大家好,我卡颂。
今天来聊聊如何用90行代码实现一个现代JS模块打包器。
我们的打包器虽然迷你,但是实现了webpack的核心功能。
而且,我知道你看到大段代码头疼,所以这篇文章都是图。看完感兴趣的话,这里是完整代码的仓库地址[1],只有90行代码哦。
让我们愉快的开始吧。
生成依赖图
如果应用是个毛线团的话,那么入口文件就是线头。打包器要做的第一件事是:
顺着线头开始滤清整条线的走向
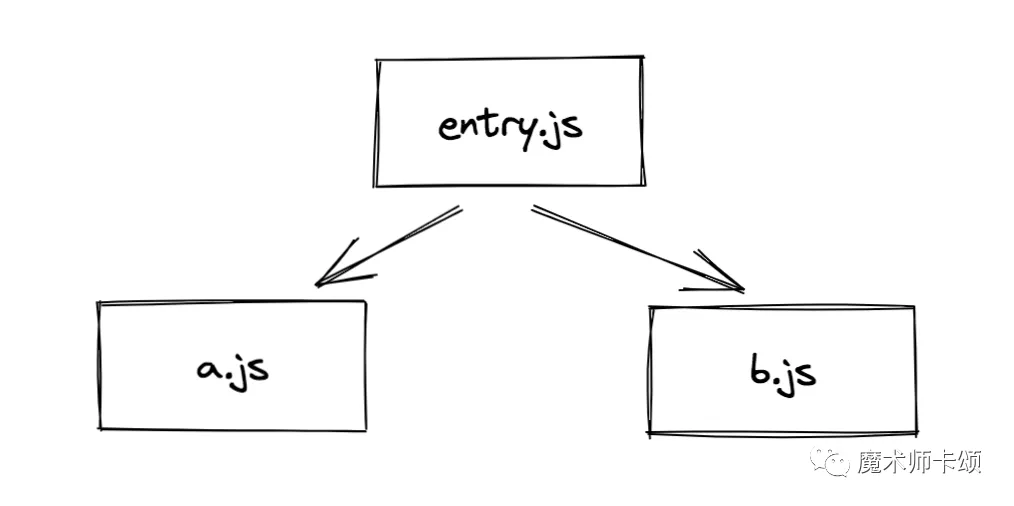
假设入口文件是entry.js:
- // entry.js
- import a from './a.js';
- import b from './b.js';
- console.log(a, b);
他依赖了a.js与b.js。
em... 有点太简陋了,让我们再扩展下a.js与b.js:
- // a.js
- import c from './c.js';
- // ...
- // b.js
- import d from './d.js';
- import e from './e.js';
- // ...
所以整个依赖关系是这样:
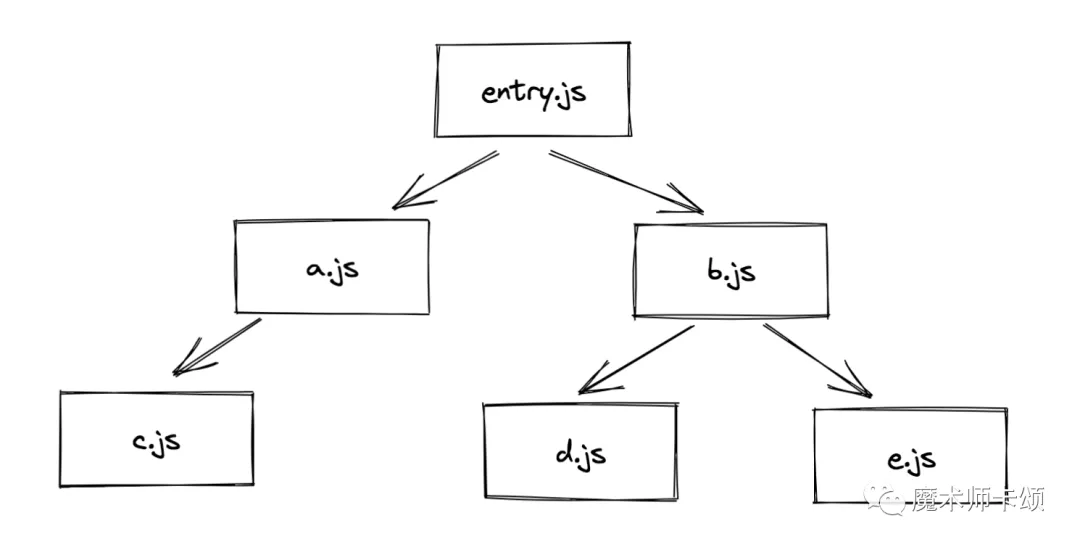
打包器会从入口文件开始,尝试建立模块(即js文件)间的依赖关系,也就是刚才我们讲的「顺着线头开始滤清整条线的走向」。
模块间的依赖关系可以通过分析模块代码中的import 声明语句得知。
为了能分析import 声明语句,可以使用babel等编译工具将模块代码分解为AST(抽象语法树)。
遍历AST,类型为ImportDeclaration的节点就是import声明语句。
最后,我们将AST重新转换为可执行的目标代码,可能还需要根据代码要执行的宿主环境(一般为浏览器)对代码做一些转换。
比如,浏览器不支持import './a.js'这样的ESM语法,那么我们需要将所有ESM语法转为CJS语法。
- // 源代码
- import './a.js';
- // 转换后
- require('./a.js');
所以,对于任一模块(js文件),会经历:

右边包含目标代码和模块间依赖关系的数据结构被称为asset。
每个asset可以通过模块间依赖关系找到依赖的模块,重复这一过程,生成新的asset,最终形成整个应用所有asset间的依赖关系:
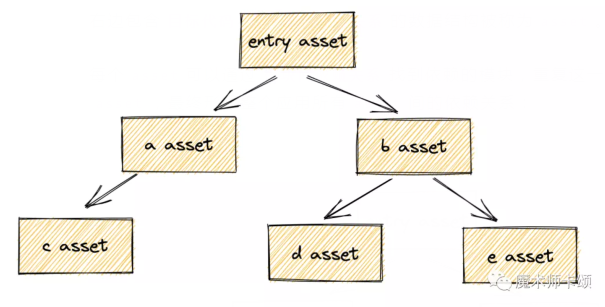
应用完整的依赖关系被称为「依赖图」(dependency graph)。
打包代码
接下来,只需要遍历「依赖图」,将所有asset的目标代码打包在一起就行。
所有代码会被打包在一个「立即执行函数」中:
- (function(modules) {
- // 打包好的代码
- })(modules)
modules中保存了所有asset及他们之间的依赖关系。
如果你对modules的细节感兴趣,可以去文末仓库里翻代码
刚才说过,asset的目标代码是CJS规范的,类似:
- // entry.js
- require('./a.js');
- require('./b.js');
这意味着我们需要实现:
- require方法(用于引入依赖的其他asset的目标代码)
- module对象(用于保存当前asset的目标代码执行后导出的数据)
同时,为了防止不同asset的目标代码中的变量互相污染,每个目标代码需要独立的作用域。
我们将目标代码包裹在函数中:
- // 我们操作的是字符串模版
- `function (require, module, exports) {
- ${asset.code}
- }`
所以,最终打包的结果为:
- (function(modules) {
- function require() {// ...}
- require(入口asset的ID)
- })(modules)
这段字符串被包裹在浏览器
这段字符串被包裹在浏览器<script>标签内,会依次执行:
- require(入口asset的ID),执行入口asset的目标代码
- 目标代码内部会调用require执行其他asset的目标代码
- 一步步执行下去...
总结
打包器的工作原理分为两步:
- 从入口文件开始遍历,生成「依赖图」
- 根据依赖图,将代码打包进一个「立即执行函数」
这个打包器还很稚嫩,缺失很多必要的功能,比如:
- 解决循环依赖
- 缓存
但是瑕不掩瑜嘛~
参考资料
[1]完整代码的仓库地址: https://github.com/BetaSu/minipack