背景
目前一些互联网公司会使用消息队列来做核心业务,因为是核心业务,所以对数据的最后一致性比较敏感,如果中间出现数据丢失,就会引来用户的投诉,年底绩效就变成325了。之前和几个朋友聊天,他们的公司都在用kafka来做消息队列,使用kafka到底会不会丢消息呢?如果丢消息了该怎么做好补偿措施呢?本文我们就一起来分析一下,并介绍如何使用Go操作Kafka可以不丢失数据。
本文操作kafka基于:https://github.com/Shopify/sarama
初识kafka架构
维基百科对kafka的介绍:
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。该项目的目标是为处理实时数据提供一个统一、高吞吐、低延迟的平台。其持久化层本质上是一个“按照分布式事务日志架构的大规模发布/订阅消息队列”,这使它作为企业级基础设施来处理流式数据非常有价值。此外,Kafka可以通过Kafka Connect连接到外部系统(用于数据输入/输出),并提供了Kafka Streams——一个Java]流式处理库。该设计受事务日志的影响较大。
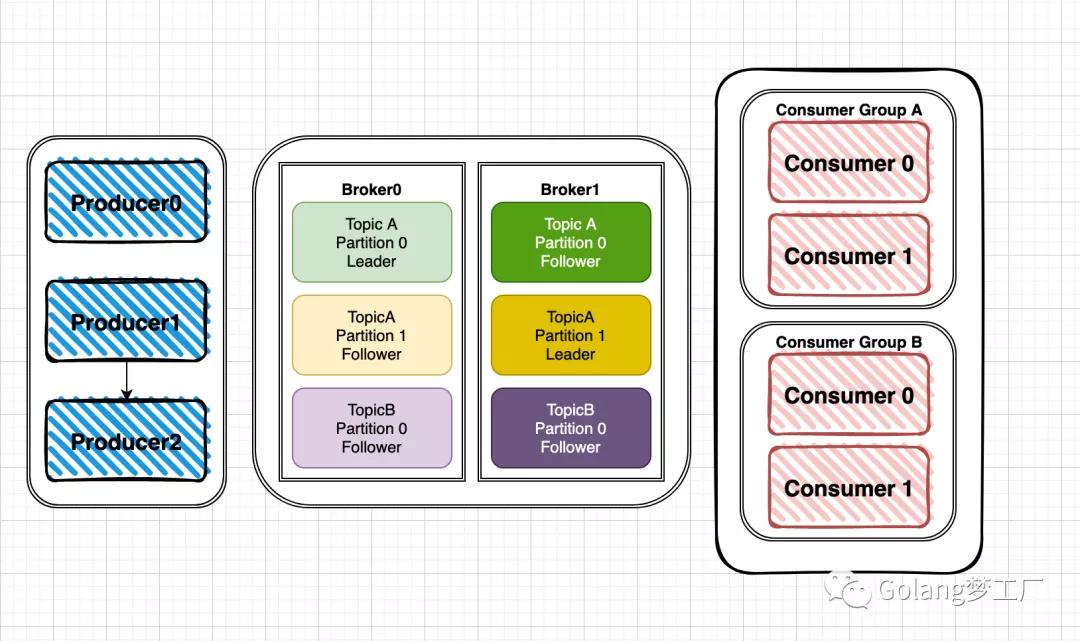
kafka的整体架构比较简单,主要由producer、broker、consumer组成:
截屏2021-09-12 上午10.00.13
针对架构图我们解释一个各个模块:
- Producer:数据的生产者,可以将数据发布到所选择的topic中。
- Consumer:数据的消费者,使用Consumer Group进行标识,在topic中的每条记录都会被分配给订阅消费组中的一个消费者实例,消费者实例可以分布在多个进程中或者多个机器上。
- Broker:消息中间件处理节点(服务器),一个节点就是一个broker,一个Kafka集群由一个或多个broker组成。
还有些概念我们也介绍一下:
- topic:可以理解为一个消息的集合,topic存储在broker中,一个topic可以有多个partition分区,一个topic可以有多个Producer来push消息,一个topic可以有多个消费者向其pull消息,一个topic可以存在一个或多个broker中。
- partition:其是topic的子集,不同分区分配在不同的broker上进行水平扩展从而增加kafka并行处理能力,同topic下的不同分区信息是不同的,同一分区信息是有序的;每一个分区都有一个或者多个副本,其中会选举一个leader,fowller从leader拉取数据更新自己的log(每个分区逻辑上对应一个log文件夹),消费者向leader中pull信息。
kafka丢消息的三个节点
生产者push消息节点
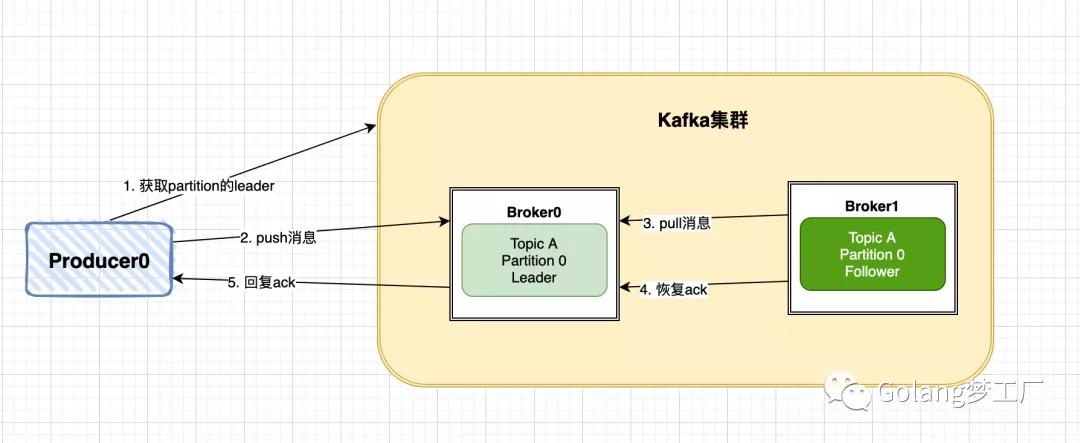
先看一下producer的大概写入流程:
- producer先从kafka集群找到该partition的leader
- producer将消息发送给leader,leader将该消息写入本地
- follwers从leader pull消息,写入本地log后leader发送ack
- leader 收到所有 ISR 中的 replica 的 ACK 后,增加high watermark,并向 producer 发送 ack
截屏2021-09-12 上午11.16.43
通过这个流程我们可以看到kafka最终会返回一个ack来确认推送消息结果,这里kafka提供了三种模式:
- NoResponse RequiredAcks = 0
- WaitForLocal RequiredAcks = 1
- WaitForAll RequiredAcks = -1
- NoResponse RequiredAcks = 0:这个代表的就是数据推出的成功与否都与我无关了
- WaitForLocal RequiredAcks = 1:当local(leader)确认接收成功后,就可以返回了
- WaitForAll RequiredAcks = -1:当所有的leader和follower都接收成功时,才会返回
所以根据这三种模式我们就能推断出生产者在push消息时有一定几率丢失的,分析如下:
- 如果我们选择了模式1,这种模式丢失数据的几率很大,无法重试
- 如果我们选择了模式2,这种模式下只要leader不挂,就可以保证数据不丢失,但是如果leader挂了,follower还没有同步数据,那么就会有一定几率造成数据丢失
- 如果选择了模式3,这种情况不会造成数据丢失,但是有可能会造成数据重复,假如leader与follower同步数据是网络出现问题,就有可能造成数据重复的问题。
所以在生产环境中我们可以选择模式2或者模式3来保证消息的可靠性,具体需要根据业务场景来进行选择,在乎吞吐量就选择模式2,不在乎吞吐量,就选择模式3,要想完全保证数据不丢失就选择模式3是最可靠的。
kafka集群自身故障造成
kafka集群接收到数据后会将数据进行持久化存储,最终数据会被写入到磁盘中,在写入磁盘这一步也是有可能会造成数据损失的,因为写入磁盘的时候操作系统会先将数据写入缓存,操作系统将缓存中数据写入磁盘的时间是不确定的,所以在这种情况下,如果kafka机器突然宕机了,也会造成数据损失,不过这种概率发生很小,一般公司内部kafka机器都会做备份,这种情况很极端,可以忽略不计。
消费者pull消息节点
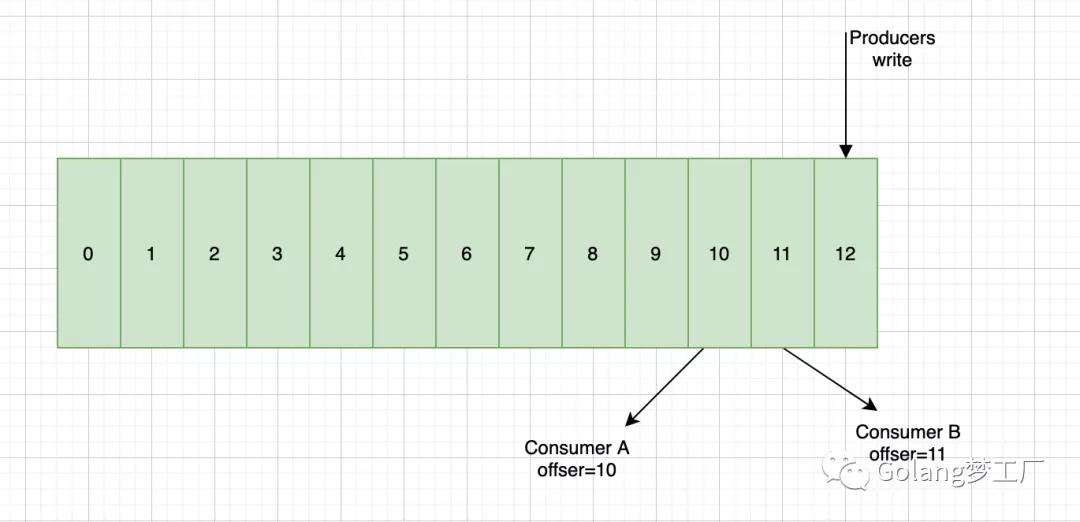
push消息时会把数据追加到Partition并且分配一个偏移量,这个偏移量代表当前消费者消费到的位置,通过这个Partition也可以保证消息的顺序性,消费者在pull到某个消息后,可以设置自动提交或者手动提交commit,提交commit成功,offset就会发生偏移:
截屏2021-09-12 下午3.37.33
所以自动提交会带来数据丢失的问题,手动提交会带来数据重复的问题,分析如下:
- 在设置自动提交的时候,当我们拉取到一个消息后,此时offset已经提交了,但是我们在处理消费逻辑的时候失败了,这就会导致数据丢失了
- 在设置手动提交时,如果我们是在处理完消息后提交commit,那么在commit这一步发生了失败,就会导致重复消费的问题。
比起数据丢失,重复消费是符合业务预期的,我们可以通过一些幂等性设计来规避这个问题。
实战
完整代码已经上传github:https://github.com/asong2020/Golang_Dream/tree/master/code_demo/kafka_demo
解决push消息丢失问题
主要是通过两点来解决:
- 通过设置RequiredAcks模式来解决,选用WaitForAll可以保证数据推送成功,不过会影响时延时
- 引入重试机制,设置重试次数和重试间隔
因此我们写出如下代码(摘出创建client部分):
- func NewAsyncProducer() sarama.AsyncProducer {
- cfg := sarama.NewConfig()
- version, err := sarama.ParseKafkaVersion(VERSION)
- if err != nil{
- log.Fatal("NewAsyncProducer Parse kafka version failed", err.Error())
- return nil
- }
- cfg.Version = version
- cfg.Producer.RequiredAcks = sarama.WaitForAll // 三种模式任君选择
- cfg.Producer.Partitioner = sarama.NewHashPartitioner
- cfg.Producer.Return.Successes = true
- cfg.Producer.Return.Errors = true
- cfg.Producer.Retry.Max = 3 // 设置重试3次
- cfg.Producer.Retry.Backoff = 100 * time.Millisecond
- cli, err := sarama.NewAsyncProducer([]string{ADDR}, cfg)
- if err != nil{
- log.Fatal("NewAsyncProducer failed", err.Error())
- return nil
- }
- return cli
- }
解决pull消息丢失问题
这个解决办法就比较粗暴了,直接使用自动提交的模式,在每次真正消费完之后在自己手动提交offset,但是会产生重复消费的问题,不过很好解决,使用幂等性操作即可解决。
代码示例:
- func NewConsumerGroup(group string) sarama.ConsumerGroup {
- cfg := sarama.NewConfig()
- version, err := sarama.ParseKafkaVersion(VERSION)
- if err != nil{
- log.Fatal("NewConsumerGroup Parse kafka version failed", err.Error())
- return nil
- }
- cfg.Version = version
- cfg.Consumer.Group.Rebalance.Strategy = sarama.BalanceStrategyRange
- cfg.Consumer.Offsets.Initial = sarama.OffsetOldest
- cfg.Consumer.Offsets.Retry.Max = 3
- cfg.Consumer.Offsets.AutoCommit.Enable = true // 开启自动提交,需要手动调用MarkMessage才有效
- cfg.Consumer.Offsets.AutoCommit.Interval = 1 * time.Second // 间隔
- client, err := sarama.NewConsumerGroup([]string{ADDR}, group, cfg)
- if err != nil {
- log.Fatal("NewConsumerGroup failed", err.Error())
- }
- return client
- }
上面主要是创建ConsumerGroup部分,细心的读者应该看到了,我们这里使用的是自动提交,说好的使用手动提交呢?这是因为我们这个kafka库的特性不同,这个自动提交需要与MarkMessage()方法配合使用才会提交(有疑问的朋友可以实践一下,或者看一下源码),否则也会提交失败,因为我们在写消费逻辑时要这样写:
- func (e EventHandler) ConsumeClaim(session sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {
- for msg := range claim.Messages() {
- var data common.KafkaMsg
- if err := json.Unmarshal(msg.Value, &data); err != nil {
- return errors.New("failed to unmarshal message err is " + err.Error())
- }
- // 操作数据,改用打印
- log.Print("consumerClaim data is ")
- // 处理消息成功后标记为处理, 然后会自动提交
- session.MarkMessage(msg,"")
- }
- return nil
- }
或者直接使用手动提交方法来解决,只需两步:
第一步:关闭自动提交:
- consumerConfig.Consumer.Offsets.AutoCommit.Enable = false // 禁用自动提交,改为手动
第二步:消费逻辑中添加如下代码,手动提交模式下,也需要先进行标记,在进行commit
- session.MarkMessage(msg,"")
- session.Commit()
完整代码可以到github上下载并进行验证!
总结
本文我们主要说明了两个知识点:
Kafka会产生消息丢失
使用Go操作Kafka如何配置可以不丢失数据
日常业务开发中,很多公司都喜欢拿消息队列进行解耦,那么你就要注意了,使用Kafka做消息队列无法保证数据不丢失,需要我们自己手动配置补偿,别忘记了,要不又是一场P0事故。