移动平均指标用于各种交易策略,以发现价格数据的长期趋势。简单移动平均线策略的一个潜在缺点是它们对所有价格的权重相同,而您可能希望最近的价格占有更大的比重。指数移动平均线 (EMA) 是实现这一目标的一种方法。
下面我们通过代码示例详细介绍 EMA 的实现,并将其与 SMA (简单移动平均)进行比较。
EMA 通过加权乘数赋予最新价格更多权重。这个乘数应用于最后一个价格,因此它比其他数据点占移动平均线更大的部分。EMA 是通过采用最近的价格(我们将其称为“时间 t 的价格”) 减去前一个时间段 (EMA_{t-1})。此差异由您将 EMA 设置为 (N) 并加回到 EMA_{t-1}的时间段数加权。在数学上,我们可以这样写:
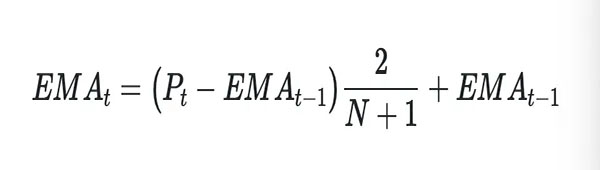
你可能已经注意到上面的等式有一个小问题,它是如何开始的?它参考了最后一个时期的 EMA,所以如果你进行第一次计算,它参考的是什么?这通常可以通过替换简单移动平均线 (SMA) 来初始化计算来延缓,这样您就可以在第一次之后的所有时间段构建 EMA。
让我们通过导入我们的包,用 Python 中的一个简单示例来展示它是如何工作的。
- import numpy as np
- import pandas as pd
- import yfinance as yf
- import matplotlib.pyplot as plt
从这里开始,我们将构建两个函数来协同工作并计算我们的指标。第一个函数将是我们上面概述的公式的简单实现:
- def _calcEMA(P, last_ema, N):
- return (P - last_ema) * (2 / (N + 1)) + last_ema
第二个函数将计算我们所有数据的 EMA,首先使用 SMA 对其进行初始化,然后迭代我们的数据以使用我们的 SMA 列中的值更新每个后续条目,或者调用我们上面定义的 _calcEMA 函数来处理大于 N的值。
- def calcEMA(data, N):
- # Initialize series
- data['SMA_' + str(N)] = data['Close'].rolling(N).mean()
- ema = np.zeros(len(data))
- for i, _row in enumerate(data.iterrows()):
- row = _row[1]
- if i < N:
- ema[i] += row['SMA_' + str(N)]
- else:
- ema[i] += _calcEMA(row['Close'], ema[i-1], N)
- data['EMA_' + str(N)] = ema.copy()
- return data
现在,让我们获取一些数据,看看它是如何工作的。我们将拉出比回测更短的时间段,并比较 EMA 和 SMA 的 10、50 和 100 天。
- ticker = 'BABA'
- yfyfObj = yf.Ticker(ticker)
- data = yfObj.history(ticker, start='2018-01-01', end='2020-12-31')
- N = [10, 50, 100]
- _ = [calcEMA(data, n) for n in N]
- colors = plt.rcParams['axes.prop_cycle'].by_key()['color']
- fig, ax = plt.subplots(figsize=(18, 8))
- ax.plot(data['Close'], label='Close')
- for i, n in enumerate(N, 1):
- ax.plot(data[f'EMA_{n}'], label=f'EMA-{n}', color=colors[i])
- ax.plot(data[f'SMA_{n}'], label=f'SMA-{n}', color=colors[i], linestyle=':')
- ax.legend()
- ax.set_title(f'EMA and Closing Price Comparison for {ticker}')
- plt.show()
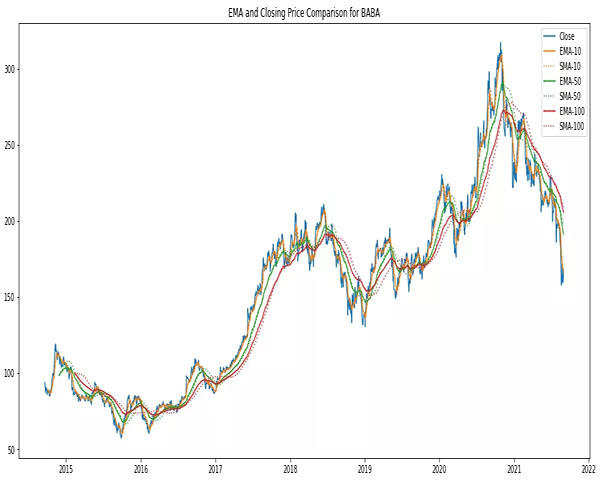
您可以在上图中看到,EMA 比 SMA 对最近的变化更敏感。较短的时间范围也比较长的时间范围更具响应性,较长的时间范围具有可以追溯到几个月或更长时间的价格“记忆”。
所有类型的移动平均线都是滞后指标,这意味着它们只能告诉您价格中已经发生了什么。然而,这并不意味着它们不能用于识别趋势和制定使用一个或多个移动平均指标的策略。如果您有想法,请继续进行测试,看看如何结合 EMA、SMA 和其他值来开发新的盈利交易策略。