最近在做后端服务python到go的迁移和重构,这两种语言里,最大的特色和优势就是都支持协程。之前主要做python的性能优化和架构优化,一开始觉得两个协程原理和应用应该差不多,后来发现还是有很大的区别,今天就在这里总结一下。
什么是协程
在说它们两者区别前,我们首先聊一下什么是协程,好像它没有一个官方的定义,那就结合平时的应用经验和学习内容来谈谈自己的理解。
协程,其实可以理解为一种特殊的程序调用。特殊的是在执行过程中,在子程序(或者说函数)内部可中断,然后转而执行别的子程序,在适当的时候再返回来接着执行。
注意,它有两个特征:
- 可中断,这里的中断不是普通的函数调用,而是类似CPU的中断,CPU在这里直接释放转到其他程序断点继续执行。
- 可恢复,等到合适的时候,可以恢复到中断的地方继续执行,至于什么是合适的时候,我们后面再探讨。
和进程线程的区别
上面两个特点就导致了它相对于线程和进程切换来说极高的执行效率,为什么这么说呢?我们先老生常谈地说一下进程和线程。
进程是操作系统资源分配的基本单位,线程是操作系统调度和执行的最小单位。这两句应该是我们最常听到的两句话,拆开来说,进程是程序的启动实例,拥有代码和打开的文件资源、数据资源、独立的内存空间。线程从属于进程,是程序的实际执行者,一个进程至少包含一个主线程,也可以有更多的子线程,线程拥有自己的栈空间。无论是进程还是线程,都是由操作系统所管理和切换的。
我们再来看协程,它又叫做微线程,但其实它和进程还有线程完全不是一个维度上的概念。进程和线程的切换完全是用户无感,由操作系统控制,从用户态到内核态再到用户态。而协程的切换完全是程序代码控制的,在用户态的切换,就像函数回调的消耗一样,在线程的栈内即可完成。
python的协程(coroutine)
python的协程其实是我们通常意义上的协程Goroutine。
从概念上来讲,python的协程同样是在适当的时候可中断可恢复。那么什么是适当的时候呢,就是你认为适当的时候,因为程序在哪里发生协程切换完全控制在开发者手里。当然,对于python来说,由于GIL锁,在CPU密集的代码上做协程切换是没啥意义的,CPU本来就在忙着没偷懒,切换到其他协程,也只是在单核内换个地方忙而已。很明显,我们应该在IO密集的地方来起协程,这样可以让CPU不再空等转而去别的地方干活,才能真正发挥协程的威力。
从实现上来讲,如果熟知了python生成器,还可以将协程理解为生成器+调度策略,生成器中的yield关键字,就可以让生成器函数发生中断,而调度策略,可以驱动着协程的执行和恢复。这样就实现了协程的概念。这里的调度策略可能有很多种,简单的例如忙轮循:while True,更简单的甚至是一个for循环。就可以驱动生成器的运行,因为生成器本身也是可迭代的。复杂的比如可能是基于epool的事件循环,在python2的tornado中,以及python3的asyncio中,都对协程的用法做了更好的封装,通过yield和await就可以使用协程,通过事件循环监控文件描述符状态来驱动协程恢复执行。
我们看一个简单的协程:
- import time
- def consumer():
- r = ''
- while True:
- n = yield r
- if not n:
- return
- print('[CONSUMER] Consuming %s...' % n)
- time.sleep(1)
- r = '200 OK'
- def produce(c):
- c.next()
- n = 0
- while n < 5:
- nn = n + 1
- print('[PRODUCER] Producing %s...' % n)
- r = c.send(n)
- print('[PRODUCER] Consumer return: %s' % r)
- c.close()
- if __name__=='__main__':
- c = consumer()
- produce(c)
很明显这是一个传统的生产者-消费者模型,这里consumer函数就是一个协程(生成器),它在n = yield r 的地方发生中断,生产者produce中的c.send(n),可以驱动协程的恢复,并且向协程函数传递数据n,接收返回结果r。而while n < 5,就是我们所说的调度策略。在生产中,这种模式很适合我们来做一些pipeline数据的消费,我们不需要写死几个生产者进程几个消费者进程,而是用这种协程的方式,来实现CPU动态地分配调度。
如果你看过上篇文章的话,是不是发现这个golang中流水线模型有点像呢,也是生产者和消费者间进行通信,但go是通过channel这种安全的数据结构,为什么python不需要呢,因为python的协程是在单线程内切换本身就是安全的,换句话说,协程间本身就是串行执行的。而golang则不然。思考一个有意思的问题,如果我们将go流水线模型中channel设置为无缓冲区时,生产者绝对驱动消费者的执行,是不是就跟python很像了呢。所以python的协程从某种意义来说,是不是golang协程的一种特殊情况呢?
后端在线服务中我们更常用的python协程其实是在异步IO框架中使用,之前我们也提过python协程在IO密集的系统中使用才能发挥它的威力。并且大多数的数据中间件都已经提供支持了异步包的支持,这里顺便贴一个python3支持的异步IO库,基本支持了常见的异步数据中间件。
再看一个我们业务代码中的片段,asyncio支持的原生协程:
asyncio支持的基于epool的事件循环:
- def main():
- define_options()
- options.parse_command_line()
- # 使用uvloop代替原生事件循环
- # asyncio.set_event_loop_policy(uvloop.EventLoopPolicy())
- app = tornado.web.Application(handlershandlers=handlers, debug=options.debug)
- http_server = tornado.httpserver.HTTPServer(app)
- http_server.listen(options.port)
- asyncio.get_event_loop().run_forever()
async/await支持的原生协程:
- class RcOutputHandler(BaseHandler):
- async def post(self):
- status, msg, user = self.check_args('uid', 'order_no', 'mid', 'phone', 'name', 'apply_id',
- 'product_id')
- if status != ErrorCodeConfig.SUCCESS:
- status, msg, report = status, msg, None
- else:
- rcoutput_flow_instance = ZHANRONG_CUSTOM_PRODUCTID_RCFLOW_MAP.get(user.product_id,
- RcOutputFlowControler())
- status, msg, report = await rcoutput_flow_instance.get_rcoutput_result(user)
- res = self.generate_response_data(status, msg, report)
- await self.finish(res)
- # 陪跑流程
- await AccompanyRunningFlowControler().get_accompany_data(user)
python协程的特点
单线程内切换,适用于IO密集型程序中,可以最大化IO多路复用的效果。
无法利用多核。
协程间完全同步,不会并行。不需要考虑数据安全。
用法多样,可以用在web服务中,也可用在pipeline数据/任务消费中。
golang的协程(goroutine)
golang的协程就和传统意义上的协程不大一样了,兼具协程和线程的优势。这也是go最大的特色,就是从语言层面支持并发。Go语言里,启动一个goroutine很容易:go function 就行。
同样从概念上来讲,golang的协程同样是在适当的时候可中断可恢复。当协程中发生channel读写的阻塞或者系统调用时,就会切换到其他协程。具体的代码示例可以看上篇文章,就不再赘述了。
从实现上来说,goroutine可以在多核上运行,从而实现协程并行,我们先直接看下go的调度模型MPG。
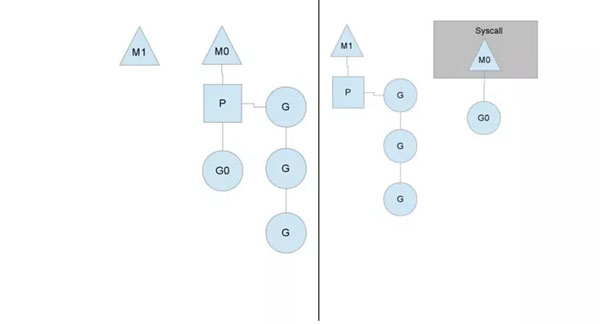
如上图,M指的是Machine,一个M直接关联了一个内核线程。由操作系统管理。
P指的是”processor”,代表了M所需的上下文环境,也是处理用户级代码逻辑的处理器。它负责衔接M和G的调度上下文,将等待执行的G与M对接。
G指的是Goroutine,其实本质上也是一种轻量级的线程。包括了调用栈,重要的调度信息,例如channel等。
每次go调用的时候,都会:
- 创建一个G对象,加入到本地队列或者全局队列
- 如果还有空闲的P,则创建一个M
- M会启动一个底层线程,循环执行能找到的G任务
- G任务的执行顺序是,先从本地队列找,本地没有则从全局队列找(一次性转移(全局G个数/P个数)个,再去其它P中找(一次性转移一半)
对于上面的第2-3步,创建一个M,其过程:
- 先找到一个空闲的P,如果没有则直接返回,(哈哈,这个地方就保证了进程不会占用超过自己设定的cpu个数)
- 调用系统api创建线程,不同的操作系统,调用不一样,其实就是和c语言创建过程是一致的
- 然后创建的这个线程里面才是真正做事的,循环执行G任务
当协程发生阻塞切换时:
- M0出让P
- 创建M1接管P及其任务队列继续执行其他G。
- 当阻塞结束后,M0会尝试获取空闲的P,失败的话,就把当前的G放到全局队列的队尾。
这里我们需要注意三点:
1、M与P的数量没有绝对关系,一个M阻塞,P就会去创建或者切换另一个M,所以,即使P的默认数量是1,也有可能会创建很多个M出来。
2、P何时创建:在确定了P的最大数量n后,运行时系统会根据这个数量创建n个P。
3、M何时创建:没有足够的M来关联P并运行其中的可运行的G。比如所有的M此时都阻塞住了,而P中还有很多就绪任务,就会去寻找空闲的M,而没有空闲的,就会去创建新的M。
Go协程的特点
协程间需要保证数据安全,比如通过channel或锁。
可以利用多核并行执行。
协程间不完全同步,可以并行运行,具体要看channel的设计。
抢占式调度,可能无法实现公平。
coroutine(python)和goroutine(go)的区别
除了python,C#, Lua语言都支持 coroutine 特性。coroutine 与 goroutine 在名字上类似,都是可中断可恢复的协程,它们之间最大的不同是,goroutine 可能在多核上发生并行执行,单但 coroutine 始终是顺序执行。也基于此,我们应该清楚coroutine适用于IO密集程序中,而goroutine在 IO密集和CPU密集中都有很好的表现。不过话说回来,go就一定比python快么,假如在完全IO并发密集的程序中,python的表现反而更好,因为单线程内的协程切换效率更高。
从运行机制上来说,coroutine 的运行机制属于协作式任务处理, 程序需要主动交出控制权,宿主才能获得控制权并将控制权交给其他 coroutine。如果开发者无意间或者故意让应用程序长时间占用 CPU,操作系统也无能为力,表现出来的效果就是计算机很容易失去响应或者死机。goroutine 属于抢占式任务处理,已经和现有的多线程和多进程任务处理非常类似, 虽然无法控制自己获取高优先度支持。但如果发现一个应用程序长时间大量地占用 CPU,那么用户有权终止这个任务。
从协程:线程的对应方式来看:
N:1,Python协程模式,多个协程在一个线程中切换。在IO密集时切换效率高,但没有用到多核
1:1,Java多线程模式,每个协程只在一个线程中运行,这样协程和线程没区别,虽然用了多核,但是线程切换开销大。
1:1,go模式,多个协程在多个线程上切换,既可以用到多核,又可以减少切换开销。(当都是cpu密集时,在多核上切换好,当都是io密集时,在单核上切换好)。
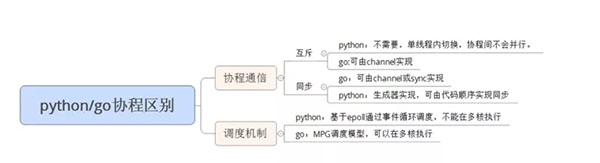
从协程通信和调度机制来看: