本文作者喻兆靖,介绍了为什么 B 站选择 Flink + Hudi 的数据湖技术方案,以及针对其做出的优化。主要内容为:
1.传统离线数仓痛点
2.数据湖技术方案
3.Hudi 任务稳定性保障
4.数据入湖实践
5.增量数据湖平台收益
6.社区贡献
7.未来的发展与思考
一、传统离线数仓痛点
1. 痛点
之前 B 站数仓的入仓流程大致如下所示:
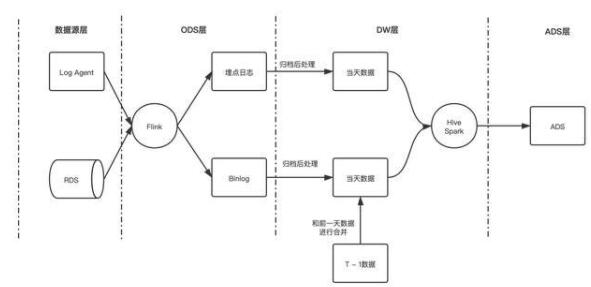
在这种架构下产生了以下几个核心痛点:
- 大规模的数据落地 HDFS 后,只能在凌晨分区归档后才能查询并做下一步处理;
- 数据量较大的 RDS 数据同步,需要在凌晨分区归档后才能处理,并且需要做排序、去重以及 join 前一天分区的数据,才能产生出当天的数据;
- 仅能通过分区粒度读取数据,在分流等场景下会出现大量的冗余 IO。
总结一下就是:
- 调度启动晚;
- 合并速度慢;
- 重复读取多。
2. 痛点思考
- 调度启动晚思路:既然 Flink 落 ODS 是准实时写入的,有明确的文件增量概念,可以使用基于文件的增量同 步,将清洗、补维、分流等逻辑通过增量的方式进行处理,这样就可以在 ODS 分区未归档的时 候就处理数据,理论上数据的延迟只取决于最后一批文件的处理时间。
- 合并速度慢思路:既然读取已经可以做到增量化了,那么合并也可以做到增量化,可以通过数据湖的能力结 合增量读取完成合并的增量化。
- 重复读取多思路:重复读取多的主要原因是分区的粒度太粗了,只能精确到小时/天级别。我们需要尝试一 些更加细粒度的数据组织方案,将 Data Skipping 可以做到字段级别,这样就可以进行高效的数 据查询了。
3. 解决方案: Magneto - 基于 Hudi 的增量数据湖平台
以下是基于 Magneto 构建的入仓流程:
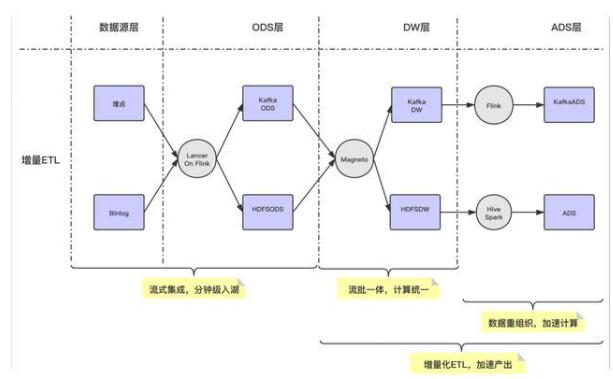
- Flow使用流式 Flow 的方式,统一离线和实时的 ETL Pipline
- Organizer数据重组织,加速查询支持增量数据的 compaction
- Engine计算层使用 Flink,存储层使用 Hudi
- Metadata提炼表计算 SQL 逻辑标准化 Table Format 计算范式
二、数据湖技术方案
1. Iceberg 与 Hudi 的取舍
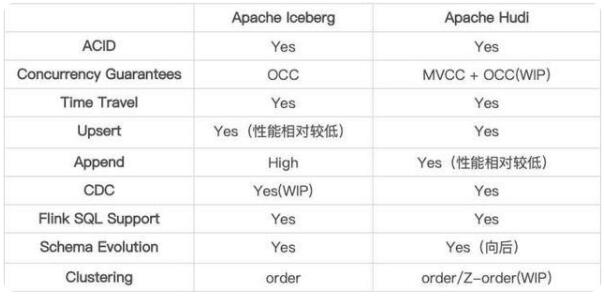
1.1 技术细节对比
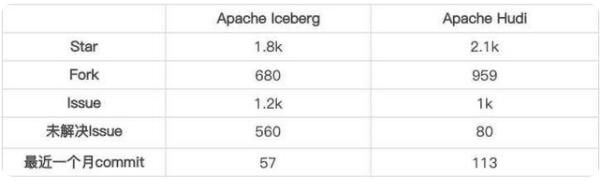
1.2 社区活跃度对比
统计截止至 2021-08-09
1.3 总结
大致可以分为以下几个主要纬度来进行对比:
- 对 Append 的支持Iceberg 设计之初的主要支持方案,针对该场景做了很多优化。 Hudi 在 0.9 版本中对 Appned 模式进行了支持,目前在大部分场景下和 Iceberg 的差距不大, 目前的 0.10 版本中仍然在持续优化,与 Iceberg 的性能已经非常相近了。
- 对 Upsert 的支持Hudi 设计之初的主要支持方案,相对于 Iceberg 的设计,性能和文件数量上有非常明显的优 势,并且 Compaction 流程和逻辑全部都是高度抽象的接口。 Iceberg 对于 Upsert 的支持启动较晚,社区方案在性能、小文件等地方与 Hudi 还有比较明显 的差距。
- 社区活跃度Hudi 的社区相较于 Iceberg 社区明显更加活跃,得益于社区活跃,Hudi 对于功能的丰富程度与 Iceberg 拉开了一定的差距。
综合对比,我们选择了 Hudi 作为我们的数据湖组件,并在其上继续优化我们需要的功能 ( Flink 更好的集成、Clustering 支持等)
2. 选择 Flink + Hudi 作为写入方式
我们选择 Flink + Hudi 的方式集成 Hudi 的主要原因有三个:
我们部分自己维护了 Flink 引擎,支撑了全公司的实时计算,从成本上考虑不想同时维护两套计算引擎,尤其是在我们内部 Spark 版本也做了很多内部修改的情况下。
Spark + Hudi 的集成方案主要有两种 Index 方案可供选择,但是都有劣势:Bloom Index:使用 Bloom Index 的话,Spark 会在写入的时候,每个 task 都去 list 一遍所有的文件,读取 footer 内写入的 Bloom 过滤数据,这样会对我们内部压力已经非常大的 HDFS 造成非常恐怖的压力。Hbase Index:这种方式倒是可以做到 O(1) 的找到索引,但是需要引入外部依赖,这样会使整个方案变的比较重。
我们需要和 Flink 增量处理的框架进行对接。
3. Flink + Hudi 集成的优化
3.1 Hudi 0.8 版本集成 Flink 方案
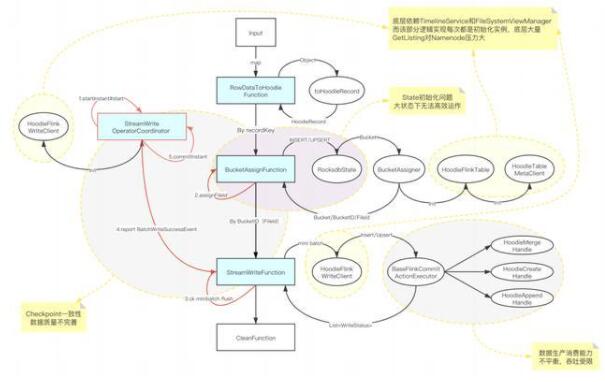
针对 Hudi 0.8 版本集成暴露出来的问题,B站和社区合作进行了优化与完善。
3.2 Bootstrap State 冷启动
背景:支持在已经存在 Hudi 表启动 Flink 任务写入,从而可以做到由 Spark on Hudi 到 Flink on Hudi 的方案切换
原方案:
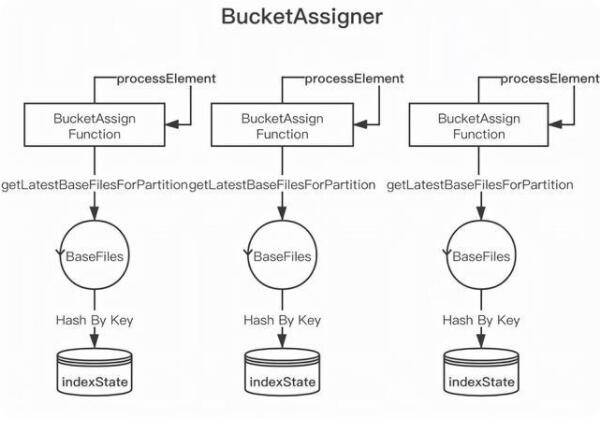
问题:每个 Task 处理全量数据,然后选择属于当前 Task 的 HoodieKey 存入 state 优化方案。
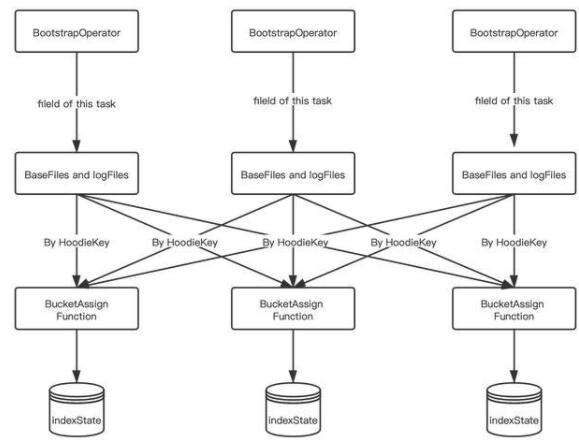
- 每个 Bootstrap Operator 在初始化时,加载属于当前 Task 的 fileId 相关的 BaseFile 和 logFile;
- 将 BaseFile 和 logFile 中的 recordKey 组装成 HoodieKey,通过 Key By 的形式发送给 BucketAssignFunction,然后将 HoodieKey 作为索引存储在 BucketAssignFunction 的 state 中。
效果:通过将 Bootstrap 功能单独抽出一个 Operator,做到了索引加载的可扩展性,加载速度提升 N (取决于并发度) 倍。
3.3 Checkpoint 一致性优化
背景:在 Hudi 0.8 版本的 StreamWriteFunction 中,存在极端情况下的数据一致性问题。
原方案:
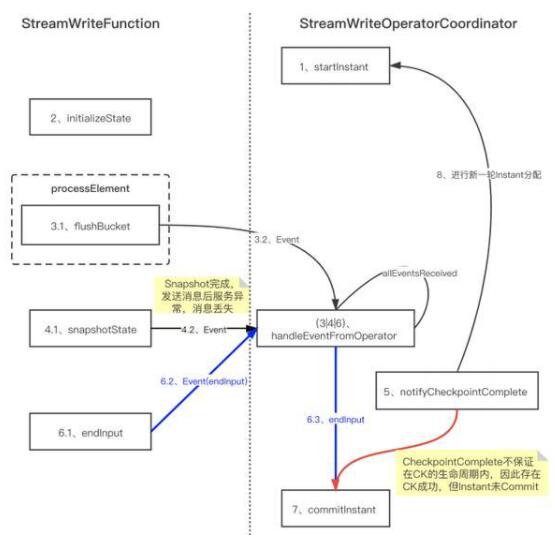
问题:CheckpointComplete不在CK生命周期内,存在CK成功但是instant没有commit的情 况,从而导致出现数据丢失。
优化方案:
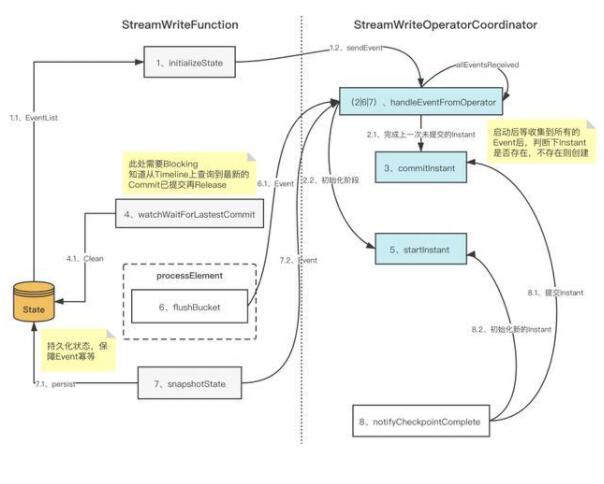
3.4 Append 模式支持及优化
背景:Append 模式是用于支持不需要 update 的数据集时使用的模式,可以在流程中省略索引、 合并等不必要的处理,从而大幅提高写入效率。
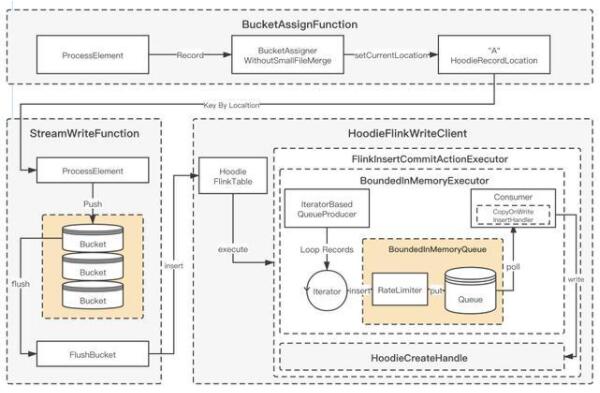
主要修改:
- 支持每次 FlushBucket 写入一个新的文件,避免出现读写的放大;
- 添加参数,支持关闭 BoundedInMemeoryQueue 内部的限速机制,在 Flink Append 模式下只需要将 Queue 的大小和 Bucket buffer 设置成同样的大小就可以了;
- 针对每个 CK 产生的小文件,制定自定义 Compaction 计划;
- 通过以上的开发和优化之后,在纯 Insert 场景下性能可达原先 COW 的 5 倍。
三、Hudi 任务稳定性保障
1. Hudi 集成 Flink Metrics
通过在关键节点上报 Metric,可以比较清晰的掌握整个任务的运行情况:
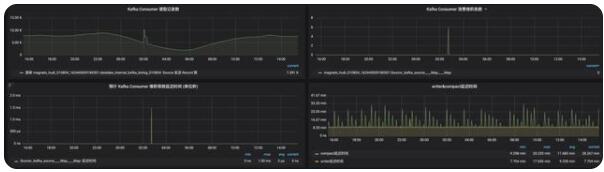
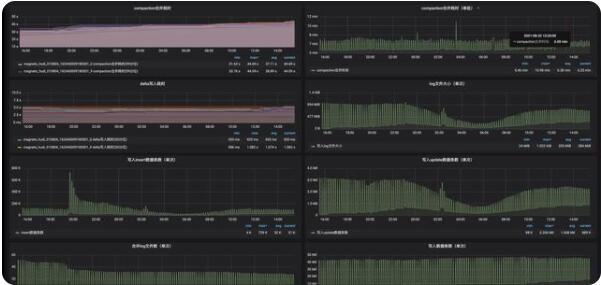
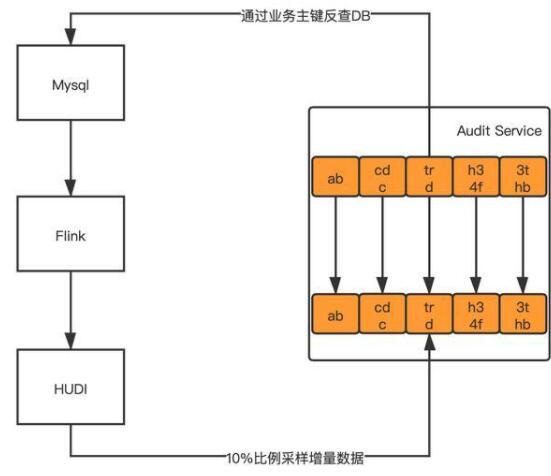
2. 系统内数据校验
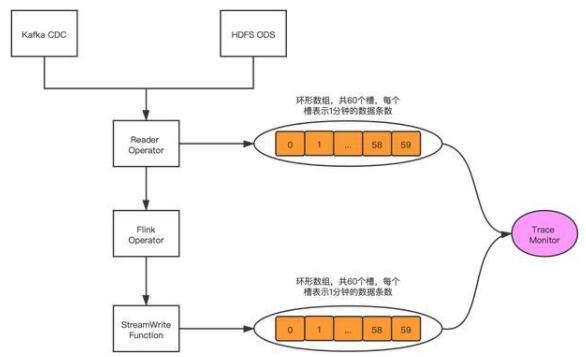
3. 系统外数据校验
四、数据入湖实践
1. CDC数据入湖
1.1 TiDB入湖方案
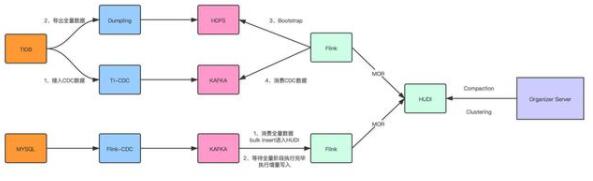
由于目前开源的各种方案都没办法直接支持 TiDB 的数据导出,直接使用 Select 的方式会影响数 据库的稳定性,所以拆成了全量 + 增量的方式:
- 启动 TI-CDC,将 TIDB 的 CDC 数据写入对应的 Kafka topic;
- 利用 TiDB 提供的 Dumpling 组件,修改部分源码,支持直接写入 HDFS;
- 启动 Flink 将全量数据通过 Bulk Insert 的方式写入 Hudi;
- 消费增量的 CDC 数据,通过 Flink MOR 的方式写入 Hudi。
1.2 MySQL 入湖方案
MySQL 的入湖方案是直接使用开源的 Flink-CDC,将全量和增量数据通过一个 Flink 任务写入 Kafka topic:
- 启动 Flink-CDC 任务将全量数据以及 CDC 数据导入 Kafka topic;
- 启动 Flink Batch 任务读取全量数据,通过 Bulk Insert 写入 Hudi;
- 切换为 Flink Streaming 任务将增量 CDC 数据通过 MOR 的方式写入 Hudi。
2. 日志数据增量入湖
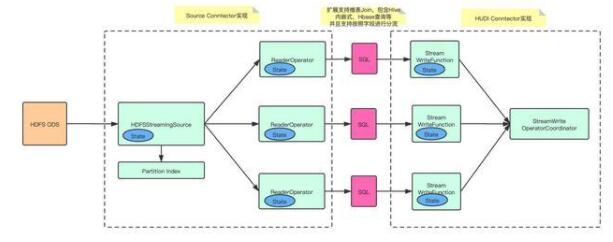
- 实现 HDFSStreamingSource 和 ReaderOperator,增量同步 ODS 的数据文件,并且通过写入 ODS 的分区索引信息,减少对 HDFS 的 list 请求;
- 支持 transform SQL 配置化,允许用户进行自定义逻辑转化,包括但不限于维表 join、自定义 udf、按字段分流等;
- 实现 Flink on Hudi 的 Append 模式,大幅提升不需要合并的数据写入速率。
五、增量数据湖平台收益
- 通过 Flink 增量同步大幅度提升了数据同步的时效性,分区就绪时间从 2:00~5:00 提前到 00:30 分内;
- 存储引擎使用 Hudi,提供用户基于 COW、MOR 的多种查询方式,让不同用户可以根据自己 的应用场景选择合适的查询方式,而不是单纯的只能等待分区归档后查询;
- 相较于之前数仓的 T+1 Binlog 合并方式,基于 Hudi 的自动 Compaction 使得用户可以将 Hive 当成 MySQL 的快照进行查询;
- 大幅节约资源,原先需要重复查询的分流任务只需要执行一次,节约大约 18000 core。
六、社区贡献
上述优化都已经合并到 Hudi 社区,B站在未来会进一步加强 Hudi 的建设,与社区一起成。
部分核心PR
https://issues.apache.org/jira/projects/Hudi/issues/Hudi-1923
https://issues.apache.org/jira/projects/Hudi/issues/Hudi-1924
https://issues.apache.org/jira/projects/Hudi/issues/Hudi-1954
https://issues.apache.org/jira/projects/Hudi/issues/Hudi-2019
https://issues.apache.org/jira/projects/Hudi/issues/Hudi-2052
https://issues.apache.org/jira/projects/Hudi/issues/Hudi-2084
https://issues.apache.org/jira/projects/Hudi/issues/Hudi-2342
七、未来的发展与思考
- 平台支持流批一体,统一实时与离线逻辑;
- 推进数仓增量化,达成 Hudi ODS -> Flink -> Hudi DW -> Flink -> Hudi ADS 的全流程;
- 在 Flink 上支持 Hudi 的 Clustering,体现出 Hudi 在数据组织上的优势,并探索 Z-Order 等加速多维查询的性能表现;
- 支持 inline clustering。