如果我们有几十万个网站需要检测,该如何实现?手工检测吗?当然不行,这是非常不现实的,只有自动化才是正确的选择,那么如何自动化实现?
对于几十个网站的目标,如果要对所有网站进行扫描,每一个网站的扫描都需要比较长的时间,而且,其中难免有很多无效网站,如果我们可以将无效网站排除,那么我们就可以节省扫描的时间,从而提升检测效率。
自动化检测,离不开自动化的工具,今天来为大家分享一款命令行版的 HTTP 工具集 httpx,项目地址:
https://github.com/projectdiscovery/httpx
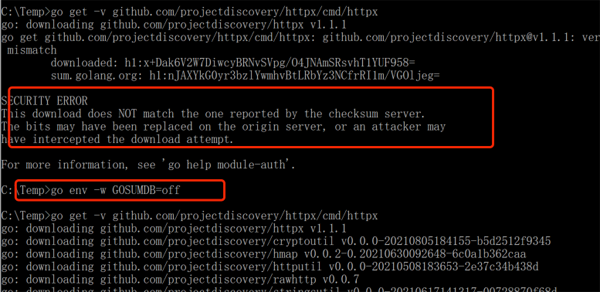
该工具使用 go 语言编写,安装方式也比较简单,需要提前安装 go 环境,安装完成之后需要换成国内的代理,否则安装的时候,会出现连接超时的问题,安装命令如下:
- go get -v github.com/projectdiscovery/httpx/cmd/httpx
Windows 下安装时报错,然后执行下面的命令之后,再进行安装就可以了:
- go env -w GOSUMDB=off
安装完成之后,查看帮助信息:
- [root@vultrguest ~]# httpx -h
- Usage of httpx:
- -H value # 自定义 header,比如 UA、cookie 等
- Custom Header
- -allow value
- Allowlist ip/cidr
- -body string
- Content to send in body with HTTP request
- -cdn # 根据页面返回 header,判断是否存在 cdn
- Check if domain's ip belongs to known CDN (akamai, cloudflare, ..)
- -cname
- Output first cname
- -content-length # 输出返回包的长度
- Extracts content length
- -content-type # 输出网站的内容类型
- Extracts content-type
- -csp-probe
- Send HTTP probes on the extracted CSP domains
- -debug
- Debug mode
- -deny value
- Denylist ip/cidr
- -exclude-cdn
- Skip full port scans for CDNs (only checks for 80,443)
- -extract-regex string
- Extract Regex
- -fc string # 过滤掉某些状态码的网站,比如 404、500 等
- Filter status code
- -filter-regex string
- Filter Regex
- -filter-string string
- Filter String
- -fl string
- Filter content length
- -follow-host-redirects
- Only follow redirects on the same host
- -follow-redirects
- Follow Redirects
- -http-proxy string # 设置请求代理
- HTTP Proxy, eg http://127.0.0.1:8080
- -http2
- HTTP2 probe
- -include-chain
- Show Raw HTTP Chain In Output (-json only)
- -include-response
- Show Raw HTTP Response In Output (-json only)
- -ip # 输出域名对应的 IP
- Output target ip
- -json
- JSON Output
- -l string
- File containing domains
- -location
- Extracts location header
- -match-regex string
- Match Regex
- -match-string string
- Match string
- -mc string
- Match status code
- -method
- Display request method
- -ml string
- Match content length
- -no-color
- No Color
- -no-fallback
- If HTTPS on port 443 is successful on default configuration, probes also port 80 for HTTP
- -no-fallback-scheme
- The tool will respect and attempt the scheme specified in the url (if HTTPS is specified no HTTP is attempted)
- -o string
- File to write output to (optional)
- -path string
- Request path/file (example '/api')
- -paths string
- Command separated paths or file containing one path per line (example '/api/v1,/apiv2')
- -pipeline
- HTTP1.1 Pipeline
- -ports value
- ports range (nmap syntax: eg 1,2-10,11)
- -probe
- Display probe status
- -random-agent
- Use randomly selected HTTP User-Agent header value (default true)
- -rate-limit int
- Maximum requests to send per second (default 150)
- -request string
- File containing raw request
- -response-in-json
- Show Raw HTTP Response In Output (-json only) (deprecated)
- -response-size-to-read int
- Max response size to read in bytes (default - unlimited) (default 2147483647)
- -response-size-to-save int
- Max response size to save in bytes (default - unlimited) (default 2147483647)
- -response-time
- Output the response time
- -resume
- Resume scan using resume.cfg
- -retries int
- Number of retries
- -silent
- Silent mode
- -sr
- Save response to file (default 'output')
- -srd string
- Save response directory (default "output")
- -stats
- Enable statistic on keypress (terminal may become unresponsive till the end)
- -status-code
- Extracts status code
- -store-chain
- Save chain to file (default 'output')
- -tech-detect
- Perform wappalyzer based technology detection
- -threads int
- Number of threads (default 50)
- -timeout int
- Timeout in seconds (default 5)
- -title
- Extracts title
- -tls-grab
- Perform TLS data grabbing
- -tls-probe
- Send HTTP probes on the extracted TLS domains
- -unsafe
- Send raw requests skipping golang normalization
- -verbose
- Verbose Mode
- -version
- Show version of httpx
- -vhost
- Check for VHOSTs
- -vhost-input
- Get a list of vhosts as input
- -web-server
- Extracts server header
- -websocket
- Prints out if the server exposes a websocket
- -x string
- Request Methods, use ALL to check all verbs ()
使用场景一:检查网站是否存活
将网站列表保存为一个文本,比如:
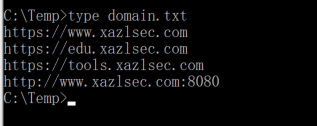
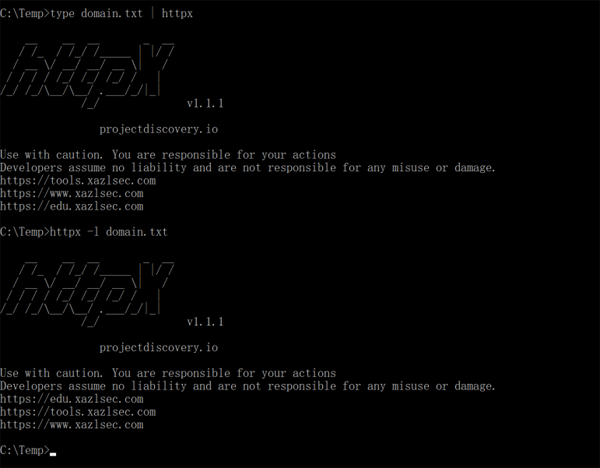
最简单的命令,无需加任何参数:
- type domain.txt | httpx (windows)/ cat domain.txt | httpx (Linux)
或者
- httpx -l domain.txt
无法访问的网站,在结果中未进行显示:
这个工具在 linux 下使用显示会比较好看,如果我们想要显示连接失败的网站,可以使用命令:
- httpx -l domain.txt -silent -probe

使用场景二:获取网站 Title 、状态码等
通过获取网站的 Title 和状态码,可以排除大量非正常网站,比如 404、500 等状态码,还有很多域名指向同一个网站,然后通过网站标题可以去掉大量重复的网站域名,从而提升检测的效率。
- httpx -l domain.txt -title -tech-detect -status-code
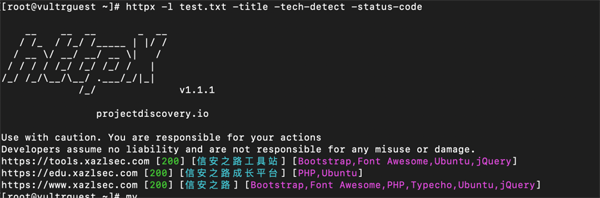
对于有大量无法访问网站的情况,默认的超时时间是 5 秒,想要提升速度,可以将超时时间,比如:
- httpx -l domain.txt -title -tech-detect -status-code -timeout 2
目标多的情况下,可以结合多线程技术,使用参数 -threads:
- httpx -l domain.txt -title -tech-detect -status-code -timeout 2 -threads 30
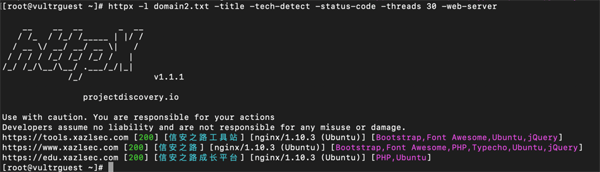
如果还想获取目标网的服务器信息,可以使用 -web-server 参数:
- httpx -l domain2.txt -title -tech-detect -status-code -threads 30 -web-server
使用场景三:使用域名作为目标,获取网站信息
当我们收集了很多域名,并没有生成网站的链接,httpx 通用可以检测域名上搭建的网站信息,比如下面的域名:
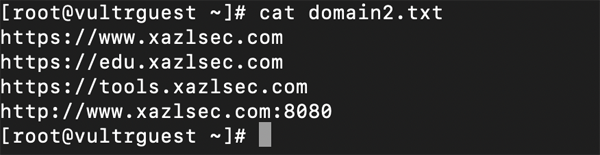
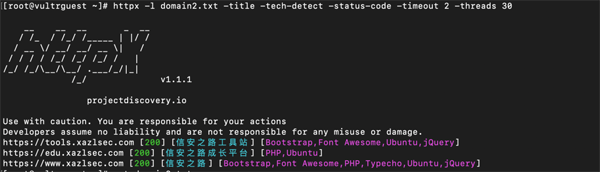
通用使用获取 title 的命令:
- httpx -l domain2.txt -title -tech-detect -status-code -timeout 2 -threads 30
总结
本文对 httpx 做了一个简单的使用,工具好坏主要与使用者面临的问题和需求决定,当你需要时,它是一个提效的好帮手,当你不需要时,他不过就是个工具而已,对于大量目标的状态检测和信息收集,httpx 是个不错的帮手,在这几天的实战训练营中,这个工具也是可以使用的,当然,如果自己有编码基础,写脚本来实现自己的目标,更高效且高度自定义化,满足自己的各种需求,公开的工具多少是有缺陷的,作者不可能把所有状况都考虑到,而且在使用的时候,目标过多的情况下,会出现各种各样的 bug,参与训练营的小伙伴,多少都体验多了。