到给定观测图像的最大似然估计(MLE)模型参数:
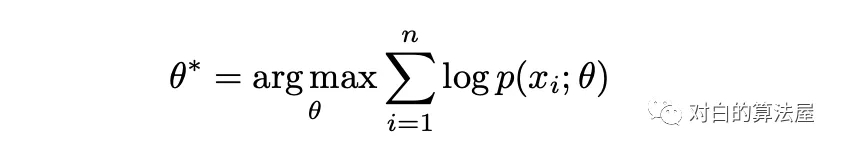
作者引入原型 c 作为与观测数据相关的潜在变量,提出了一种EM算法来求解最大似然估计。在 E-step 中,通过执行 K 平均算法估计原型的概率。在M步中,通过训练模型来最大化似然估计,从而最小化一个 ProtoNCE 损失:
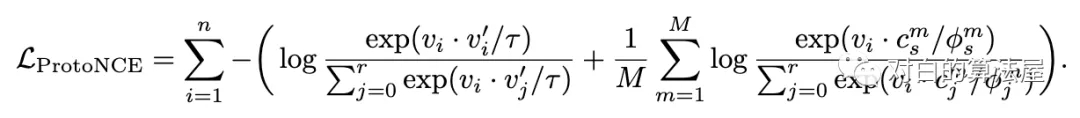
在期望最大化框架下,作者证明以前的对比学习方法是 PCL 的一个特例。
此外,作者在少样本迁移学习、半监督学习和目标检测三个任务上对 PCL 进行评估,在所有情况下都达到了SOTA的性能。
作者希望 PCL 可以扩展到视频,文本,语音等领域,让 PCL 激励更多有前途的非监督式学习领域的研究,推动未来人工智能的发展,使人工标注不再是模型训练的必要组成部分。
2.BalFeat

论文标题:Exploring Balanced Feature Spaces for Representation Learning
论文方向:图像领域,主要解决类别分布不均匀的问题
论文来源:ICLR2021
论文链接:https://openreview.net/forum?id=OqtLIabPTit
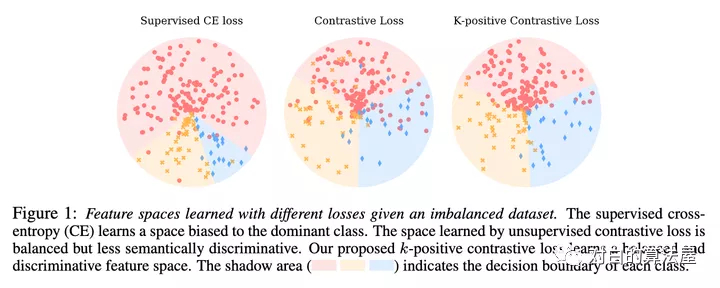
现有的自监督学习(SSL)方法主要用于训练来自人工平衡数据集(如ImageNet)的表示模型。目前还不清楚它们在实际情况下的表现如何,在实际情况下,数据集经常是不平衡的。基于这个问题,作者在训练实例分布从均匀分布到长尾分布的多个数据集上,对自监督对比学习和监督学习方法的性能进行了一系列的研究。作者发现与具有较大性能下降的监督学习方法不同的是,自监督对比学习方法即使在数据集严重不平衡的情况下也能保持稳定的学习性能。
这促使作者探索通过对比学习获得的平衡特征空间,其中特征表示在所有类中都具有相似的线性可分性。作者的实验表明,在多个条件下,生成平衡特征空间的表征模型比生成不平衡特征空间的表征模型具有更好的泛化能力。基于此,作者提出了k-positive对比学习,它有效地结合了监督学习方法和对比学习方法的优点来学习具有区别性和均衡性的表示。大量实验表明,该算法在长尾识别和正常平衡识别等多种识别任务中都具有优越性。
3.MiCE

论文标题:MiCE: Mixture of Contrastive Experts for Unsupervised Image Clustering
论文方向:图像领域,对比学习结合混合专家模型MoE,无需正则化
论文来源:ICLR2021
论文链接:https://arxiv.org/abs/2105.01899
论文代码:https://github.com/TsungWeiTsai/MiCE
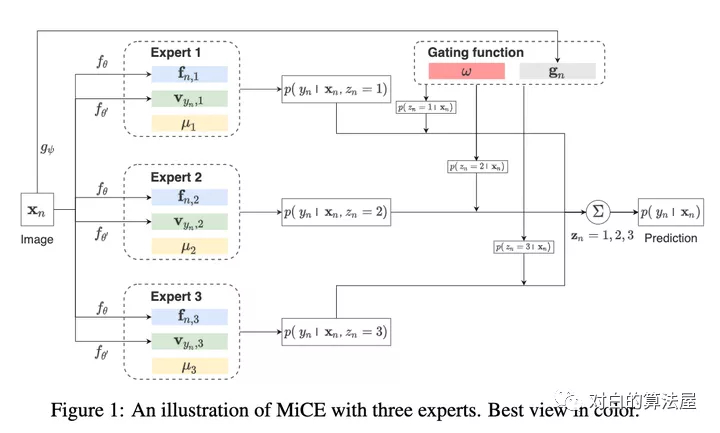
目前深度聚类方法都是使用two-stage进行构建,即首先利用pre-trained模型进行表示学习,之后再使用聚类算法完成聚类,但是由于这两个stage相互独立且现有的baseline在表示学习中并没有很好的建模语义信息,导致后面无法得到很好的聚类。
作者提出一个统一概率聚类模型Mixture of Contrastive Experts (MiCE),其同时利用了对比学习学习到的判别性表示(discriminative representation)和潜在混合模型获取的语义结构(semantic structures)。受多专家模型(mixture of experts ,MoE)启发,通过引入潜变量来表示图像的聚类标签,从而形成一种混合条件模型,每个条件模型(也称为expert)学习区分实例的子集,同时该模型采用门控函数(gating function)通过在专家之间分配权重,将数据集根据语义信息划分为子集。进一步,为了解决潜在变量引起的非简单推断(nontrivial inference)和其他训练问题,作者进一步构建了可扩展的EM算法,并给出了收敛性证明。其中E步,根据观测数据得到潜在变量后验分布的估计,M步最大化关于所有变量的对数条件似然。
MICE具有以下优点:
方法论上的统一:MICE结合了通过对比学习得到的判别性表示和通过统一概率框架内的潜在混合模型得到的语义结构的优点。
无需正则化:MICE仅通过EM进行优化,不需要任何其他的辅助loss和正则化loss。
Preliminary

Gate Function

Experts

在(5)式中,第一个instance-wise点积计算实例层次(instance-level)信息,以在每个expert中产生具有判别性的表示(discriminative representation),第二个instance-prototype点积将类别层次(class-level)信息整合到表示学习中,使之能够围绕prototype形成清晰的集群结构,因此产生的embedding具有语意结构同时有足够的判别性来表示不同实例
该式子基于MoCo和EMA构造,更多细节查看原文附录D。
4.i-Mix

论文标题:i-Mix: A Strategy for Regularizing Contrastive Representation Learning
论文方向:图像领域,少样本+MixUp策略来提升对比学习效果
论文来源:ICLR2021
论文链接:https://arxiv.org/abs/2010.08887
论文代码:https://github.com/kibok90/imix

对比表示学习已经证明了从未标记数据中学习表示是有效的。然而,利用领域知识精心设计的数据增强技术已经在视觉领域取得了很大进展。
作者提出了i-Mix,一个简单而有效的领域未知正则化策略,以改善对比表示学习。作者将 MixUp 技巧用在了无监督对比学习上,可有效提升现有的对比学习方法(尤其是在小数据集上):给每个样本引入虚拟标签,然后插值样本空间和 label 空间进行数据增强。实验结果证明了i-Mix在图像、语音和表格数据等领域不断提高表示学习的质量。
5.Contrastive Learning with Hard Negative Samples

论文标题:Contrastive Learning with Hard Negative Samples
论文方向:图像&文本领域,研究如何采样优质的难负样本
论文来源:ICLR2021
论文链接:https://arxiv.org/abs/2010.04592
论文代码:https://github.com/joshr17/HCL
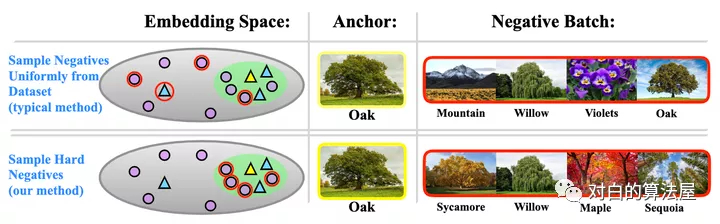
对比学习在无监督表征学习领域的潜力无需多言,已经有非常多的例子证明其效果,目前比较多的针对对比学习的改进包括损失函数、抽样策略、数据增强方法等多方面,但是针对负对的研究相对而言更少一些,一般在构造正负对时,大部分模型都简单的把单张图像及其增强副本作为正对,其余样本均视为负对。这一策略可能会导致的问题是模型把相距很远的样本分得很开,而距离较近的负样本对之间可能比较难被区分。
基于此,本文构造了一个难负对的思想,主要目的在于,把离样本点距离很近但是又确实不属于同一类的样本作为负样本,加大了负样本的难度,从而使得类与类之间分的更开,来提升对比学习模型的表现。
好的难负样本有两点原则:1)与原始样本的标签不同;2)与原始样本尽量相似。
这一点就与之前的对比学习有比较明显的差异了,因为对比学习一般来说并不使用监督信息,因此除了锚点之外的其他样本,不管标签如何,都被认为是负对,所以问题的一个关键在于“用无监督的方法筛出不属于同一个标签的样本”。不仅如此,这里还有一个冲突的地方,既要与锚点尽可能相似,又得不属于同一类,这对于一个无监督模型来说是有难度的,因此本文在实际实现过程中进行了一个权衡,假如对样本的难度要求不是那么高的时候,就只满足原则1,而忽略原则2。同时,这种方法应该尽量不增加额外的训练成本。
6.LooC

论文标题:What Should Not Be Contrastive in Contrastive Learning
论文方向:图像领域,探讨对比学习可能会引入偏差
论文来源:ICLR2021
论文链接:https://arxiv.org/abs/2008.05659
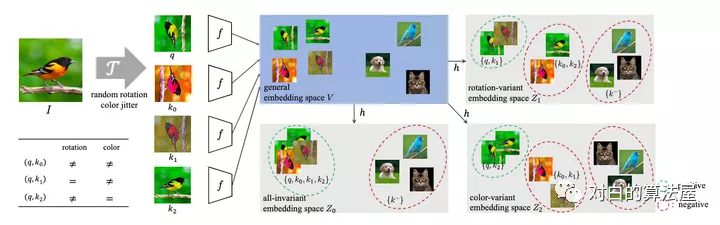
当前对比学习的框架大多采用固定的数据增强方式,但是对于不同的下游任务,不同的数据增强肯定会有不一样的效果,例如在数据增强中加入旋转,那么下游任务就会难以辨别方向,本文针对该问题进行研究。
如果要应用一个数据增强集合
到模型中,传统模型的做法是将图片数据进行两次独立的数据增强(数据增强参数具有一定随机性)。作者提出LooC,方法是执行 种数据增强,第一种是将图片数据进行两次独立的数据增强,也即是对所有数据增强方式全应用;剩下N种是将 参数固定,这样就保证了最终训练出来的模型会对
这种变换敏感,这n+1种数据增强方式最终会生成n+1种嵌入空间。最终loss如下:


作者发现原来的对比学习都是映射到同一空间,但是这样会有害学习其他的特征,所以作者把每个特征都映射到单独的特征空间,这个空间里都只有经过这一种数据增强的数据。
总而言之,数据增强是要根据下游任务来说的,分成不同的Embedding空间来适合多种不同的下游任务,但是对需要两种以上特征的下游任务效果可能就不好了。比如不仅仅需要结构信息,还需要位置。
7.CALM

论文标题:Pre-training Text-to-Text Transformers for Concept-centric Common Sense
论文方向:文本领域,利用对比学习和自监督损失,在预训练语言模型中引入常识信息
论文来源:ICLR2021
论文链接:https://openreview.net/forum?id=3k20LAiHYL2
论文代码:https://github.com/INK-USC/CALM
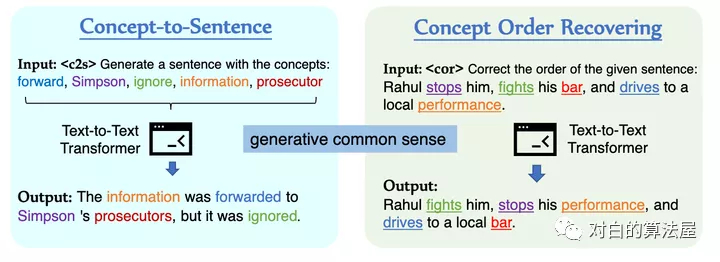
预训练语言模型 在一系列自然语言理解和生成任务中取得了令人瞩目的成果。然而,当前的预训练目标,例如Masked预测和Masked跨度填充并没有明确地对关于日常概念的关系常识进行建模,对于许多需要常识来理解或生成的下游任务是至关重要的。
为了用以概念为中心的常识来增强预训练语言模型,在本文中,作者提出了从文本中学习常识的生成目标和对比目标,并将它们用作中间自监督学习任务,用于增量预训练语言模型(在特定任务之前下游微调数据集)。此外,作者开发了一个联合预训练框架来统一生成和对比目标,以便它们可以相互加强。
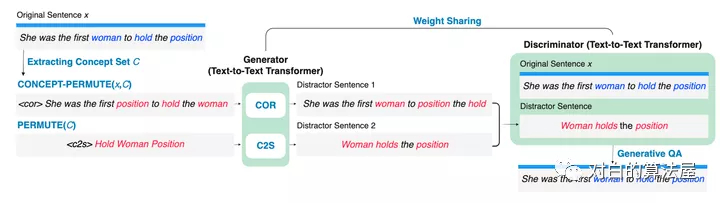
大量的实验结果表明,CALM可以在不依赖外部知识的情况下,将更多常识打包到预训练的文本到文本Transformer的参数中,在NLU和NLG 任务上都取得了更好的性能。作者表明,虽然仅在相对较小的语料库上进行了几步的增量预训练,但 CALM 以一致的幅度优于baseline,甚至可以与一些较大的 预训练语言模型相媲美,这表明 CALM 可以作为通用的“即插即用” 方法,用于提高预训练语言模型的常识推理能力。
8.Support-set bottlenecks for video-text representation learning

论文标题:Support-set bottlenecks for video-text representation learning
论文方向:多模态领域(文本+视频),提出了cross-captioning目标
论文来源:ICLR2021
论文链接:https://arxiv.org/abs/2010.02824
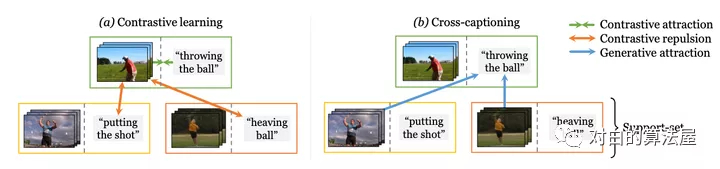
学习视频-文本表示的主流典范——噪声对比学习——增加了已知相关样本对的表示的相似性,例如来自同一样本的文本和视频,但将所有样本对都认为是负例。作者认为最后一个行为过于严格,即使对于语义相关的样本也强制执行不同的表示——例如,视觉上相似的视频或共享相同描述动作的视频。
在本文中,作者提出了一种新方法,通过利用生成模型将这些相关样本自然地推到一起来缓解这种情况:每个样本的标题必须重建为其他支持样本的视觉表示的加权组合。这个简单的想法确保表示不会过度专门用于单个样本,可以在整个数据集中重复使用,并产生明确编码样本之间共享语义的表示,这与噪声对比学习不同。作者提出的方法在 MSR-VTT、VATEX、ActivityNet 和 MSVD 的视频到文本和文本到视频检索方面明显优于其他方法。
Cross-modal discrimination和cross-captioning:作者的模型从两个互补的损失中学习:(a)Cross-modal 对比学习学习强大的联合视频文本的Embedding,但所有其他样本都被认为是负例,甚至推开语义相关的标题(橙色箭头)。(b) 我们引入了cross-captioning的生成任务,通过学习将样本的文本表示重构为支持集的加权组合,由其他样本的视频表示组成,从而缓解了这一问题。
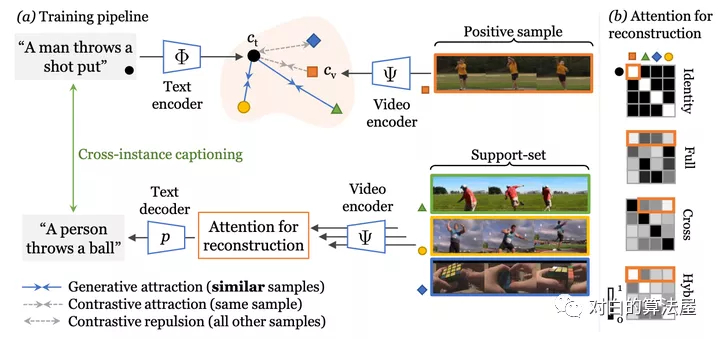
作者的cross-modal框架具有判别(对比)目标和生成目标。该模型学习将公共Embedding空间中的视频-文本对与文本和视频编码器(顶部)相关联。同时,文本还必须重建为来自支持集的视频Embedding的加权组合,通过Attention选择,这会强制不同样本之间的Embedding共享。
对比学习(NIPS2020)
非常经典的九篇论文
1.SpCL

论文标题:Self-paced Contrastive Learning with Hybrid Memory for Domain Adaptive Object Re-ID
论文方向:目标重识别,提出自步对比学习,在无监督目标重识别任务上显著地超越最先进模型高达16.7%
论文来源:NIPS2020
论文链接:https://arxiv.org/abs/2006.02713
论文代码:https://github.com/yxgeee/SpCL
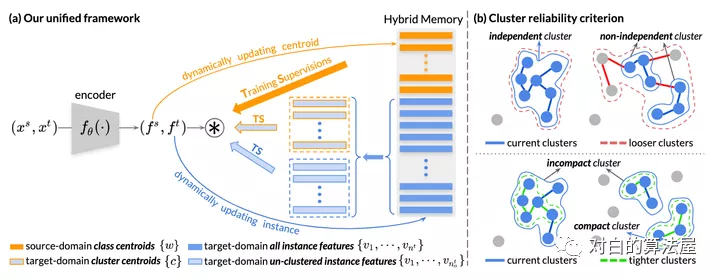
本文提出自步对比学习(Self-paced Contrastive Learning)框架,包括一个图像特征编码器(Encoder)和一个混合记忆模型(Hybrid Memory)。核心是混合记忆模型在动态变化的类别下所提供的连续有效的监督,以统一对比损失函数(Unified Contrastive Loss)的形式监督网络更新,实现起来非常容易,且即插即用。
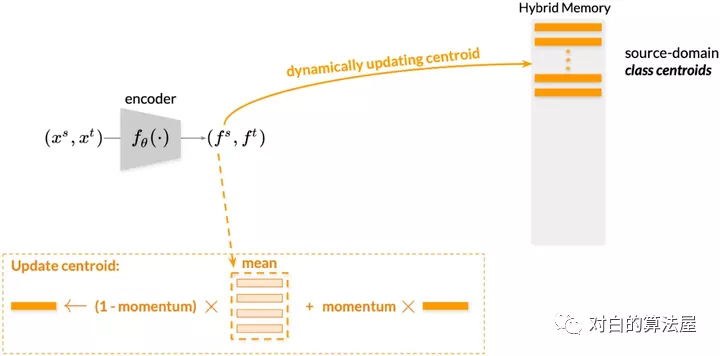
上文中提到混合记忆模型(Hybrid Memory)实时提供三种不同的类别原型,作者提出了使用动量更新(Momentum Update),想必这个词对大家来说并不陌生,在MoCo、Mean-teacher等模型中常有见到,简单来说,就是以“参数= (1-动量)x新参数+动量x参数”的形式更新。这里针对源域和目标域采取不同的动量更新算法,以适应其不同的特性。
对于源域的数据而言,由于具有真实的类别,作者提出以类为单位进行存储。这样的操作一方面节省空间,一方面在实验中也取得了较好的结果。将当前mini-batch内的源域特征根据类别算均值,然后以动量的方式累计到混合记忆模型中对应的类质心上去。对于目标域的数据而言,作者提出全部以实例为单位进行特征存储,这是为了让目标域样本即使在聚类和非聚类离群值不断变化的情况下,仍然能够在混合记忆模型中持续更新(Continuously Update)。具体而言,将当前mini-batch内的目标域特征根据实例的index累计到混合记忆模型对应的实例特征上去。
2.SimCLR V2(Hinton又一巨作)

论文标题:Big Self-Supervised Models are Strong Semi-Supervised Learners
论文方向:图像领域(Google出品)
论文来源:NIPS2020
论文链接:Big Self-Supervised Models are Strong Semi-Supervised Learners
论文代码:https://github.com/google-research/simclr
本文针对深度学习中数据集标签不平衡的问题,即大量的未标注数据和少量标注数据,作者提出了一种弱监督的模型SimCLRv2(基于SimCLRv1)。作者认为这种庞大的、极深的网络更能够在自监督的学习中获得提升。论文中的思想可以总结为一下三步:
1. 使用ResNet作为backbone搭建大型的SimCLRv2,进行无监督的预训练;
2. 然后在少量有标注的数据上进行有监督的finetune;
3. 再通过未标注的数据对模型进行压缩并迁移到特定任务上;
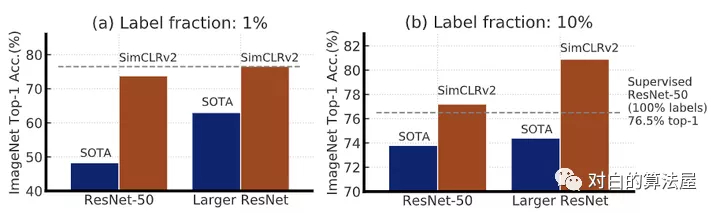
实验结果表明他们的模型对比SOTA是有很大的提升的:
作者采用SimCLR中的对比训练方法,即,最大化图片与其增强后(旋转、放缩、颜色变换等)之间的关联程度,通过优化在其隐空间上的对比损失,其公式如下:
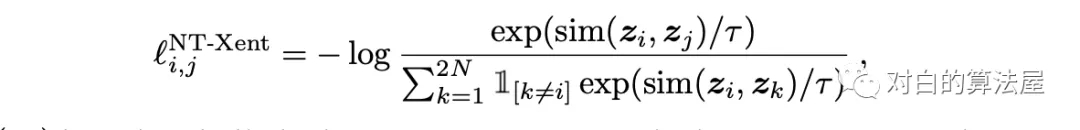
SimCLR V2的网络结构如下所示:
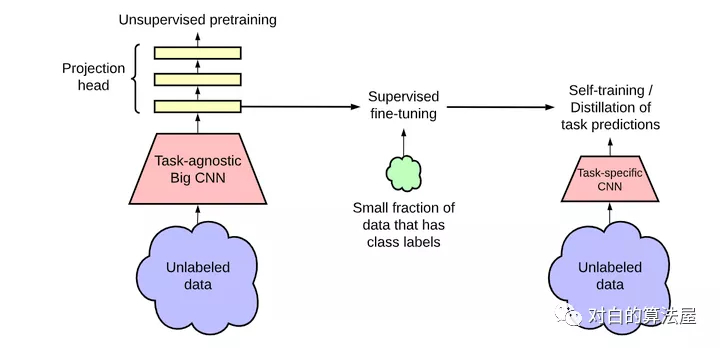
在SimCLR V2中,相比V1有一下几点改进:
V2大大加深了网络的规模,最大的规模达到了152层的ResNet,3倍大小的通道数以及加入了SK模块(Selective Kernels),据说在1%标注数据的finetune下可以达到29%的性能提升;
首先V2使用了更深的projection head;其次,相比于v1在预训练完成后直接抛弃projection head,V2保留了几层用于finetune,这也是保留了一些在预训练中提取到的特征;
使用了一种记忆机制(参考了这篇论文),设计一个记忆网络,其输出作为负样本缓存下来用以训练。
3.Hard Negative Mixing for Contrastive Learning

论文标题:Hard Negative Mixing for Contrastive Learning
论文方向:图像和文本领域,通过在特征空间进行 Mixup 的方式产生更难的负样本
论文来源:NIPS2020
论文链接:https://arxiv.org/abs/2010.01028
难样本一直是对比学习的主要研究部分,扩大 batch size,使用 memory bank 都是为了得到更多的难样本,然而,增加内存或batch size并不能使得性能一直快速提升,因为更多的负样本并不一定意味着带来更难的负样本。于是,作者通过Mixup的方式来产生更难的负样本。该文章对这类问题做了详尽的实验,感兴趣的可以阅读原论文。
4.Supervised Contrastive Learning

论文标题:Supervised Contrastive Learning
论文方向:提出了监督对比损失(Google出品,必属精品)
论文来源:NIPS2020
论文链接:https://arxiv.org/abs/2004.11362
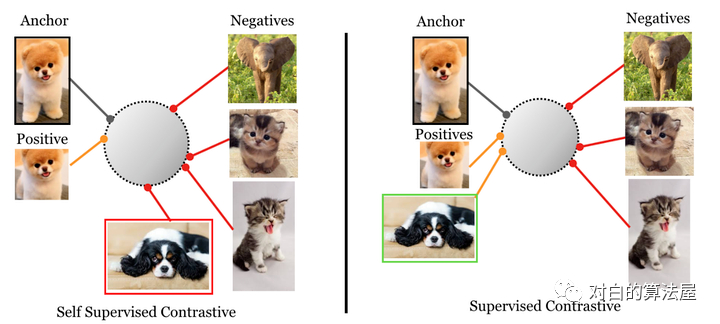
有监督方法vs自监督方法的对比损失:
supervised contrastive loss(左),将一类的positive与其他类的negative进行对比(因为提供了标签), 来自同一类别的图像被映射到低维超球面中的附近点。
self-supervised contrastive loss(右),未提供标签。因此,positive是通过作为给定样本的数据增强生成的,negative是batch中随机采样的。这可能会导致false negative(如右下所示),可能无法正确映射,导致学习到的映射效果更差。
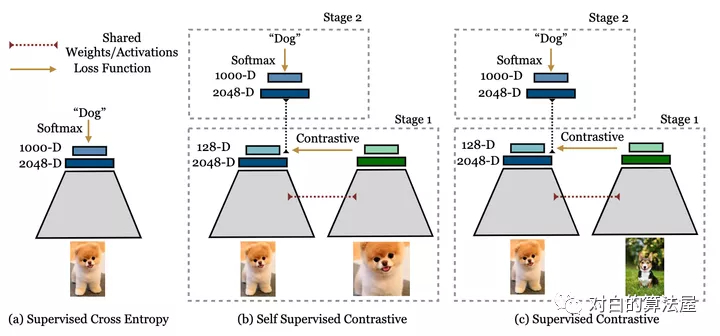
论文核心点:
其基于目前常用的contrastive loss提出的新的loss,(但是这实际上并不是新的loss,不是取代cross entropy的新loss,更准确地说是一个新的训练方式)contrastive loss包括两个方面:一是positive pair, 来自同一个训练样本 通过数据增强等操作 得到的两个feature构成, 这两个feature会越来越接近;二是negative pair, 来自不同训练样本的 两个feature 构成, 这两个feature 会越来越远离。本文不同之处在于对一个训练样本(文中的anchor)考虑了多对positive pair,原来的contrastive learning 只考虑一个。
其核心方法是两阶段的训练。如上图所示。从左向右分别是监督学习,自监督对比学习,和本文的监督对比学习。其第一阶段:通过已知的label来构建contrastive loss中的positive 和negative pair。因为有label,所以negative pair 不会有false negative(见图1解释)。其第二阶段:冻结主干网络,只用正常的监督学习方法,也就是cross entropy 训练最后的分类层FC layer。
实验方面,主要在ImageNet上进行了实验,通过accuracy验证其分类性能,通过common image corruption 验证其鲁棒性。
5.Contrastive Learning with Adversarial Examples

论文标题:Contrastive Learning with Adversarial Examples
论文方向:对抗样本+对比学习
论文来源:NIPS2020
论文链接:https://arxiv.org/abs/2010.12050
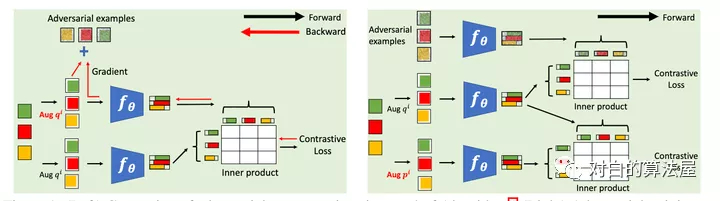
本文在标准对比学习的框架中,引入了对抗样本作为一种数据增强的手段,具体做法为在标准对比损失函数基础上,额外添加了对抗对比损失作为正则项,从而提升了对比学习基线的性能。简单来说,给定数据增强后的样本,根据对比损失计算对该样本的梯度,然后利用 FGSM (Fast Gradient Sign Method)生成相应的对抗样本,最后的对比损失由两个项构成,第一项为标准对比损失(两组随机增强的样本对),第二项为对抗对比损失(一组随机增强的样本以及它们的对抗样本),两项的重要性可指定超参数进行调节。
6.LoCo

论文标题:LoCo: Local Contrastive Representation Learning
论文方向:利用对比学习对网络进行各层训练
论文来源:NIPS2020
论文链接:https://arxiv.org/abs/2008.01342
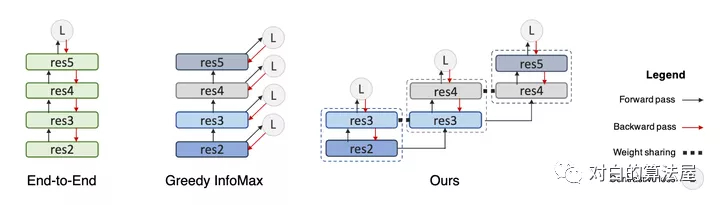
上图左边,展示了一个使用反向传播的常规端到端网络,其中每个矩形表示一个下采样阶段。在中间,是一个GIM,其中在每个阶级的末尾加上一个infoNCE损失,但是梯度不会从上一级流回到下一级。编码器早期的感受野可能太小,无法有效解决对比学习问题。由于相同的infoNCE损失被应用于所有的局部学习块(包括早期和晚期),早期阶段的解码器由于感受野有限,很难得到表征进行正确的区分正样本。例如,在第一阶段,我们需要在特征图上使用
的核执行全局平均池化,然后将其发送到解码器(非线性全连接)进行分类。
我们可以在解码器中加入卷积层来扩大感受野。然而,这种增加并没有对端到端的simclr产生影响,因为最后阶段的感受野足够很大。其实,通过在局部阶段之间共享重叠级,就我们可以有效地使解码器的感受野变大,而不会在前向传递中引入额外的成本,同时解决了文中描述的两个问题。
7.What Makes for Good Views for Contrastive Learning?

论文标题:What Makes for Good Views for Contrastive Learning?
论文方向:提出InfoMin假设,探究对比学习有效的原因(Google出品,必属精品)
论文来源:NIPS2020
论文链接:https://arxiv.org/abs/2005.10243
首先作者提出了三个假设:
- Sufficient Encoder
- Minimal Sufficient Encoder
- Optimal Representation of a Task其次,作者举了一个非常有趣的例子,如下图所示:
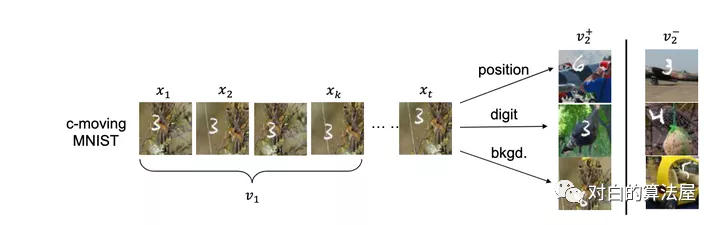
数字, 在某个随机背景上以一定速度移动, 这个数据集有三个要素:
- 数字
- 数字的位置
- 背景
左边的v1即为普通的view, 右边v2+是对应的正样本, 所构成的三组正样本对分别共享了数字、数字的位置和背景三个信息,其余两个要素均是随机选择,故正样本也仅共享了对应要素的信息. 负样本对的各要素均是随机选择的。
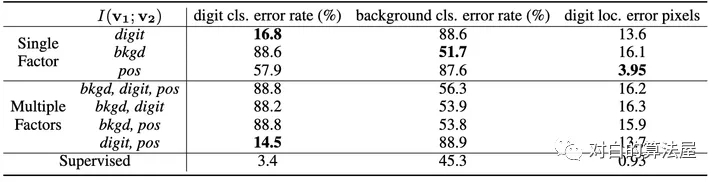
实验结果如上表,如果像文中所表述的,正样本对仅关注某一个要素, 则用于下游任务(即判别对应的元素,如判别出数字,判别出背景, 判别出数字的位置),当我们关注哪个要素的时候, 哪个要素的下游任务的效果就能有明显提升(注意数字越小越好)。
本文又额外做了同时关注多个要素的实验, 实验效果却并不理想, 往往是背景这种更为明显,更占据主导的地位的共享信息会被对比损失所关注。
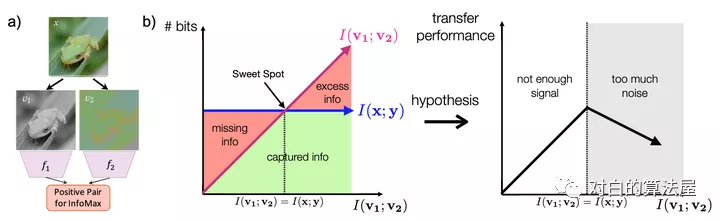
作者紧接着, 提出了一些构造 novel views 的办法。正如前面已经提到过的, novel views v1,v2应当是二者仅共享一些与下游任务有关的信息, 抓住这个核心。这样会形成一个U型,最高点定义为甜点,我们的目标就是让两个视图的信息能够刚好达到甜点,不多不少,只学到特定的特征。
8.GraphCL

论文标题:Graph Contrastive Learning with Augmentations
论文方向:图+对比学习
论文来源:NIPS2020
论文链接:https://arxiv.org/abs/2010.13902
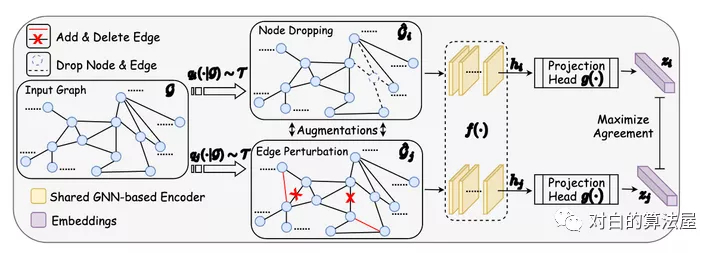
如上图所示,通过潜在空间中的对比损失来最大化同一图的两个扩充view之间的一致性,来进行预训练。
在本文中,作者针对GNN预训练开发了具有增强功能的对比学习,以解决图数据的异质性问题。
由于数据增强是进行对比学习的前提,但在图数据中却未得到充分研究,因此本文首先设计四种类型的图数据增强,每种类型都强加了一定的先于图数据,并针对程度和范围进行了参数化;
利用不同的增强手段获得相关view,提出了一种用于GNN预训练的新颖的图对比学习框架(GraphCL),以便可以针对各种图结构数据学习不依赖于扰动的表示形式;
证明了GraphCL实际上执行了互信息最大化,并且在GraphCL和最近提出的对比学习方法之间建立了联系;
证明了GraphCL可以被重写为一个通用框架,从而统一了一系列基于图结构数据的对比学习方法;
评估在各种类型的数据集上对比不同扩充的性能,揭示性能的基本原理,并为采用特定数据集的框架提供指导;
GraphCL在半监督学习,无监督表示学习和迁移学习的设置中达到了最佳的性能,此外还增强了抵抗常见对抗攻击的鲁棒性。
9.ContraGAN

论文标题:ContraGAN: Contrastive Learning for Conditional Image Generation
论文方向:条件图像生成领域
论文来源:NIPS2020
论文链接:https://arxiv.org/abs/2006.12681
论文代码:https://github.com/POSTECH-CVLab/PyTorch-StudioGAN
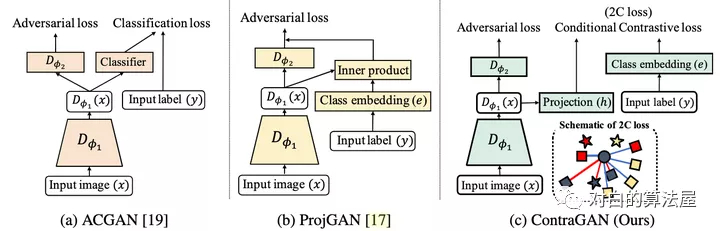
本文的方法是:判别器的大致结构和projGAN类似,首先输入图片x经过特征提取器D,得到特征向量;然后分两个分支,一个用于对抗损失判断图片是否真实,一个用于将特征经过一个projection head h 变成一个维度为k的向量(这个D+h的过程称为)。对于图片的类别,经过一个类别emmbedding变成一个也是维度为k的向量。
损失函数也是infoNCE loss 只不过使用类标签的嵌入作为相似,而不是使用数据扩充。
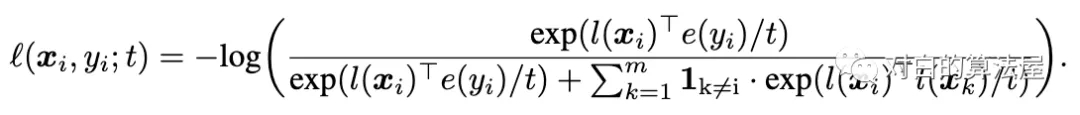
上面的损害将参考样本xi拉到更靠近嵌入e(yi)的类别,并将其他样本推开。但是这个loss可以推开具有与yi相同标签的被认为是负样本。因此,我们还要拉近具有相似类别的图片的距离:
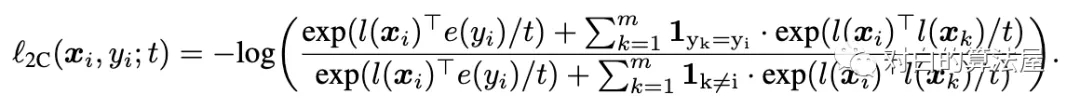
这样,就拉近图片和其类别的距离,同时拉近相同类别的图片的距离。
总结
对比学习已广泛应用在AI各个领域中,且作为自监督学习中的代表,效果甚至已经超越了很多有监督学习任务。很多互联网公司内部其实都有许许多多这样的业务需要大量人力进行标注,AI才能进行训练,从而得到一个不错的效果(无监督一般不敢上),而有了对比学习这个思想后,既能降本又能增效,AI炼丹师们终于可以开心的得到一个更好的效果,实现”技术有深度,业务有产出“这样的目标。期待对比学习这个领域诞生出更多好的作品,在各个应用方向开花结果,也期待NIPS2021的优秀论文们!