【51CTO.com快译】Python是机器学习不可或缺的一部分,库让我们的生活更简单。最近,我在处理机器学习项目时遇到了6个很棒的库。它们帮我节省了大量时间,本文将介绍它们。
1. clean-text
clean-text是真正很出色的库,如果您需要处理抓取内容或社交媒体数据,它应该是您的首选。最棒的是它不需要任何冗长的花哨代码或正则表达式来清理数据。不妨看几个例子:
安装
- !pip install cleantext
例子
- #Importing the clean text library
- from cleantext import clean# Sample texttext = """ Zürich, largest city of Switzerland and capital of the canton of 633Zürich. Located in an Al\u017eupine. (https://google.com). Currency is not ₹"""# Cleaning the "text" with clean textclean(text,
- fix_unicode=True,
- to_ascii=True,
- lower=True,
- no_urls=True,
- no_numbers=True,
- no_digits=True,
- no_currency_symbols=True,
- no_punct=True,
- replace_with_punct=" ",
- replace_with_url="",
- replace_with_number="",
- replace_with_digit=" ",
- replace_with_currency_symbol="Rupees")
输出

我们从上面可以看到,它在Zurich一词中含有Unicode(字母“u”已被编码)、ASCII 字符(在Al\u017eupine 中)、卢比货币符号、HTML 链接和标点符号。
您只需在clean函数中提及所需的ASCII、Unicode、URL、数字、货币和标点符号。或者,可以将它们换成上述函数中的替换参数。比如说,我将卢比符号换成了Rupees。
绝对不需要使用正则表达式或长代码。非常方便的库,如果您想清理来自抓取内容或社交媒体数据的文本,尤为方便。您还可以根据要求单独传递参数,而不是将它们全部组合在一起。
欲了解更多详细信息,请查看该GitHub 存储库。
2. drawdata
drawdata是我发现的另一个很酷的Python库。需要向团队解释机器学习概念这种情形有多常见?肯定经常发生,因为数据科学注重团队合作。该库可帮助您在Jupyter笔记本中绘制数据集。
我向团队解释机器学习概念时,确实很喜欢使用这个库。感谢创建这个库的开发人员!
Drawdata仅面向有四个类的分类问题。
安装
- !pip install drawdata
例子
- # Importing the drawdata
- from drawdata import draw_scatterdraw_scatter()
输出

执行draw_Scatter()后将打开上述绘图窗口。很显然,有四个类,即A、B、C和D。可以点击任何类,并绘制所需的点。每个类代表图形中的不同颜色。您还可以选择将数据作为csv或json文件来下载。此外,可以将数据复制到剪贴板,并从下面的代码中读取:
- #Reading the clipboardimport pandas as pd
- df = pd.read_clipboard(sep=",")
- df
这个库的局限之一是它只提供有四个类的两个数据点。但除此之外,它绝对有其价值。欲了解更多详细信息,请查看该GitHub 链接。
3. Autoviz
我永远不会忘记花在使用matplotlib进行探索性数据分析上的时间。有很多简单的可视化库。然而,我最近发现Autoviz仅用一行代码即可自动直观显示任何数据集。
安装
- !pip install autoviz
例子
我在这个例子中使用了IRIS数据集。
- # Importing Autoviz class from the autoviz library
- from autoviz.AutoViz_Class import AutoViz_Class#Initialize the Autoviz class in a object called df
- df = AutoViz_Class()# Using Iris Dataset and passing to the default parametersfilename = "Iris.csv"
- sep = ","graph = df.AutoViz(
- filename,
- sep=",",
- depVar="",
- dfte=None,
- header=0,
- verbose=0,
- lowess=False,
- chart_format="svg",
- max_rows_analyzed=150000,
- max_cols_analyzed=30,
- )
上述参数是默认值。欲了解更多信息,请点击此处。
输出
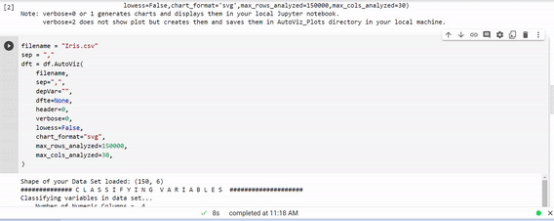
我们可以看到所有的视觉元素,仅用一行代码完成我们的EDA。有很多自动可视化库,但我特别喜欢这个库。
4. Mito
每个人都喜欢Excel,是不是?它是初次探索数据集的最简单方法之一。几个月前我遇到了Mito,但最近才试了试,我绝对爱不释手!
它是一个带GUI支持的Jupyter-lab扩展Python库,添加了电子表格功能。您可以加载 csv数据,将数据集作为电子表格来编辑,它可自动生成Pandas代码。很酷。
Mito值得写一篇完整的博文来介绍,但是今天不作详细介绍。这是为您提供的简单的任务演示。欲知更多详情,请查看此处。
安装
- #First install mitoinstaller in the command prompt
- pip install mitoinstaller# Then, run the installer in the command prompt
- python -m mitoinstaller install# Then, launch Jupyter lab or jupyter notebook from the command prompt
- python -m jupyter lab
想了解安装方面的更多信息,请查看此处。
- # Importing mitosheet and ruuning this in Jupyter labimport mitosheet
- mitosheet.sheet()
执行上述代码后,mitosheet将在jupyter实验室中打开。我使用IRIS数据集。首先,我创建了两个新列。一个是Sepal平均长度,另一个是Sepal总宽度。其次,我更改了Sepal平均长度的列名。最后,我为Sepal平均长度列创建了一个直方图。
执行上述步骤后,代码会自动生成。
输出
为上述步骤生成以下代码:
- from mitosheet import * # Import necessary functions from Mito
- register_analysis('UUID-119387c0-fc9b-4b04-9053-802c0d428285') # Let Mito know which analysis is being run# Imported C:\Users\Dhilip\Downloads\archive (29)\Iris.csv
- import pandas as pd
- Iris_csv = pd.read_csv('C:\Users\Dhilip\Downloads\archive (29)\Iris.csv')# Added column G to Iris_csv
- Iris_csv.insert(6, 'G', 0)# Set G in Iris_csv to =AVG(SepalLengthCm)
- Iris_csv['G'] = AVG(Iris_csv['SepalLengthCm'])# Renamed G to Avg_Sepal in Iris_csv
- Iris_csv.rename(columns={"G": "Avg_Sepal"}, inplace=True)
5. Gramformer
另一个出色的库Gramformer基于生成模型,可帮助我们纠正句子中的语法。这个库有三个模型,有检测器、荧光笔和校正器。检测器识别文本是否有错误的语法。荧光笔标记错误的部分,校正器修复错误。Gramformer是完全开源的软件,目前处于早期阶段。但它不适合长段落,因为它仅适用于句子,已针对64个字符长度的句子进行了训练。
目前,校正器和荧光笔模型切实有用。不妨看几个例子。
安装
- !pip3 install -U git+https://github.com/PrithivirajDamodaran/Gramformer.git
为Gramformer创建实例
- gf = Gramformer(models = 1, use_gpu = False) # 1=corrector, 2=detector (presently model 1 is working, 2 has not implemented)

例子
- #Giving sample text for correction under gf.correctgf.correct(""" New Zealand is island countrys in southwestern Paciific Ocaen. Country population was 5 million """)
输出
我们从上面的输出中可以看到它纠正了语法,甚至纠正了拼写错误。一个非常棒的库,功能也很棒。我还没有在这里试过荧光笔,您可以试试,查看该GitHub文档,以获取更多详细信息。
6. Styleformer
在使用Gramformer方面的良好体验鼓励我寻找更多独特的库。我因此发现了Styleformer,这是另一个极具出色的Python库。Gramformer和Styleformer都是由Prithiviraj Damodaran创建的,两者都基于生成模型。感谢创建者开源。
Styleformer帮助将随意句转换成正式句、将正式句转换成随意句、将主动句转换成被动句以及将被动句转换成主动句。
不妨看几个例子:
安装
- !pip install git+https://github.com/PrithivirajDamodaran/Styleformer.git
为Styleformer创建实例
- sf = Styleformer(style = 0)# style = [0=Casual to Formal, 1=Formal to Casual, 2=Active to Passive, 3=Passive to Active etc..]
例子
- # Converting casual to formal sf.transfer("I gotta go")
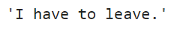
- # Formal to casual
- sf = Styleformer(style = 1) # 1 -> Formal to casual# Converting formal to casual
- sf.transfer("Please leave this place")

- # Active to Passive
- sf = Styleformer(style = 2) # 2-> Active to Passive# Converting active to passive
- sf.transfer("We are going to watch a movie tonight.")

- # passive to active
- sf = Styleformer(style = 2) # 2-> Active to Passive# Converting passive to active
- sf.transfer("Tenants are protected by leases")

看到上面的输出,转换准确。我使用这个库将随意句转换成正式句,尤其是在我有一次分析时用于社交媒体帖子。欲了解更多详细信息,请查看GitHub。
您可能熟悉了前面提到的一些库,但像Gramformer和Styleformer这样的库是最近出现的库。它们被严重低估了,当然值得广为人知,因为它们为我节省了大量时间,我在NLP项目中大量使用它们。
原文标题:6 Cool Python Libraries That I Came Across Recently,作者:Dhilip Subramanian
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】