













Spark是加州大学伯克利分校的AMP实验室开源的类似MapReduce的通用并行计算框架,拥有MapReduce所具备的分布式计算的优点。但不同于MapReduce的是,Spark更多地采用内存计算,减少了磁盘读写,比MapReduce性能更高。同时,它提供了更加丰富的函数库,能更好地适用于数据挖掘与机器学习等分析算法。
Spark在Hadoop生态圈中主要是替代MapReduce进行分布式计算,如下图所示。同时,组件SparkSQL可以替换Hive对数据仓库的处理,组件Spark Streaming可以替换Storm对流式计算的处理,组件Spark ML可以替换Mahout数据挖掘算法库。
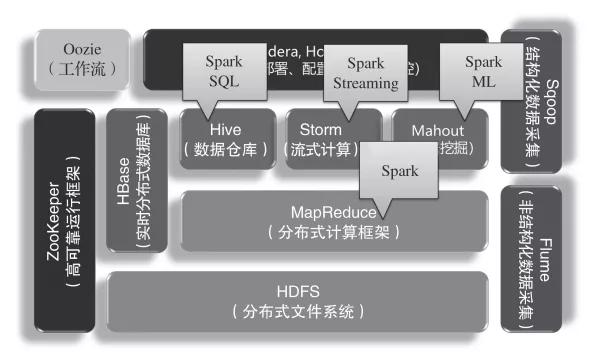
Spark在Hadoop生态圈中的位置
01Spark的运行原理
如今,我们已经不再需要去学习烦琐的MapReduce设计开发了,而是直接上手学习Spark的开发。这一方面是因为Spark的运行效率比MapReduce高,另一方面是因为Spark有丰富的函数库,开发效率也比MapReduce高。
首先,从运行效率来看,Spark的运行速度是Hadoop的数百倍。为什么会有如此大的差异呢?关键在于它们的运行原理,Hadoop总要读取磁盘,而Spark更多地是在进行内存计算,如下图所示。
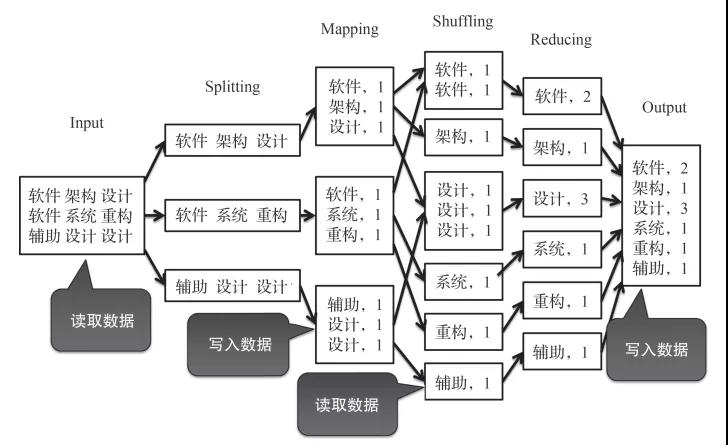
Hadoop的运行总是在读写磁盘
前面谈到,MapReduce的主要运算过程,实际上就是循环往复地执行Map与Reduce的过程。但是,在执行每一个Map或Reduce过程时,都要先读取磁盘中的数据,然后执行运算,最后将执行的结果数据写入磁盘。因此,MapReduce的执行过程,实际上就是读数据、执行Map、写数据、再读数据、执行Reduce、再写数据的往复过程。这样的设计虽然可以在海量数据中减少对内存的占用,但频繁地读写磁盘将耗费大量时间,影响运行效率。
相反,Spark的执行过程只有第一次需要从磁盘中读数据,然后就可以执行一系列操作。这一系列操作也是类似Map或Reduce的操作,然而在每次执行前都是从内存中读取数据、执行运算、将执行的结果数据写入内存的往复过程,直到最后一个操作执行完才写入磁盘。这样整个执行的过程中都是对内存的读写,虽然会大量占用内存资源,然而运行效率将大大提升。
Spark框架的运行原理如下图所示,Spark在集群部署时,在NameNode节点上部署了一个Spark Driver,然后在每个DataNode节点上部署一个Executor。Spark Driver是接收并调度任务的组件,而Executor则是分布式执行数据处理的组件。同时,在每一次执行数据处理任务之前,数据文件已经通过HDFS分布式存储在各个DataNode节点上了。因此,在每个节点上的Executor会首先通过Reader读取本地磁盘的数据,然后执行一系列的Transformation操作。每个Transformation操作的输入是数据集,在Spark中将其组织成弹性分布式数据集(RDD),从内存中读取,最后的输出也是RDD,并将其写入内存中。这样,整个一系列的Transformation操作都是在内存中读写,直到最后一个操作Action,然后通过Writer将其写入磁盘。这就是Spark的运行原理。
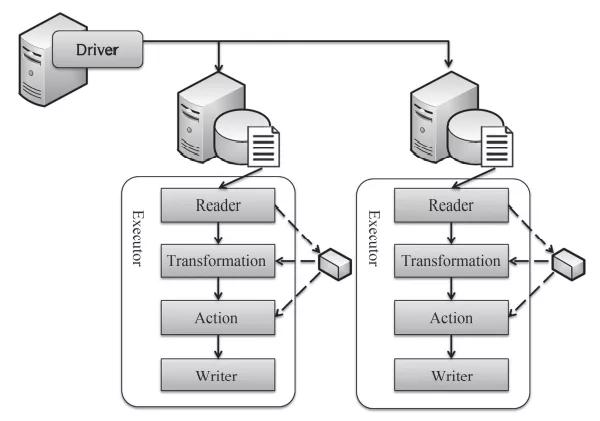
Spark框架的运行原理图
同时,Spark拥有一个非常丰富的函数库,许多常用的操作都不需要开发人员自己编写,直接调用函数库就可以了。这样大大提高了软件开发的效率,只用写更少的代码就能执行更加复杂的处理过程。在这些丰富的函数库中,Spark将其分为两种类型:转换(Transfer)与动作(Action)。
Transfer的输入是RDD,输出也是RDD,因此它实际上是对数据进行的各种Trans-formation操作,是Spark要编写的主要程序。同时,RDD也分为两种类型:普通RDD与名-值对RDD。
普通RDD,就是由一条一条的记录组成的数据集,从原始文件中读取出来的数据通常都是这种形式,操作普通RDD最主要的函数包括map、flatMap、filter、distinct、union、intersection、subtract、cartesian等。
名-值对RDD,就是k-v存储的数据集,map操作就是将普通RDD的数据转换为名-值对RDD。有了名-值对RDD,才能对其进行各种reduceByKey、joinByKey等复杂的操作。操作名-值对RDD最主要的函数包括reduceByKey、groupByKey、combineByKey、mapValues、flatMapValues、keys、values、sortByKey、subtractByKey、join、leftOuterJoin、rightOuterJoin、cogroup等。
所有Transfer函数的另外一个重要特征就是,它们在处理RDD数据时都不会立即执行,而是延迟到下一个Action再执行。这样的执行效果就是,当所有一系列操作都定义好以后,一次性执行完成,然后立即写磁盘。这样在执行过程中就减少了等待时间,进而减少了对内存的占用时间。
Spark的另外一种类型的函数就是Action,它们输入的是RDD,输出的是一个数据结果,通常拿到这个数据结果就要写磁盘了。根据RDD的不同,Action也分为两种:针对普通RDD的操作,包括collect、count、countByValue、take、top、reduce、fold、aggregate、foreach等;针对名-值对RDD的操作,包括countByKey、collectAsMap、lookup等。
02Spark的设计开发
Spark的设计开发支持3种语言,Scala、Python与Java,其中Scala是它的原生语言。Spark是在Scala语言中实现的,它将Scala作为其应用程序框架,能够与Scala紧密集成。Scala语言是一种类似Java的函数式编程语言,它在运行时也使用Java虚拟机,可以与Java语言无缝结合、相互调用。同时,由于Scala语言采用了当前比较流行的函数式编程风格,所以代码更加精简,编程效率更高。
前面讲解的那段计算词频的代码如下:
1val textFile = sc.textFile("hdfs://...")
2val counts = textFile.flatMap(line => line.split(""))
3 .map(word => (word, 1))
4 .reduceByKey(_ + _)
5counts.saveAsTextFile("hdfs://...")
- 1.
- 2.
- 3.
- 4.
- 5.
为了实现这个功能,前面讲解的MapReduce框架需要编写一个Mapper类和一个Reducer类,还要通过一个驱动程序把它们串联起来才能够执行。然而,在Spark程序中通过Scala语言编写,只需要这么5行代码就可以实现,编程效率大大提升。这段代码如果使用Java语言编写,那么需要编写成这样:
1JavaRDD<String> textFile = sc.textFile("hdfs://...");
2JavaRDD<String> words = textFile.flatMap(
3 new FlatMapFunction<String, String>() {
4 public Iterable<String> call(String s) {
5 return Arrays.asList(s.split(" ")); }
6});
7JavaPairRDD<String, Integer> pairs = words.mapToPair(
8 new PairFunction<String, String, Integer>() {
9 public Tuple2<String, Integer> call(String s) {
10 return new Tuple2<String, Integer>(s, 1); }
11});
12JavaPairRDD<String, Integer> counts= pairs.reduceByKey(
13 new Function2<Integer, Integer, Integer>() {
14 public Integer call(Integer a, Integer b) { return a + b; }
15});
16counts.saveAsTextFile("hdfs://...");
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
很显然,采用Scala语言编写的Spark程序比Java语言的更精简,因而更易于维护与变更。所以,Scala语言将会成为更多大数据开发团队的选择。
下图是一段完整的Spark程序,它包括初始化操作,如SparkContext的初始化、对命令参数args的读取等。接着,从磁盘载入数据,通过Spark函数处理数据,最后将结果数据存入磁盘。

完整的Spark程序
03Spark SQL设计开发
在未来的三五年时间里,整个IT产业的技术架构将会发生翻天覆地的变化。数据量疯涨,原有的数据库架构下的存储成本将越来越高,查询速度越来越慢,数据扩展越来越困难,因此需要向着大数据技术转型。
大数据转型要求开发人员熟悉Spark/Scala的编程模式、分布式计算的设计原理、大量业务数据的分析与处理,还要求开发人员熟悉SQL语句。
因此,迫切需要一个技术框架,能够支持开发人员用SQL语句进行编程,然后将SQL语言转化为Spark程序进行运算。这样的话,大数据开发的技术门槛会大大降低,更多普通的Java开发人员也能够参与大数据开发。这样的框架就是Spark SQL+Hive。
Spark SQL+Hive的设计思路就是,将通过各种渠道采集的数据存储于Hadoop大数据平台的Hive数据库中。Hive数据库中的数据实际上存储在分布式文件系统HDFS中,并将这些数据文件映射成一个个的表,通过SQL语句对数据进行操作。在对Hive数据库的数据进行操作时,通过Spark SQL将数据读取出来,然后通过SQL语句进行处理,最后将结果数据又存储到Hive数据库中。
1CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
2 [(col_name data_type [COMMENT col_comment], ...)]
3 [COMMENT table_comment]
4 [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
5 [CLUSTERED BY (col_name, col_name, ...)
6 [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
7 [ROW FORMAT row_format]
8 [STORED AS file_format]
9 [LOCATION hdfs_path]
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
首先,通过以上语句在Hive数据库中建表,每个表都会在HDFS上映射成一个数据库文件,并通过HDFS进行分布式存储。完成建表以后,Hive数据库的表不支持一条一条数据的插入,也不支持对数据的更新与删除操作。数据是通过一个数据文件一次性载入的,或者通过类似insert into T1 select * from T2的语句将查询结果载入表中。
1# 从NameNode节点中加载数据文件
2LOAD DATA LOCAL INPATH './examples/files/kv1.txt' OVERWRITE INTO TABLE pokes;
3# 从NameNode节点中加载数据文件到分区表
4LOAD DATA LOCAL INPATH './examples/files/kv2.txt'
5OVERWRITE INTO TABLE invites PARTITION (ds='2008-08-15');
6# 从HDFS中加载数据文件到分区表
7LOAD DATA INPATH '/user/myname/kv2.txt' OVERWRITE
8INTO TABLE invites PARTITION (ds='2008-08-15');
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
加载数据以后,就可以通过SQL语句查询和分析数据了:
1SELECT a1, a2, a3 FROM a_table
2LEFT JOIN | RIGHT JOIN | INNER JOIN | SEMI JOIN b_table
3ON a_table.b = b_table.b
4WHERE a_table.a4 = "xxx"
- 1.
- 2.
- 3.
- 4.
注意,这里的join操作除了有左连接、右连接、内连接以外,还有半连接(SEMI JOIN),它的执行效果类似于in语句或exists语句。
有了Hive数据库,就可以通过Spark SQL去读取数据,然后用SQL语句对数据进行分析了:
1import org.apache.spark.sql.{SparkSession, SaveMode}
2import java.text.SimpleDateFormat
3object UDFDemo {
4 def main(args: Array[String]): Unit = {
5 val spark = SparkSession
6 .builder()
7 .config("spark.sql.warehouse.dir","")
8 .enableHiveSupport()
9 .appName("UDF Demo")
10 .master("local")
11 .getOrCreate()
12
13 val dateFormat = new SimpleDateFormat("yyyy")
14 spark.udf.register("getYear", (date:Long) => dateFormat.format(date).toInt)
15 val df = spark.sql("select getYear(date_key) year, * from etl_fxdj")
16 df.write.mode(SaveMode.Overwrite).saveAsTable("dw_dm_fx_fxdj")
17 }
18}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
在这段代码中,首先进行了Spark的初始化,然后定义了一个名为getYear的函数,接着通过spark.sql()对Hive表中的数据进行查询与处理。最后,通过df.write.mode().saveAsTable()将结果数据写入另一张Hive表中。其中,在执行SQL语句时,可以将getYear()作为函数在SQL语句中调用。
有了Spark SQL+Hive的方案,在大数据转型的时候,实际上就是将过去存储在数据库中的表变为Hive数据库的表,将过去的存储过程变为Spark SQL程序,将过去存储过程中的函数变为Spark自定义函数。这样就可以帮助企业更加轻松地由传统数据库架构转型为大数据架构。
本书摘编自《架构真意:企业级应用架构设计方法论与实践》,经出版方授权发布。



















