在 CV 领域,人体姿态估计(human pose estimation)利用目标检测模型和姿态估计模型来识别出人体各个关节的位置和网格,并已在动作识别、动画、游戏、运动捕捉系统中有着广泛的应用。
但遗憾的是,人体姿态估计常常见诸于学术研究中,普通读者很难亲身体验它的神奇成像效果。
近日,机器之心在 GitHub 上发现了一个有趣的项目「air-drawing」,作者创建了一个利用深度学习的工具,使你在配有摄像头的电脑端可以获得自己的手势姿态估计成像图。
项目地址:https://github.com/loicmagne/air-drawing
此外,作者使用的深度学习模型还可以预测「向上」或「向下」的手势动作。动态效果展示图如下:

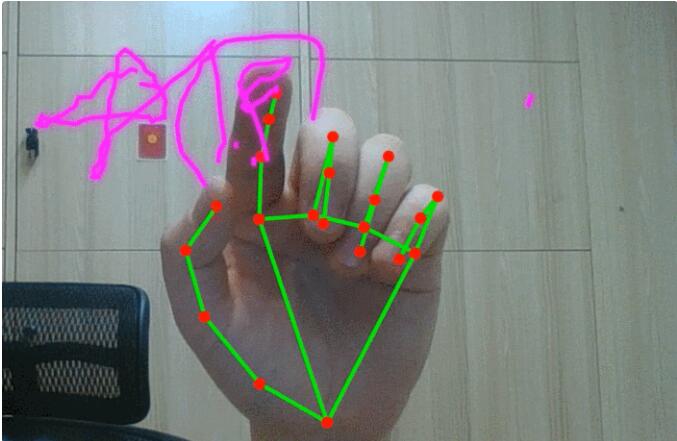
小编也尝试在自己的电脑上捕捉到了手势姿态估计网格图:
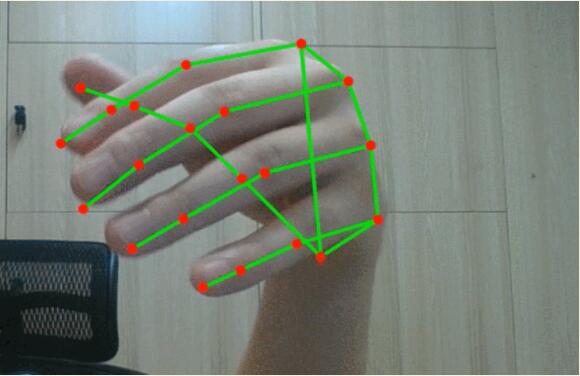
然后试着写了两个字「中国」,不知各位读者认得出来吗?!
试玩地址:https://loicmagne.github.io/air-drawing/
作者表示,试玩过程中不会收集用户信息。作者还优化了代码,使得该工具可以在大多数电脑上运行。电脑上的网络摄像头质量会对成像效果产生影响,调高屏幕亮度有助于更快地触发摄像头,并提升快门速度和帧率。如果手部一部分在框架之外,则手部检测无法正常工作。在绘图写字时,保持手指向上,手指向下时会影响指尖的检测。
技术细节
这个可以隔空作画的工具使用深度学习来完成,实现 pipeline 包含两个步骤:手势检测以及预测所要画的图,这两个过程都是通过深度学习来完成的。其中,手势检测使用了手部追踪解决方案 MediaPipe toolbox。

MediaPipe toolbox 项目地址:
https://google.github.io/mediapipe/solutions/hands.html
绘图预测部分只用到了手指位置相关技术。输入是一个 2D 点序列(实际上,该项目使用的是手指的速度和加速度,而不是位置,来保持预测的平移不变),输出是二元分类「向上(pencil up)」或「向下(pencil down)」。
此外,项目作者还使用了简单的双向 LSTM 架构,并且做了一个小数据集(大约 50 个样本),数据标注使用「python-stuff/data-wrangling/」工具。一开始,项目作者想做一个实时的「向上 / 向下」预测,即在用户绘画的同时做出预测。然而,由于任务太难,导致结果很差,因此采用双向 LSTM。
关于深度学习 pipeline 细节,你可以在 jupyter-notebook 中的 python-stuff/deep-learning / 了解更多信息。
该应用程序可以在用户端使用,作者将 PyTorch 模型转换为. onnx,然后使用 ONNX Runtime,它非常方便,可以兼容很多层。
总体来说,这个 pipeline 还需要进一步完善,一些改进的想法包括:
- 使用更大的数据集和更多的用户数据;
- 对手指信号进行处理和平滑,减少对相机质量的依赖,提高模型的泛化能力。
作者答疑
可以隔空绘画的这个项目引来了众多网友的讨论,有人不禁感慨,「这太酷了!让我想起迪士尼的广告,他们会用发光的魔杖画出米老鼠的头。」

在网友表达惊喜的同时,也有人提出了自己的疑惑。项目作者在 reddit 上对部分网友的的疑问进行解答,我们列举其中一部分。
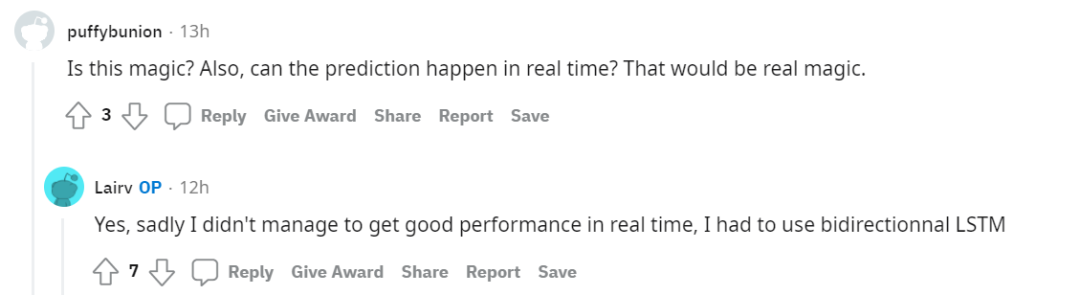
有网友表示,这是一个不错的项目,并有疑问——RNN 是从头开始训练的,还是在预训练模型的基础上进行微调的?
作者表示:「模型是从头开始训练的,但使用预训练模型可能是一个不错的建议。」
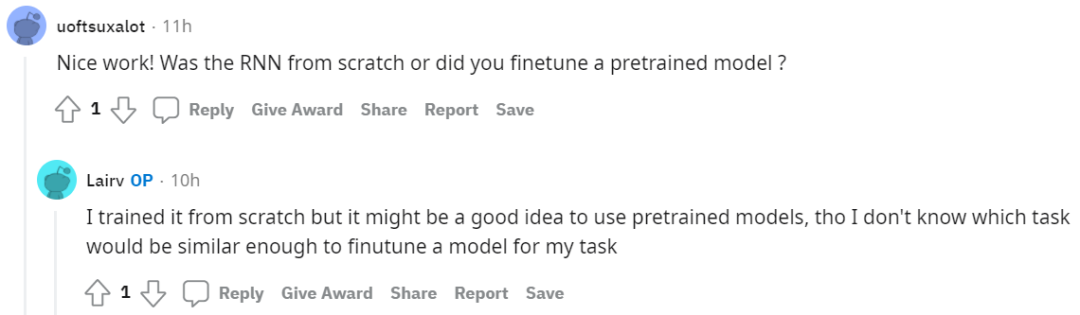
还有网友提问:「预测是实时的吗?那样的话,这将是一个真正的魔法。」
作者表示,预测是实时的。但遗憾的是,实时性能不是很好,所以必须使用双向 LSTM。
还有网友建议「使用 transformer 可以获得更好的性能」。
对于这个建议,作者表示自己曾尝试过自注意力层,但是结果并不理想。如果有一个更大数据集的话,采用 transformer 效果会更好。