













前言
String类的一个最大特性是不可修改性,而导致其不可修改的原因是在String内部定义了一个常量数组,因此每次对字符串的操作实际上都会另外分配分配一个新的常量数组空间;
那今天我们就来分析一波
一、String实现源码分析
1、String的定义
public final class String implements java.io.Serializable, Comparable, CharSequence
- 1.
从上,我们可以看出几个重点:
String是一个final类,既不能被继承的类
String类实现了java.io.Serializable接口,可以实现序列化
String类实现了Comparable
String类实现了 CharSequence 接口,表示是一个有序字符的序列,因为String的本质是一个char类型数组
2、字段属性
//用来存字符串,字符串的本质,是一个final的char型数组
private final char value[];
//缓存字符串的哈希
private int hash; // Default to 0
//实现序列化的标识
private static final long serialVersionUID = -6849794470754667710L;
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
这里需要注意的重点是:
private final char value[]这是String字符串的本质,是一个字符集合,而且是final的,是不可变的
3、构造函数
/** 01
* 这是一个经常会使用的String的无参构造函数.
* 默认将""空字符串的value赋值给实例对象的value,也是空字符
* 相当于深拷贝了空字符串""
*/
public String() {
this.value = "".value;
}
/** 02
* 这是一个有参构造函数,参数为一个String对象
* 将形参的value和hash赋值给实例对象作为初始化
* 相当于深拷贝了一个形参String对象
*/
public String(String original) {
this.value = original.value;
this.hash = original.hash;
}
/** 03
* 这是一个有参构造函数,参数为一个char字符数组
* 虽然我不知道为什么要Arrays.copyOf去拷贝,而不直接this.value = value;
* 意义就是通过字符数组去构建一个新的String对象
*/
public String(char value[]) {
this.value = Arrays.copyOf(value, value.length);
}
/** 04
* 这是一个有参构造函数,参数为char字符数组,offset(起始位置,偏移量),count(个数)
* 作用就是在char数组的基础上,从offset位置开始计数count个,构成一个新的String的字符串
* 意义就类似于截取count个长度的字符集合构成一个新的String对象
*/
public String(char value[], int offset, int count) {
if (offset < 0) { //如果起始位置小于0,抛异常
throw new StringIndexOutOfBoundsException(offset);
}
if (count <= 0) {
if (count < 0) { //如果个数小于0,抛异常
throw new StringIndexOutOfBoundsException(count);
}
if (offset <= value.length) { //在count = 0的前提下,如果offset<=len,则返回""
this.value = "".value;
return;
}
}
// Note: offset or count might be near -1>>>1.
//如果起始位置>字符数组长度 - 个数,则无法截取到count个字符,抛异常
if (offset > value.length - count) {
throw new StringIndexOutOfBoundsException(offset + count);
}
//重点,从offset开始,截取到offset+count位置(不包括offset+count位置)
this.value = Arrays.copyOfRange(value, offset, offset+count);
}
/** 05
* 这是一个有参构造函数,参数为int字符数组,offset(起始位置,偏移量),count(个数)
* 作用跟04构造函数差不多,但是传入的不是char字符数组,而是int数组。
* 而int数组的元素则是字符对应的ASCII整数值
* 例子:new String(new int[]{97,98,99},0,3); output: abc
*/
public String(int[] codePoints, int offset, int count) {
if (offset < 0) {
throw new StringIndexOutOfBoundsException(offset);
}
if (count <= 0) {
if (count < 0) {
throw new StringIndexOutOfBoundsException(count);
}
if (offset <= codePoints.length) {
this.value = "".value;
return;
}
}
// Note: offset or count might be near -1>>>1.
if (offset > codePoints.length - count) {
throw new StringIndexOutOfBoundsException(offset + count);
}
//以上都是为了处理offset和count的正确性,如果有错,则抛异常
final int end = offset + count;
// Pass 1: Compute precise size of char[]
int n = count;
for (int i = offset; i < end; i++) {
int c = codePoints[i];
if (Character.isBmpCodePoint(c))
continue;
else if (Character.isValidCodePoint(c))
n++;
else throw new IllegalArgumentException(Integer.toString(c));
}
//上面关于BMP什么的,我暂时也没看懂,猜想关于验证int数据的正确性,通过上面的测试就进入下面的算法
// Pass 2: Allocate and fill in char[]
final char[] v = new char[n];
for (int i = offset, j = 0; i < end; i++, j++) { //从offset开始,到offset + count
int c = codePoints[i];
if (Character.isBmpCodePoint(c))
v[j] = (char)c; //将Int类型显式缩窄转换为char类型
else
Character.toSurrogates(c, v, j++);
}
this.value = v; //最后将得到的v赋值给String对象的value,完成初始化
}
/****这里把被标记为过时的构造函数去掉了***/
/** 06
* 这是一个有参构造函数,参数为byte数组,offset(起始位置,偏移量),长度,和字符编码格式
* 就是传入一个byte数组,从offset开始截取length个长度,其字符编码格式为charsetName,如UTF-8
* 例子:new String(bytes, 2, 3, "UTF-8");
*/
public String(byte bytes[], int offset, int length, String charsetName)
throws UnsupportedEncodingException {
if (charsetName == null)
throw new NullPointerException("charsetName");
checkBounds(bytes, offset, length);
this.value = StringCoding.decode(charsetName, bytes, offset, length);
}
/** 07
* 类似06
*/
public String(byte bytes[], int offset, int length, Charset charset) {
if (charset == null)
throw new NullPointerException("charset");
checkBounds(bytes, offset, length);
this.value = StringCoding.decode(charset, bytes, offset, length);
}
/** 08
* 这是一个有参构造函数,参数为byte数组和字符集编码
* 用charsetName的方式构建byte数组成一个String对象
*/
public String(byte bytes[], String charsetName)
throws UnsupportedEncodingException {
this(bytes, 0, bytes.length, charsetName);
}
/** 09
* 类似08
*/
public String(byte bytes[], Charset charset) {
this(bytes, 0, bytes.length, charset);
}
/** 10
* 这是一个有参构造函数,参数为byte数组,offset(起始位置,偏移量),length(个数)
* 通过使用平台的默认字符集解码指定的 byte 子数组,构造一个新的 String。
*
*/
public String(byte bytes[], int offset, int length) {
checkBounds(bytes, offset, length);
this.value = StringCoding.decode(bytes, offset, length);
}
/** 11
* 这是一个有参构造函数,参数为byte数组
* 通过使用平台默认字符集编码解码传入的byte数组,构造成一个String对象,不需要截取
*
*/
public String(byte bytes[]) {
this(bytes, 0, bytes.length);
}
/** 12
* 有参构造函数,参数为StringBuffer类型
* 就是将StringBuffer构建成一个新的String,比较特别的就是这个方法有synchronized锁
* 同一时间只允许一个线程对这个buffer构建成String对象
*/
public String(StringBuffer buffer) {
synchronized(buffer) {
this.value = Arrays.copyOf(buffer.getValue(), buffer.length()); //使用拷贝的方式
}
}
/** 13
* 有参构造函数,参数为StringBuilder
* 同12差不多,只不过是StringBuilder的版本,差别就是没有实现线程安全
*/
public String(StringBuilder builder) {
this.value = Arrays.copyOf(builder.getValue(), builder.length());
}
/** 14
* 这个构造函数比较特殊,有用的参数只有char数组value,是一个不对外公开的构造函数,没有访问修饰符
* 加入这个share的只是为了区分于String(char[] value)方法,用于重载,功能类似于03,我也在03表示过疑惑。
* 为什么提供这个方法呢,因为性能好,不需要拷贝。为什么不对外提供呢?因为对外提供会打破value为不变数组的限制。
* 如果对外提供这个方法让String与外部的value产生关联,如果修改外不的value,会影响String的value。所以不能
* 对外提供
*/
String(char[] value, boolean share) {
// assert share : "unshared not supported";
this.value = value;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
- 79.
- 80.
- 81.
- 82.
- 83.
- 84.
- 85.
- 86.
- 87.
- 88.
- 89.
- 90.
- 91.
- 92.
- 93.
- 94.
- 95.
- 96.
- 97.
- 98.
- 99.
- 100.
- 101.
- 102.
- 103.
- 104.
- 105.
- 106.
- 107.
- 108.
- 109.
- 110.
- 111.
- 112.
- 113.
- 114.
- 115.
- 116.
- 117.
- 118.
- 119.
- 120.
- 121.
- 122.
- 123.
- 124.
- 125.
- 126.
- 127.
- 128.
- 129.
- 130.
- 131.
- 132.
- 133.
- 134.
- 135.
- 136.
- 137.
- 138.
- 139.
- 140.
- 141.
- 142.
- 143.
- 144.
- 145.
- 146.
- 147.
- 148.
- 149.
- 150.
- 151.
- 152.
- 153.
- 154.
- 155.
- 156.
- 157.
- 158.
- 159.
- 160.
- 161.
- 162.
- 163.
- 164.
- 165.
- 166.
- 167.
- 168.
- 169.
- 170.
- 171.
- 172.
- 173.
- 174.
- 175.
- 176.
- 177.
- 178.
- 179.
展示了总共14种构造方法:
- 可以构造空字符串对象,既"";
- 可以根据String,StringBuilder,StringBuffer构造字符串对象;
- 可以根据char数组,其子数组构造字符串对象;
- 可以根据int数组,其子数组构造字符串对象;
- 可以根据某个字符集编码对byte数组,其子数组解码并构造字符串对象;
4、长度和是否为空函数
public int length() { //所以String的长度就是一个value的长度
return value.length;
}
public boolean isEmpty() { //当char数组的长度为0,则代表String为"",空字符串
return value.length == 0;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
5、charAt、codePointAt类型函数
/**
* 返回String对象的char数组index位置的元素
*/
public char charAt(int index) {
if ((index < 0) || (index >= value.length)) { //index不允许小于0,不允许大于等于String的长度
throw new StringIndexOutOfBoundsException(index);
}
return value[index]; //返回
}
/**
* 返回String对象的char数组index位置的元素的ASSIC码(int类型)
*/
public int codePointAt(int index) {
if ((index < 0) || (index >= value.length)) {
throw new StringIndexOutOfBoundsException(index);
}
return Character.codePointAtImpl(value, index, value.length);
}
/**
* 返回index位置元素的前一个元素的ASSIC码(int型)
*/
public int codePointBefore(int index) {
int i = index - 1; //获得index前一个元素的索引位置
if ((i < 0) || (i >= value.length)) { //所以,index不能等于0,因为i = 0 - 1 = -1
throw new StringIndexOutOfBoundsException(index);
}
return Character.codePointBeforeImpl(value, index, 0);
}
/**
* 方法返回的是代码点个数,是实际上的字符个数,功能类似于length()
* 对于正常的String来说,length方法和codePointCount没有区别,都是返回字符个数。
* 但当String是Unicode类型时则有区别了。
* 例如:String str = “/uD835/uDD6B” (即使 'Z' ), length() = 2 ,codePointCount() = 1
*/
public int codePointCount(int beginIndex, int endIndex) {
if (beginIndex < 0 || endIndex > value.length || beginIndex > endIndex) {
throw new IndexOutOfBoundsException();
}
return Character.codePointCountImpl(value, beginIndex, endIndex - beginIndex);
}
/**
* 也是相对Unicode字符集而言的,从index索引位置算起,偏移codePointOffset个位置,返回偏移后的位置是多少
* 例如,index = 2 ,codePointOffset = 3 ,maybe返回 5
*/
public int offsetByCodePoints(int index, int codePointOffset) {
if (index < 0 || index > value.length) {
throw new IndexOutOfBoundsException();
}
return Character.offsetByCodePointsImpl(value, 0, value.length,
index, codePointOffset);
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
只有一个charAt()是针对字符而言的,就是寻找第index位置的字符是什么;
ChatAt是实现CharSequence 而重写的方法,是一个有序字符集的方法;
6、getChar、getBytes类型函数
/**
* 这是一个不对外的方法,是给String内部调用的,因为它是没有访问修饰符的,只允许同一包下的类访问
* 参数:dst[]是目标数组,dstBegin是目标数组的偏移量,既要复制过去的起始位置(从目标数组的什么位置覆盖)
* 作用就是将String的字符数组value整个复制到dst字符数组中,在dst数组的dstBegin位置开始拷贝
*
*/
void getChars(char dst[], int dstBegin) {
System.arraycopy(value, 0, dst, dstBegin, value.length);
}
/**
* 得到char字符数组,原理是getChars() 方法将一个字符串的字符复制到目标字符数组中。
* 参数:srcBegin是原始字符串的起始位置,srcEnd是原始字符串要复制的字符末尾的后一个位置(既复制区域不包括srcEnd)
* dst[]是目标字符数组,dstBegin是目标字符的复制偏移量,复制的字符从目标字符数组的dstBegin位置开始覆盖。
*/
public void getChars(int srcBegin, int srcEnd, char dst[], int dstBegin) {
if (srcBegin < 0) { //如果srcBegin小于,抛异常
throw new StringIndexOutOfBoundsException(srcBegin);
}
* if (srcEnd > value.length) { //如果srcEnd大于字符串的长度,抛异常
throw new StringIndexOutOfBoundsException(srcEnd);
}
if (srcBegin > srcEnd) { //如果原始字符串其实位置大于末尾位置,抛异常
throw new StringIndexOutOfBoundsException(srcEnd - srcBegin);
}
System.arraycopy(value, srcBegin, dst, dstBegin, srcEnd - srcBegin);
}
/****去除被标记过时的方法****/
/**
* 获得charsetName编码格式的bytes数组
*/
public byte[] getBytes(String charsetName)
throws UnsupportedEncodingException {
if (charsetName == null) throw new NullPointerException();
return StringCoding.encode(charsetName, value, 0, value.length);
}
/**
* 与上个方法类似,但charsetName和charset的区别,我还没搞定,搞懂来再更新
*/
public byte[] getBytes(Charset charset) {
if (charset == null) throw new NullPointerException();
return StringCoding.encode(charset, value, 0, value.length);
}
/**
* 使用平台默认的编码格式获得bytes数组
*/
public byte[] getBytes() {
return StringCoding.encode(value, 0, value.length);
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- getChars是没有返回值的,原理是通过System.arraycopy方法来实现的,不需要返回值。所以被覆盖的字符数组是需要具体存在的;
- getBytes是有返回值的;
7、equal类函数(是否相等)
/**
* String的equals方法,重写了Object的equals方法(区分大小写)
* 比较的是两个字符串的值是否相等
* 参数是一个Object对象,而不是一个String对象。这是因为重写的是Object的equals方法,所以是Object
* 如果是String自己独有的方法,则可以传入String对象,不用多此一举
*
* 实例:str1.equals(str2)
*/
public boolean equals(Object anObject) {
if (this == anObject) { //首先判断形参str2是否跟当前对象str1是同一个对象,既比较地址是否相等
return true; //如果地址相等,那么自然值也相等,毕竟是同一个字符串对象
}
if (anObject instanceof String) { //判断str2对象是否是一个String类型,过滤掉非String类型的比较
String anotherString = (String)anObject; //如果是String类型,转换为String类型
int n = value.length; //获得当前对象str1的长度
if (n == anotherString.value.length) { //比较str1的长度和str2的长度是否相等
//如是进入核心算法
char v1[] = value; //v1为当前对象str1的值,v2为参数对象str2的值
char v2[] = anotherString.value;
int i = 0; //就类似于for的int i =0的作用,因为这里使用while
while (n-- != 0) { //每次循环长度-1,直到长度消耗完,循环结束
if (v1[i] != v2[i]) //同索引位置的字符元素逐一比较
return false; //只要有一个不相等,则返回false
i++;
}
return true; //如比较期间没有问题,则说明相等,返回true
}
}
return false;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
/**
* 这也是一个String的equals方法,与上一个方法不用,该方法(不区分大小写),从名字也能看出来
* 是对String的equals方法的补充。
* 这里参数这是一个String对象,而不是Object了,因为这是String本身的方法,不是重写谁的方法
*/
public boolean equalsIgnoreCase(String anotherString) {
return (this == anotherString) ? true //一样,先判断是否为同一个对象
: (anotherString != null)
&& (anotherString.value.length == value.length) //再判断长度是否相等
&& regionMatches(true, 0, anotherString, 0, value.length); //再执行regionMatchs方法
}
/**
* 这是一个公有的比较方法,参数是StringBuffer类型
* 实际调用的是contentEquals(CharSequence cs)方法,可以说是StringBuffer的特供版
*/
public boolean contentEquals(StringBuffer sb) {
return contentEquals((CharSequence)sb);
}
/**
* 这是一个私有方法,特供给比较StringBuffer和StringBuilder使用的。
* 比如在contentEquals方法中使用,参数是AbstractStringBuilder抽象类的子类
*
*/
private boolean nonSyncContentEquals(AbstractStringBuilder sb) {
char v1[] = value; //当前String对象的值
char v2[] = sb.getValue(); //AbstractStringBuilder子类对象的值
int n = v1.length; //后面就不说了,其实跟equals方法是一样的,只是少了一些判断
if (n != sb.length()) {
return false;
}
for (int i = 0; i < n; i++) {
if (v1[i] != v2[i]) {
return false;
}
}
return true;
}
/**
* 这是一个常用于String对象跟StringBuffer和StringBuilder比较的方法
* 参数是StringBuffer或StringBuilder或String或CharSequence
* StringBuffer和StringBuilder和String都实现了CharSequence接口
*/
public boolean contentEquals(CharSequence cs) {
// Argument is a StringBuffer, StringBuilder
if (cs instanceof AbstractStringBuilder) { //如果是AbstractStringBuilder抽象类或其子类
if (cs instanceof StringBuffer) { //如果是StringBuffer类型,进入同步块
synchronized(cs) {
return nonSyncContentEquals((AbstractStringBuilder)cs);
}
} else { //如果是StringBuilder类型,则进入非同步块
return nonSyncContentEquals((AbstractStringBuilder)cs);
}
}
/***下面就是String和CharSequence类型的比较算法*****/
// Argument is a String
if (cs instanceof String) {
return equals(cs);
}
// Argument is a generic CharSequence
char v1[] = value;
int n = v1.length;
if (n != cs.length()) {
return false;
}
for (int i = 0; i < n; i++) {
if (v1[i] != cs.charAt(i)) {
return false;
}
}
return true;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- equals()方法作为常用的方法,首先判断是否为同一个对象,再判断是否为要比较的类型,再判断两个对象的长度是否相等,首先从广的角度过滤筛选不符合的对象,再符合条件的对象基础上再一个一个字符的比较;
- equalsIgnoreCase()方法是对equals()方法补充,不区分大小写的判断;
- contentEquals()则是用于String对象与4种类型的判断,通常用于跟StringBuilder和StringBuffer的判断,也是对equals方法的一个补充;
8、regionMatchs()方法
/**
* 这是一个类似于equals的方法,比较的是字符串的片段,也即是部分区域的比较
* toffset是当前字符串的比较起始位置(偏移量),other是要比较的String对象参数,ooffset是要参数String的比较片段起始位置,len是两个字符串要比较的片段的长度大小
*/
public boolean regionMatches(int toffset, String other, int ooffset,
int len) {
char ta[] = value; //当前对象的值
int to = toffset; //当前对象的比较片段的起始位置,既偏移量
char pa[] = other.value; //参数,既比较字符串的值
int po = ooffset; //比较字符串的起始位置
// Note: toffset, ooffset, or len might be near -1>>>1.
if ((ooffset < 0) || (toffset < 0) //起始位置不小于0或起始位置不大于字符串长度 - 片段长度,大于就截取不到这么长的片段了
|| (toffset > (long)value.length - len)
|| (ooffset > (long)other.value.length - len)) {
return false; //惊讶脸,居然不是抛异常,而是返回false
}
while (len-- > 0) { //使用while循环,当然也可以使for循环
if (ta[to++] != pa[po++]) { //片段区域的字符元素逐个比较
return false;
}
}
return true;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
/**
* 这个跟上面的方法一样,只不过多了一个参数,既ignoreCase,既是否为区分大小写。
* 是equalsIgnoreCase()方法的片段比较版本,实际上equalsIgnoreCase()也是调用regionMatches函数
*/
public boolean regionMatches(boolean ignoreCase, int toffset,
String other, int ooffset, int len) {
char ta[] = value;
int to = toffset;
char pa[] = other.value;
int po = ooffset;
// Note: toffset, ooffset, or len might be near -1>>>1.
if ((ooffset < 0) || (toffset < 0)
|| (toffset > (long)value.length - len)
|| (ooffset > (long)other.value.length - len)) {
return false;
}
//上面的解释同上
while (len-- > 0) {
char c1 = ta[to++];
char c2 = pa[po++];
if (c1 == c2) {
continue;
}
if (ignoreCase) { //当ignoreCase为true时,既忽视大小写时
// If characters don't match but case may be ignored,
// try converting both characters to uppercase.
// If the results match, then the comparison scan should
// continue.
char u1 = Character.toUpperCase(c1); //片段中每个字符转换为大写
char u2 = Character.toUpperCase(c2);
if (u1 == u2) { //大写比较一次,如果相等则不执行下面的语句,进入下一个循环
continue;
}
// Unfortunately, conversion to uppercase does not work properly
// for the Georgian alphabet, which has strange rules about case
// conversion. So we need to make one last check before
// exiting.
if (Character.toLowerCase(u1) == Character.toLowerCase(u2)) {
//每个字符换行成小写比较一次
continue;
}
}
return false;
}
return true;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 片段比较时针对String对象的;所以如果你要跟StringBuffer和StringBuilder比较,那么记得toString;
- 如果你要进行两个字符串之间的片段比较的话,就可以使用regionMatches,如果是完整的比较那么就equals;
9、compareTo类函数和CaseInsensitiveComparator静态内部类
/**
* 这是一个比较字符串中字符大小的函数,因为String实现了Comparable<String>接口,所以重写了compareTo方法
* Comparable是排序接口。若一个类实现了Comparable接口,就意味着该类支持排序。
* 实现了Comparable接口的类的对象的列表或数组可以通过Collections.sort或Arrays.sort进行自动排序。
*
* 参数是需要比较的另一个String对象
* 返回的int类型,正数为大,负数为小,是基于字符的ASSIC码比较的
*
*/
public int compareTo(String anotherString) {
int len1 = value.length; //当前对象的长度
int len2 = anotherString.value.length; //比较对象的长度
int lim = Math.min(len1, len2); //获得最小长度
char v1[] = value; //获得当前对象的值
char v2[] = anotherString.value; //获得比较对象的值
int k = 0; //相当于for的int k = 0,就是为while循环的数组服务的
while (k < lim) { //当当前索引小于两个字符串中较短字符串的长度时,循环继续
char c1 = v1[k]; //获得当前对象的字符
char c2 = v2[k]; //获得比较对象的字符
if (c1 != c2) { //从前向后遍历,只要其实一个不相等,返回字符ASSIC的差值,int类型
return c1 - c2;
}
k++;
}
return len1 - len2; //如果两个字符串同样位置的索引都相等,返回长度差值,完全相等则为0
}
/**
* 这时一个类似compareTo功能的方法,但是不是comparable接口的方法,是String本身的方法
* 使用途径,我目前只知道可以用来不区分大小写的比较大小,但是不知道如何让它被工具类Collections和Arrays运用
*
*/
public int compareToIgnoreCase(String str) {
return CASE_INSENSITIVE_ORDER.compare(this, str);
}
/**
* 这是一个饿汉单例模式,是String类型的一个不区分大小写的比较器
* 提供给Collections和Arrays的sort方法使用
* 例如:Arrays.sort(strs,String.CASE_INSENSITIVE_ORDER);
* 效果就是会将strs字符串数组中的字符串对象进行忽视大小写的排序
*
*/
public static final Comparator<String> CASE_INSENSITIVE_ORDER
= new CaseInsensitiveComparator();
/**
* 这一个私有的静态内部类,只允许String类本身调用
* 实现了序列化接口和比较器接口,comparable接口和comparator是有区别的
* 重写了compare方法,该静态内部类实际就是一个String类的比较器
*
*/
private static class CaseInsensitiveComparator
implements Comparator<String>, java.io.Serializable {
// use serialVersionUID from JDK 1.2.2 for interoperability
private static final long serialVersionUID = 8575799808933029326L;
public int compare(String s1, String s2) {
int n1 = s1.length(); //s1字符串的长度
int n2 = s2.length(); //s2字符串的长度
int min = Math.min(n1, n2); //获得最小长度
for (int i = 0; i < min; i++) {
char c1 = s1.charAt(i); //逐一获得字符串i位置的字符
char c2 = s2.charAt(i);
if (c1 != c2) { //部分大小写比较一次
c1 = Character.toUpperCase(c1); //转换大写比较一次
c2 = Character.toUpperCase(c2);
if (c1 != c2) {
c1 = Character.toLowerCase(c1); //转换小写比较一次
c2 = Character.toLowerCase(c2);
if (c1 != c2) { //返回字符差值
// No overflow because of numeric promotion
return c1 - c2;
}
}
}
}
return n1 - n2; //如果字符相等,但是长度不等,则返回长度差值,短的教小,所以小-大为负数
}
/** Replaces the de-serialized object. */
private Object readResolve() { return CASE_INSENSITIVE_ORDER; }
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
- String实现了comparable接口,重写了compareTo方法,可以用于自己写类进行判断排序,也可以使用collections,Arrays工具类的sort进行排序。只有集合或数组中的元素实现了comparable接口,并重写了compareTo才能使用工具类排序;
- CASE_INSENSITIVE_ORDER是一个单例,是String提供为外部的比较器,该比较器的作用是忽视大小写进行比较,我们可以通过Collections或Arrays的sort方法将CASE_INSENSITIVE_ORDER比较器作为参数传入,进行排序;
10、startWith、endWith类函数
/**
* 作用就是当前对象[toffset,toffset + prefix.value.lenght]区间的字符串片段等于prefix
* 也可以说当前对象的toffset位置开始是否以prefix作为前缀
* prefix是需要判断的前缀字符串,toffset是当前对象的判断起始位置
*/
public boolean startsWith(String prefix, int toffset) {
char ta[] = value; //获得当前对象的值
int to = toffset; //获得需要判断的起始位置,偏移量
char pa[] = prefix.value; //获得前缀字符串的值
int po = 0;
int pc = prefix.value.length;
// Note: toffset might be near -1>>>1.
if ((toffset < 0) || (toffset > value.length - pc)) { //偏移量不能小于0且能截取pc个长度
return false; //不能则返回false
}
while (--pc >= 0) { //循环pc次,既prefix的长度
if (ta[to++] != pa[po++]) { //每次比较当前对象的字符串的字符是否跟prefix一样
return false; //一样则pc--,to++,po++,有一个不同则返回false
}
}
return true; //没有不一样则返回true,当前对象是以prefix在toffset位置做为开头
}
/**
* 判断当前字符串对象是否以字符串prefix起头
* 是返回true,否返回fasle
*/
public boolean startsWith(String prefix) {
return startsWith(prefix, 0);
}
/**
* 判断当前字符串对象是否以字符串prefix结尾
* 是返回true,否返回fasle
*/
public boolean endsWith(String suffix) {
//suffix是需要判断是否为尾部的字符串。
//value.length - suffix.value.length是suffix在当前对象的起始位置
return startsWith(suffix, value.length - suffix.value.length);
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
endsWith的实现也是startWith(),作用就是判断前后缀;
11、hashCode()函数
/**
* 这是String字符串重写了Object类的hashCode方法。
* 给由哈希表来实现的数据结构来使用,比如String对象要放入HashMap中。
* 如果没有重写HashCode,或HaseCode质量很差则会导致严重的后果,既不靠谱的后果
*
*/
public int hashCode() {
int h = hash; //hash是属性字段,是成员变量,所以默认为0
if (h == 0 && value.length > 0) { //如果hash为0,且字符串对象长度大于0,不为""
char val[] = value; //获得当前对象的值
//重点,String的哈希函数
for (int i = 0; i < value.length; i++) { //遍历len次
h = 31 * h + val[i]; //每次都是31 * 每次循环获得的h +第i个字符的ASSIC码
}
hash = h;
}
return h; //由此可见""空字符对象的哈希值为0
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- hashCode的重点就是哈希函数;
- String的哈希函数就是循环len次,每次循环体为 31 * 每次循环获得的hash + 第i次循环的字符;
12、indexOf、lastIndexOf类函数
/**
* 返回cn对应的字符在字符串中第一次出现的位置,从字符串的索引0位置开始遍历
*
*/
public int indexOf(int ch) {
return indexOf(ch, 0);
}
/**
* index方法就是返回ch字符第一次在字符串中出现的位置
* 既从fromIndex位置开始查找,从头向尾遍历,ch整数对应的字符在字符串中第一次出现的位置
* -1代表字符串没有这个字符,整数代表字符第一次出现在字符串的位置
*/
public int indexOf(int ch, int fromIndex) {
final int max = value.length; //获得字符串对象的长度
if (fromIndex < 0) { //如果偏移量小于0,则代表偏移量为0,校正偏移量
fromIndex = 0;
} else if (fromIndex >= max) { //如果偏移量大于最大长度,则返回-1,代表没有字符串没有ch对应的字符
// Note: fromIndex might be near -1>>>1.
return -1;
}
if (ch < Character.MIN_SUPPLEMENTARY_CODE_POINT) { //emmm,这个判断,不懂
// handle most cases here (ch is a BMP code point or a
// negative value (invalid code point))
final char[] value = this.value; //获得字符串值
for (int i = fromIndex; i < max; i++) { //从fromIndex位置开始向后遍历
if (value[i] == ch) { //只有字符串中的某个位置的元素等于ch
return i; //返回对应的位置,函数结束,既第一次出现的位置
}
}
return -1; //如果没有出现,则返回-1
} else {
return indexOfSupplementary(ch, fromIndex); //emmm,紧紧接着没看懂的地方
}
}
private int indexOfSupplementary(int ch, int fromIndex) {
if (Character.isValidCodePoint(ch)) {
final char[] value = this.value;
final char hi = Character.highSurrogate(ch);
final char lo = Character.lowSurrogate(ch);
final int max = value.length - 1;
for (int i = fromIndex; i < max; i++) {
if (value[i] == hi && value[i + 1] == lo) {
return i;
}
}
}
return -1;
}
/**
* 从尾部向头部遍历,返回cn第一次出现的位置,value.length - 1就是起点
* 为了理解,我们可以认为是返回cn对应的字符在字符串中最后出现的位置
*
* ch是字符对应的整数
*/
public int lastIndexOf(int ch) {
return lastIndexOf(ch, value.length - 1);
}
/**
* 从尾部向头部遍历,从fromIndex开始作为起点,返回ch对应字符第一次在字符串出现的位置
* 既从头向尾遍历,返回cn对应字符在字符串中最后出现的一次位置,fromIndex为结束点
*
*/
public int lastIndexOf(int ch, int fromIndex) {
if (ch < Character.MIN_SUPPLEMENTARY_CODE_POINT) { //之后不解释了,emmmmmmm
// handle most cases here (ch is a BMP code point or a
// negative value (invalid code point))
final char[] value = this.value;
//取最小值,作用就是校正,如果fromIndex传大了,就当时len - 1
int i = Math.min(fromIndex, value.length - 1);
for (; i >= 0; i--) { //算法中是从后向前遍历,直到i<0,退出循环
if (value[i] == ch) { //只有有相等,返回对应的索引位置
return i;
}
}
return -1; //没有找到则返回-1
} else {
return lastIndexOfSupplementary(ch, fromIndex);
}
}
private int lastIndexOfSupplementary(int ch, int fromIndex) {
if (Character.isValidCodePoint(ch)) {
final char[] value = this.value;
char hi = Character.highSurrogate(ch);
char lo = Character.lowSurrogate(ch);
int i = Math.min(fromIndex, value.length - 2);
for (; i >= 0; i--) {
if (value[i] == hi && value[i + 1] == lo) {
return i;
}
}
}
return -1;
}
/**
* 返回第一次出现的字符串的位置
*
*/
public int indexOf(String str) {
return indexOf(str, 0);
}
/**
*
* 从fromIndex开始遍历,返回第一次出现str字符串的位置
*
*/
public int indexOf(String str, int fromIndex) {
return indexOf(value, 0, value.length,
str.value, 0, str.value.length, fromIndex);
}
/**
* 这是一个不对外公开的静态函数
* source就是原始字符串,sourceOffset就是原始字符串的偏移量,起始位置。
* sourceCount就是原始字符串的长度,target就是要查找的字符串。
* fromIndex就是从原始字符串的第fromIndex开始遍历
*
*/
static int indexOf(char[] source, int sourceOffset, int sourceCount,
String target, int fromIndex) {
return indexOf(source, sourceOffset, sourceCount,
target.value, 0, target.value.length,
fromIndex);
}
/**
* 同是一个不对外公开的静态函数
* 比上更为强大。
* 多了一个targetOffset和targetCount,既代表别查找的字符串也可以被切割
*/
static int indexOf(char[] source, int sourceOffset, int sourceCount,
char[] target, int targetOffset, int targetCount,
int fromIndex) {
if (fromIndex >= sourceCount) { //如果查找的起点大于当前对象的大小
//如果目标字符串的长度为0,则代表目标字符串为"",""在任何字符串都会出现
//配合fromIndex >= sourceCount,所以校正第一次出现在最尾部,仅仅是校正作用
return (targetCount == 0 ? sourceCount : -1);
}
if (fromIndex < 0) { //也是校正,如果起始点小于0,则返回0
fromIndex = 0;
}
if (targetCount == 0) { //如果目标字符串长度为0,代表为"",则第一次出现在遍历起始点fromIndex
return fromIndex;
}
char first = target[targetOffset]; //目标字符串的第一个字符
int max = sourceOffset + (sourceCount - targetCount); //最大遍历次数
for (int i = sourceOffset + fromIndex; i <= max; i++) {
/* Look for first character. */
if (source[i] != first) {
while (++i <= max && source[i] != first);
}
/* Found first character, now look at the rest of v2 */
if (i <= max) {
int j = i + 1;
int end = j + targetCount - 1;
for (int k = targetOffset + 1; j < end && source[j]
== target[k]; j++, k++);
if (j == end) {
/* Found whole string. */
return i - sourceOffset;
}
}
}
return -1;
}
/**
* 查找字符串Str最后一次出现的位置
*/
public int lastIndexOf(String str) {
return lastIndexOf(str, value.length);
}
public int lastIndexOf(String str, int fromIndex) {
return lastIndexOf(value, 0, value.length,
str.value, 0, str.value.length, fromIndex);
}
static int lastIndexOf(char[] source, int sourceOffset, int sourceCount,
String target, int fromIndex) {
return lastIndexOf(source, sourceOffset, sourceCount,
target.value, 0, target.value.length,
fromIndex);
}
static int lastIndexOf(char[] source, int sourceOffset, int sourceCount,
char[] target, int targetOffset, int targetCount,
int fromIndex) {
/*
* Check arguments; return immediately where possible. For
* consistency, don't check for null str.
*/
int rightIndex = sourceCount - targetCount;
if (fromIndex < 0) {
return -1;
}
if (fromIndex > rightIndex) {
fromIndex = rightIndex;
}
/* Empty string always matches. */
if (targetCount == 0) {
return fromIndex;
}
int strLastIndex = targetOffset + targetCount - 1;
char strLastChar = target[strLastIndex];
int min = sourceOffset + targetCount - 1;
int i = min + fromIndex;
startSearchForLastChar:
while (true) {
while (i >= min && source[i] != strLastChar) {
i--;
}
if (i < min) {
return -1;
}
int j = i - 1;
int start = j - (targetCount - 1);
int k = strLastIndex - 1;
while (j > start) {
if (source[j--] != target[k--]) {
i--;
continue startSearchForLastChar;
}
}
return start - sourceOffset + 1;
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
- 79.
- 80.
- 81.
- 82.
- 83.
- 84.
- 85.
- 86.
- 87.
- 88.
- 89.
- 90.
- 91.
- 92.
- 93.
- 94.
- 95.
- 96.
- 97.
- 98.
- 99.
- 100.
- 101.
- 102.
- 103.
- 104.
- 105.
- 106.
- 107.
- 108.
- 109.
- 110.
- 111.
- 112.
- 113.
- 114.
- 115.
- 116.
- 117.
- 118.
- 119.
- 120.
- 121.
- 122.
- 123.
- 124.
- 125.
- 126.
- 127.
- 128.
- 129.
- 130.
- 131.
- 132.
- 133.
- 134.
- 135.
- 136.
- 137.
- 138.
- 139.
- 140.
- 141.
- 142.
- 143.
- 144.
- 145.
- 146.
- 147.
- 148.
- 149.
- 150.
- 151.
- 152.
- 153.
- 154.
- 155.
- 156.
- 157.
- 158.
- 159.
- 160.
- 161.
- 162.
- 163.
- 164.
- 165.
- 166.
- 167.
- 168.
- 169.
- 170.
- 171.
- 172.
- 173.
- 174.
- 175.
- 176.
- 177.
- 178.
- 179.
- 180.
- 181.
- 182.
- 183.
- 184.
- 185.
- 186.
- 187.
- 188.
- 189.
- 190.
- 191.
- 192.
- 193.
- 194.
- 195.
- 196.
- 197.
- 198.
- 199.
- 200.
- 201.
- 202.
- 203.
- 204.
- 205.
- 206.
- 207.
- 208.
- 209.
- 210.
- 211.
- 212.
- 213.
- 214.
- 215.
- 216.
- 217.
- 218.
- 219.
- 220.
只对外提供了int整形,String字符串两种参数的重载方法;
13、substring()函数
/**
* 截取当前字符串对象的片段,组成一个新的字符串对象
* beginIndex为截取的初始位置,默认截到len - 1位置
*/
public String substring(int beginIndex) {
if (beginIndex < 0) { //小于0抛异常
throw new StringIndexOutOfBoundsException(beginIndex);
}
int subLen = value.length - beginIndex; //新字符串的长度
if (subLen < 0) { //小于0抛异常
throw new StringIndexOutOfBoundsException(subLen);
}
//如果beginIndex是0,则不用截取,返回自己(非新对象),否则截取0到subLen位置,不包括(subLen)
return (beginIndex == 0) ? this : new String(value, beginIndex, subLen);
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
/**
* 截取一个区间范围
* [beginIndex,endIndex),不包括endIndex
*/
public String substring(int beginIndex, int endIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
if (endIndex > value.length) {
throw new StringIndexOutOfBoundsException(endIndex);
}
int subLen = endIndex - beginIndex;
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
return ((beginIndex == 0) && (endIndex == value.length)) ? this
: new String(value, beginIndex, subLen);
}
public CharSequence subSequence(int beginIndex, int endIndex) {
return this.substring(beginIndex, endIndex);
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- substring函数是一个不完全闭包的区间,是[beginIndex,end),不包括end位置;
- subString的原理是通过String的构造函数实现的;
14、concat()函数
/**
* String的拼接函数
* 例如:String str = "abc"; str.concat("def") output: "abcdef"
*
*/
public String concat(String str) {
int otherLen = str.length();//获得参数字符串的长度
if (otherLen == 0) { //如果长度为0,则代表不需要拼接,因为str为""
return this;
}
/****重点****/
int len = value.length; //获得当前对象的长度
//将数组扩容,将value数组拷贝到buf数组中,长度为len + str.lenght
char buf[] = Arrays.copyOf(value, len + otherLen);
str.getChars(buf, len); //然后将str字符串从buf字符数组的len位置开始覆盖,得到一个完整的buf字符数组
return new String(buf, true);//构建新的String对象,调用私有的String构造方法
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
15、replace、replaceAll类函数
//替换,将字符串中的oldChar字符全部替换成newChar
public String replace(char oldChar, char newChar) {
if (oldChar != newChar) { //如果旧字符不等于新字符的情况下
int len = value.length; //获得字符串长度
int i = -1; //flag
char[] val = value; /* avoid getfield opcode */
while (++i < len) { //循环len次
if (val[i] == oldChar) { //找到第一个旧字符,打断循环
break;
}
}
if (i < len) { //如果第一个旧字符的位置小于len
char buf[] = new char[len]; 新new一个字符数组,len个长度
for (int j = 0; j < i; j++) {
buf[j] = val[j]; 把旧字符的前面的字符都复制到新字符数组上
}
while (i < len) { //从i位置开始遍历
char c = val[i];
buf[i] = (c == oldChar) ? newChar : c; //发生旧字符就替换,不想关的则直接复制
i++;
}
return new String(buf, true); //通过新字符数组buf重构一个新String对象
}
}
return this; //如果old = new ,直接返回自己
}
//替换第一个旧字符
String replaceFirst(String regex, String replacement) {
return Pattern.compile(regex).matcher(this).replaceFirst(replacement);
}
//当不是正规表达式时,与replace效果一样,都是全体换。如果字符串的正则表达式,则规矩表达式全体替换
public String replaceAll(String regex, String replacement) {
return Pattern.compile(regex).matcher(this).replaceAll(replacement);
}
//可以用旧字符串去替换新字符串
public String replace(CharSequence target, CharSequence replacement) {
return Pattern.compile(target.toString(), Pattern.LITERAL).matcher(
this).replaceAll(Matcher.quoteReplacement(replacement.toString()));
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
从replace的算法中,我们可以发现,它不是从头开始遍历替换的,而是首先找到第一个要替换的字符,从要替换的字符开始遍历,发现一个替换一个;
16、matches()和contains()函数;
/**
* matches() 方法用于检测字符串是否匹配给定的正则表达式。
* regex -- 匹配字符串的正则表达式。
* 如:String Str = new String("www.snailmann.com");
* System.out.println(Str.matches("(.*)snailmann(.*)")); output:true
* System.out.println(Str.matches("www(.*)")); output:true
*/
public boolean matches(String regex) {
return Pattern.matches(regex, this); //实际使用的是Pattern.matches()方法
}
//是否含有CharSequence这个子类元素,通常用于StrngBuffer,StringBuilder
public boolean contains(CharSequence s) {
return indexOf(s.toString()) > -1;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
17、split()函
public String[] split(String regex, int limit) {
/* fastpath if the regex is a
(1)one-char String and this character is not one of the
RegEx's meta characters ".$|()[{^?*+\\", or
(2)two-char String and the first char is the backslash and
the second is not the ascii digit or ascii letter.
*/
char ch = 0;
if (((regex.value.length == 1 &&
".$|()[{^?*+\\".indexOf(ch = regex.charAt(0)) == -1) ||
(regex.length() == 2 &&
regex.charAt(0) == '\\' &&
(((ch = regex.charAt(1))-'0')|('9'-ch)) < 0 &&
((ch-'a')|('z'-ch)) < 0 &&
((ch-'A')|('Z'-ch)) < 0)) &&
(ch < Character.MIN_HIGH_SURROGATE ||
ch > Character.MAX_LOW_SURROGATE))
{
int off = 0;
int next = 0;
boolean limited = limit > 0;
ArrayList<String> list = new ArrayList<>();
while ((next = indexOf(ch, off)) != -1) {
if (!limited || list.size() < limit - 1) {
list.add(substring(off, next));
off = next + 1;
} else { // last one
//assert (list.size() == limit - 1);
list.add(substring(off, value.length));
off = value.length;
break;
}
}
// If no match was found, return this
if (off == 0)
return new String[]{this};
// Add remaining segment
if (!limited || list.size() < limit)
list.add(substring(off, value.length));
// Construct result
int resultSize = list.size();
if (limit == 0) {
while (resultSize > 0 && list.get(resultSize - 1).length() == 0) {
resultSize--;
}
}
String[] result = new String[resultSize];
return list.subList(0, resultSize).toArray(result);
}
return Pattern.compile(regex).split(this, limit);
}
public String[] split(String regex) {
return split(regex, 0);
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
18、join()函数
/**
* join方法是JDK1.8加入的新函数,静态方法
* 这个方法就是跟split有些对立的函数,不过join是静态方法
* delimiter就是分割符,后面就是要追加的可变参数,比如str1,str2,str3
*
* 例子:String.join(",",new String("a"),new String("b"),new String("c"))
* output: "a,b,c"
*/
public static String join(CharSequence delimiter, CharSequence... elements) {
Objects.requireNonNull(delimiter); //就是检测是否为Null,是null,抛异常
Objects.requireNonNull(elements); //不是就返回自己,即nothing happen
// Number of elements not likely worth Arrays.stream overhead.
StringJoiner joiner = new StringJoiner(delimiter); //嗯,有兴趣自己看StringJoiner类源码啦
for (CharSequence cs: elements) {
joiner.add(cs); //既用分割符delimiter将所有可变参数的字符串分割,合并成一个字符串
}
return joiner.toString();
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
/**
* 功能是一样的,不过传入的参数不同
* 这里第二个参数一般就是装着CharSequence子类的集合
* 比如String.join(",",lists)
* list可以是一个Collection接口实现类,所含元素的基类必须是CharSequence类型
* 比如String,StringBuilder,StringBuffer等
*/
public static String join(CharSequence delimiter,
Iterable<? extends CharSequence> elements) {
Objects.requireNonNull(delimiter);
Objects.requireNonNull(elements);
StringJoiner joiner = new StringJoiner(delimiter);
for (CharSequence cs: elements) {
joiner.add(cs);
}
return joiner.toString();
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- Java 1.8加入的新功能,有点跟split对立的意思,是个静态方法;
- 有两个重载方法,一个是直接传字符串数组,另个是传集合。传集合的方式是一个好功能,很方遍将集合的字符串元素拼接成一个字符串;
19、trim()函数
/**
* 去除字符串首尾部分的空值,如,' ' or " ",非""
* 原理是通过substring去实现的,首尾各一个指针
* 头指针发现空值就++,尾指针发现空值就--
* ' '的Int值为32,其实不仅仅是去空的作用,应该是整数值小于等于32的去除掉
*/
public String trim() {
int len = value.length; //代表尾指针,实际是尾指针+1的大小
int st = 0; //代表头指针
char[] val = value; /* avoid getfield opcode */
//st<len,且字符的整数值小于32则代表有空值,st++
while ((st < len) && (val[st] <= ' ')) {
st++;
}
//len - 1才是真正的尾指针,如果尾部元素的整数值<=32,则代表有空值,len--
while ((st < len) && (val[len - 1] <= ' ')) {
len--;
}
//截取st到len的字符串(不包括len位置)
return ((st > 0) || (len < value.length)) ? substring(st, len) : this;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
常见去首尾的空值,实际是去除首尾凡是小于32的字符;
20、toString()函数
//就是返回自己
public String toString() {
return this;
}
- 1.
- 2.
- 3.
- 4.
21、toCharArray()函数
/**
* 就是将String转换为字符数组并返回
*/
public char[] toCharArray() {
// Cannot use Arrays.copyOf because of class initialization order issues
char result[] = new char[value.length]; //定义一个要返回的空数组,长度为字符串长度
System.arraycopy(value, 0, result, 0, value.length); //拷贝
return result; //返回
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
22、toLowerCase()、toUpperCase()函数
//en,好长,下次再更新吧,先用着吧
public String toLowerCase(Locale locale) {
if (locale == null) {
throw new NullPointerException();
}
int firstUpper;
final int len = value.length;
/* Now check if there are any characters that need to be changed. */
scan: {
for (firstUpper = 0 ; firstUpper < len; ) {
char c = value[firstUpper];
if ((c >= Character.MIN_HIGH_SURROGATE)
&& (c <= Character.MAX_HIGH_SURROGATE)) {
int supplChar = codePointAt(firstUpper);
if (supplChar != Character.toLowerCase(supplChar)) {
break scan;
}
firstUpper += Character.charCount(supplChar);
} else {
if (c != Character.toLowerCase(c)) {
break scan;
}
firstUpper++;
}
}
return this;
}
char[] result = new char[len];
int resultOffset = 0; /* result may grow, so i+resultOffset
* is the write location in result */
/* Just copy the first few lowerCase characters. */
System.arraycopy(value, 0, result, 0, firstUpper);
String lang = locale.getLanguage();
boolean localeDependent =
(lang == "tr" || lang == "az" || lang == "lt");
char[] lowerCharArray;
int lowerChar;
int srcChar;
int srcCount;
for (int i = firstUpper; i < len; i += srcCount) {
srcChar = (int)value[i];
if ((char)srcChar >= Character.MIN_HIGH_SURROGATE
&& (char)srcChar <= Character.MAX_HIGH_SURROGATE) {
srcChar = codePointAt(i);
srcCount = Character.charCount(srcChar);
} else {
srcCount = 1;
}
if (localeDependent ||
srcChar == '\u03A3' || // GREEK CAPITAL LETTER SIGMA
srcChar == '\u0130') { // LATIN CAPITAL LETTER I WITH DOT ABOVE
lowerChar = ConditionalSpecialCasing.toLowerCaseEx(this, i, locale);
} else {
lowerChar = Character.toLowerCase(srcChar);
}
if ((lowerChar == Character.ERROR)
|| (lowerChar >= Character.MIN_SUPPLEMENTARY_CODE_POINT)) {
if (lowerChar == Character.ERROR) {
lowerCharArray =
ConditionalSpecialCasing.toLowerCaseCharArray(this, i, locale);
} else if (srcCount == 2) {
resultOffset += Character.toChars(lowerChar, result, i + resultOffset) - srcCount;
continue;
} else {
lowerCharArray = Character.toChars(lowerChar);
}
/* Grow result if needed */
int mapLen = lowerCharArray.length;
if (mapLen > srcCount) {
char[] result2 = new char[result.length + mapLen - srcCount];
System.arraycopy(result, 0, result2, 0, i + resultOffset);
result = result2;
}
for (int x = 0; x < mapLen; ++x) {
result[i + resultOffset + x] = lowerCharArray[x];
}
resultOffset += (mapLen - srcCount);
} else {
result[i + resultOffset] = (char)lowerChar;
}
}
return new String(result, 0, len + resultOffset);
}
public String toLowerCase() {
return toLowerCase(Locale.getDefault());
}
public String toUpperCase(Locale locale) {
if (locale == null) {
throw new NullPointerException();
}
int firstLower;
final int len = value.length;
/* Now check if there are any characters that need to be changed. */
scan: {
for (firstLower = 0 ; firstLower < len; ) {
int c = (int)value[firstLower];
int srcCount;
if ((c >= Character.MIN_HIGH_SURROGATE)
&& (c <= Character.MAX_HIGH_SURROGATE)) {
c = codePointAt(firstLower);
srcCount = Character.charCount(c);
} else {
srcCount = 1;
}
int upperCaseChar = Character.toUpperCaseEx(c);
if ((upperCaseChar == Character.ERROR)
|| (c != upperCaseChar)) {
break scan;
}
firstLower += srcCount;
}
return this;
}
/* result may grow, so i+resultOffset is the write location in result */
int resultOffset = 0;
char[] result = new char[len]; /* may grow */
/* Just copy the first few upperCase characters. */
System.arraycopy(value, 0, result, 0, firstLower);
String lang = locale.getLanguage();
boolean localeDependent =
(lang == "tr" || lang == "az" || lang == "lt");
char[] upperCharArray;
int upperChar;
int srcChar;
int srcCount;
for (int i = firstLower; i < len; i += srcCount) {
srcChar = (int)value[i];
if ((char)srcChar >= Character.MIN_HIGH_SURROGATE &&
(char)srcChar <= Character.MAX_HIGH_SURROGATE) {
srcChar = codePointAt(i);
srcCount = Character.charCount(srcChar);
} else {
srcCount = 1;
}
if (localeDependent) {
upperChar = ConditionalSpecialCasing.toUpperCaseEx(this, i, locale);
} else {
upperChar = Character.toUpperCaseEx(srcChar);
}
if ((upperChar == Character.ERROR)
|| (upperChar >= Character.MIN_SUPPLEMENTARY_CODE_POINT)) {
if (upperChar == Character.ERROR) {
if (localeDependent) {
upperCharArray =
ConditionalSpecialCasing.toUpperCaseCharArray(this, i, locale);
} else {
upperCharArray = Character.toUpperCaseCharArray(srcChar);
}
} else if (srcCount == 2) {
resultOffset += Character.toChars(upperChar, result, i + resultOffset) - srcCount;
continue;
} else {
upperCharArray = Character.toChars(upperChar);
}
/* Grow result if needed */
int mapLen = upperCharArray.length;
if (mapLen > srcCount) {
char[] result2 = new char[result.length + mapLen - srcCount];
System.arraycopy(result, 0, result2, 0, i + resultOffset);
result = result2;
}
for (int x = 0; x < mapLen; ++x) {
result[i + resultOffset + x] = upperCharArray[x];
}
resultOffset += (mapLen - srcCount);
} else {
result[i + resultOffset] = (char)upperChar;
}
}
return new String(result, 0, len + resultOffset);
}
public String toUpperCase() {
return toUpperCase(Locale.getDefault());
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
- 79.
- 80.
- 81.
- 82.
- 83.
- 84.
- 85.
- 86.
- 87.
- 88.
- 89.
- 90.
- 91.
- 92.
- 93.
- 94.
- 95.
- 96.
- 97.
- 98.
- 99.
- 100.
- 101.
- 102.
- 103.
- 104.
- 105.
- 106.
- 107.
- 108.
- 109.
- 110.
- 111.
- 112.
- 113.
- 114.
- 115.
- 116.
- 117.
- 118.
- 119.
- 120.
- 121.
- 122.
- 123.
- 124.
- 125.
- 126.
- 127.
- 128.
- 129.
- 130.
- 131.
- 132.
- 133.
- 134.
- 135.
- 136.
- 137.
- 138.
- 139.
- 140.
- 141.
- 142.
- 143.
- 144.
- 145.
- 146.
- 147.
- 148.
- 149.
- 150.
- 151.
- 152.
- 153.
- 154.
- 155.
- 156.
- 157.
- 158.
- 159.
- 160.
- 161.
- 162.
- 163.
- 164.
- 165.
- 166.
- 167.
- 168.
- 169.
- 170.
- 171.
- 172.
- 173.
- 174.
二、String 为什么是不可变的
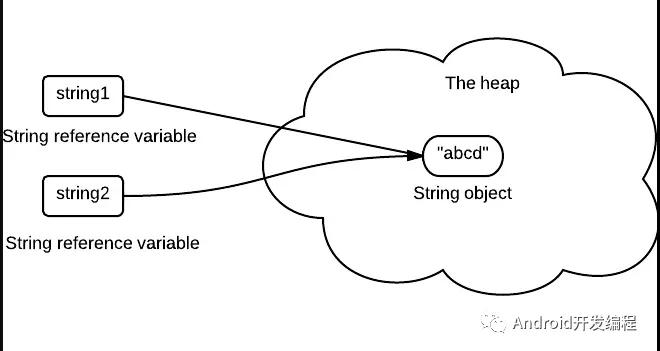
- String 不可变是因为在 JDK 中 String 类被声明为一个 final 类,且类内部的 value 字节数组也是 final 的,只有当字符串是不可变时字符串池才有可能实现,字符串池的实现可以在运行时节约很多 heap 空间,因为不同的字符串变量都指向池中的同一个字符串;
- 如果字符串是可变的则会引起很严重的安全问题,譬如数据库的用户名密码都是以字符串的形式传入来获得数据库的连接,或者在 socket 编程中主机名和端口都是以字符串的形式传入,因为字符串是不可变的,所以它的值是不可改变的,否则黑客们可以钻到空子改变字符串指向的对象的值造成安全漏洞;
- 因为字符串是不可变的,所以是多线程安全的,同一个字符串实例可以被多个线程共享,这样便不用因为线程安全问题而使用同步,字符串自己便是线程安全的;
- 因为字符串是不可变的所以在它创建的时候 hashcode 就被缓存了,不变性也保证了 hash 码的唯一性,不需要重新计算,这就使得字符串很适合作为 Map 的键,字符串的处理速度要快过其它的键对象,这就是 HashMap 中的键往往都使用字符串的原因;
总结
StringBuffer、StringBuilder和String一样,也用来代表字符串。String类是不可变类,任何对String的改变都 会引发新的String对象的生成;StringBuilder则是可变类,任何对它所指代的字符串的改变都不会产生新的对象,而StringBuilder则是线程安全版的StringBuilder;














