













水满则溢,月盈则亏,任何事物都不可能无限制的发展,我们的系统服务能力也一样。
当随着流量的不断增长,达到或超过服务本身的可承载范围,系统服务的自我保护机制的建立就显得很重要了。
本文希望可以用最通俗的解释和贴切的实例来带大家了解什么是限流、降级和熔断。
Part1限流 - 自知之明和眼力见
一个是本身的承载能力,一个是依赖方的服务能力,其实都是从当前系统的角度来说,
1.1自知之明之被动限流
我只有这么大的能力,只能服务这么多客户!
系统对自身的承载能力需要有一个清晰的认识,对于超过承载能力的额外调用,要适当拒绝。
而怎样衡量系统承载能力是一个问题。
一般的我们有两种常见方案:一是定义阈值和规则,二是自适应限流策略。
阈值和规则是owner通过对业务的把控和自身的存储、连接的现状,根据人工经验制定的。这样的策略一般不会出什么大问题,但是不够灵活,对请求反馈的灵敏度和资源的利用率不够。
相对的,自适应策略则是一种动态限流策略,是通过对系统当前的运行状况,动态的调整限流阈值,在机器资源和流量处理之间寻找一个平衡。
如阿里开源的Sentinel限流器,在动态限流策略上支持[1]:
- Load 自适应:系统的 load1 作为启发指标,进行自适应系统保护。当系统 load1 超过设定的启发值,且系统当前的并发线程数超过估算的系统容量时才会触发系统保护。
- CPU usage:当系统 CPU 使用率超过阈值即触发系统保护(取值范围 0.0-1.0),比较灵敏。
- 平均 RT:当单台机器上所有入口流量的平均 RT 达到阈值即触发系统保护,单位是毫秒。
- 并发线程数:当单台机器上所有入口流量的并发线程数达到阈值即触发系统保护。
- 入口 QPS:当单台机器上所有入口流量的 QPS 达到阈值即触发系统保护。
1.2眼力见之主动限流
合作方只有那么大的能力,我只能索取这么多!
对下游依赖系统的服务能力,需要有一个精准的判断,对于服务能力弱的下游系统,要适当减少调用,得有点眼力见,对不对。
因为,绝大部分的业务系统都不是单独存在的,会依赖很多其他的系统,这些依赖方的服务能力,就像是木桶短板,限制了当前系统的处理能力。这个时候就需要把下游当做一个整体来考虑。
因此,需要把集群限流和单机限流配合起来使用,特别是下游服务的实例数、服务能力等和当前系统有较大差距的时候,集群限流还是必要的。
一种方案:是通过收集服务节点的请求日志,统计请求量,并通过限流配置,控制节点限流逻辑:
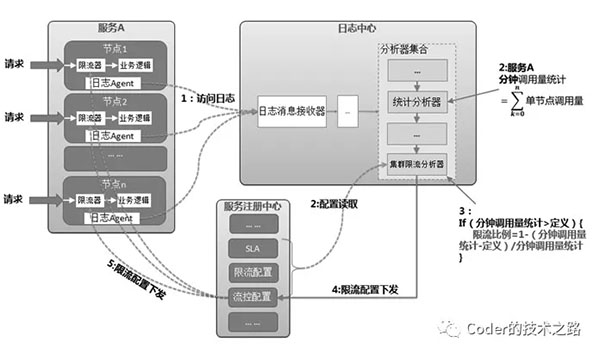
摘自:微服务治理:体系、架构及实践
我将其称为后置限流,即收集各个节点的请求量和既定阈值对比,超过则反馈到各个节点,依赖单机限流进行比例限流。
另一种方案:是限流总控服务,根据配置生产token,然后各个节点消费token,正常获取token后才能继续业务:
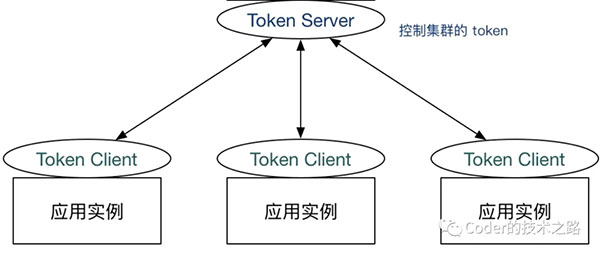
摘自:Sentinel
我将其称为前置限流,预先确定分配好可用的token,省去了汇总和反馈的处理机制,相比而言,这种控制方式要相对精准和优雅。
1.3同步转异步
合作方虽然能力有限,但态度很好,加班加点的处理;而我们的客户也很友好,同意多等等
一个非常经典的例子,就是第三方支付平台的还款业务,用过的同学应该都有体会,一般都是支付完成之后等一会才会收到销账的通知。
这个时延的底层逻辑是什么呢?
一般的,金融机构的服务接口,因为其数据一致性和系统稳定性的要求,性能方面可能不如互联网公司的系统。
那么,当到了月初月末的还款高峰,如果把支持成功用户的销账请求一股脑的都压给机构,后果可想而知。
但是,对于用户来说,整个流程是可以被拆分的,用户侧只要完成支付操作就可以了。至于最终结果,可以允许延后被通知。
因此,基本上,金融网关在处理机构销账都是异步的,即先将各业务的销账请求落地,然后异步的限速轮询待处理的单据,再和机构交互。
其实,不仅仅是在金融领域,只要我们的业务处理速度存在差异,且流程可以被拆分,即可考虑这种架构思路,来缓解系统压力,保障业务可用性。
Part2降级 - 丢车保帅
事发突然,能力有限,我只能紧着几个重要客户服务!
那么,什么情况需要降级,什么链路可以被降级呢?
当整个业务处于高峰期,或活动脉冲期,当服务的负载很高,逼近了服务承载阈值,即可以考虑服务降级来保障主功能可用。
可以降级的一定是非核心的链路,比如网购场景下的积分抵扣,如果降级积分抵扣链路,其实不影响大部分的支付功能。
那么,在系统中我们一般采用的降级方案有哪些呢?
1、页面降级:即从用户操作页面进行操作,直接限制和截断某功能的入口:
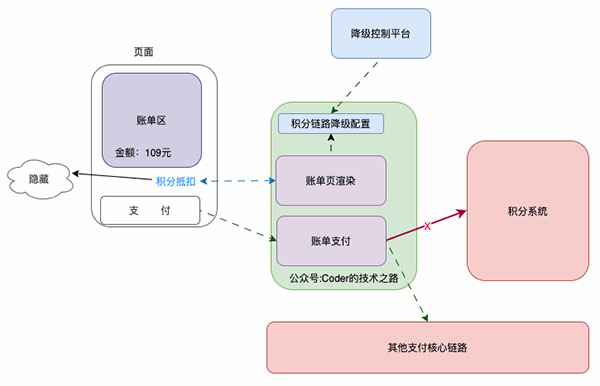
从页面入口对积分链路降级
如上图所示,该业务场景下,是否使用积分,是在页面渲染阶段决定并返回给前段进行页面拼接的。
当我们需要对其进行降级时,会通过控制平台进行降级开关切换,系统读到降级开启后,会返回前段积分降级的标识,前端将不再显示积分抵扣入口。即从入口处截断积分链路的执行,达到降级的目的。
2、存储降级:使用缓存方式来降级频繁操作的存储
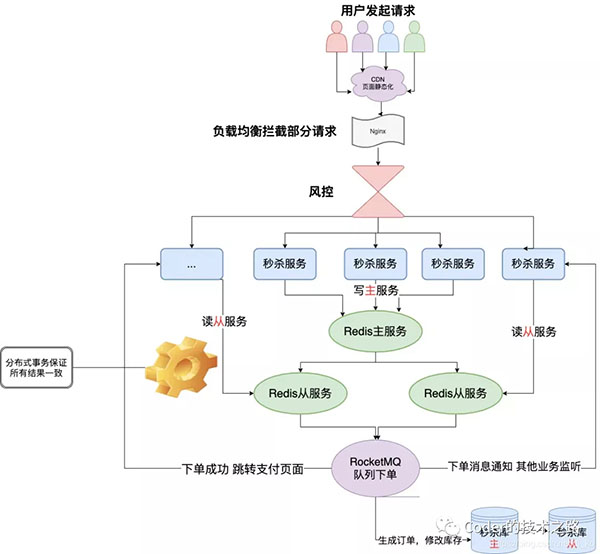
https://blog.csdn.net/di_ko/article/details/118058080
对于秒杀业务这种写多读少的场景,对DB的压力是非常大的,一般的,我们会采用上图所示的缓存架构,用缓存操作代替DB操作,用异步MQ代替同步接口,也属于一种存储的降级行为。
3、读降级:对于非核心信息的读请求禁用
微信的抢红包场景,红包列表的展示属于抢红包的非核心链路,因此,对于列表展示,在业务压力较大的情况下,对头像等信息的读,可以直接禁用。
4、写降级:直接禁止相关写操作的服务请求
总结,一句话概括降级的核心--丢车保帅。以损失部分体验的代价,来换取整个业务链路的稳定性和持续可用。
Part3熔断- 大局观
合作方遇到困难了,不能为了自己把人家逼上绝路,别把自己也拖垮!出于人道主义,还得时不时问询下,Are you ok ?
熔断机制之所以被我赋予大局观的美称,是因为其所要解决的问题是级联故障和服务雪崩!
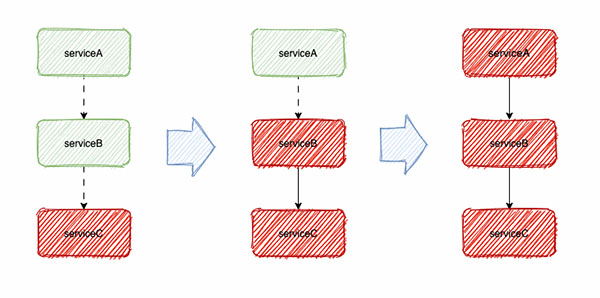
在分布式的环境下,异常是常态。如上图所示,当服务C出现调用异常时,会在服务B中出现大量的请求超时和调用延迟。
这些调用也是需要占用系统资源的,当大量请求积压,服务B的线程池等资源也会随之耗尽,最终导致整个服务链路的雪崩都是有可能的。
因此,当服务C出现异常时,对服务C的调用适当暂停,同时不断监测其接口是否恢复,对于整个链路的健康非常有必要的,上述针对C的处理过程就是熔断。
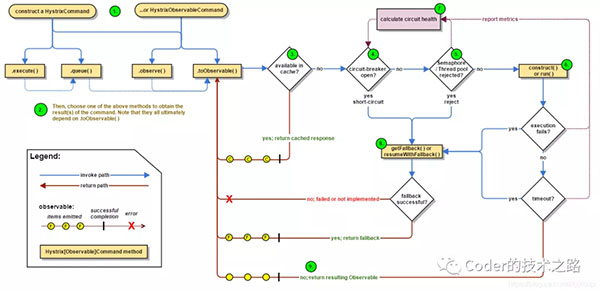
Hystrix官方熔断流程[2]
从上图可以看到,熔断操作的三个关键点:
- 熔断算法,即什么情况即会被判定为需要熔断
- 熔断后处理,即当前系统不进行远程调用,但调用结果需要有替代逻辑
- 熔断恢复,适当的检测机制,用于结束熔断,恢复正常服务调用。
之前在《在所依赖存储不授信的场景下实现柔性事务降级》一文中提到过,我们的分布式事务,会依赖底层存储做元数据存储和一致性校验。
但是底层存储的稳定性稍有不足,这里就涉及到了服务熔断的处理:
- 当我们通过关键字监控,检测到底层存储的操作异常操作某阈值时,就会通过脚本触发一个开关切换的操作。
- 此开关打开的作用是,弃用底层存储,直接走兜底消息队列,以保障绝大部分请求得以正常进行。
- 在开发开启的时间段内,用试探线程去试探底层存储是否恢复,当探测到存储恢复正常时,切换开关恢复到正常链路。(这一步目前还未实现,用人工代替了)














