本文转载自微信公众号「小姐姐味道」,作者小姐姐养的狗。转载本文请联系小姐姐味道公众号。
你要知道,在线下、在测试开发环境能够发现的bug,都是些小儿科。只有到了线上才发生的bug,你才会知道它的凶残。数据错乱,逻辑中断,进程死亡。处在如此问题场景下的你,are you ok?
问题频繁发生,故障难以定位,CTO怒而呵斥,“你们难道不能在线上调试一下问题的发生根本么?要形成一套可行的方法论!”
从这种训话可以看出,CTO的技术水准一般,但太极修养十分了得。在平常的表达中,在一篇报告中,不要出现技术术语,不要把话说的太死,是一个CTO基本的素养。
但是活儿总是要有人干的,公司所有人都打太极,最后将形成一个虚幻的世界,不利于整个组织的健康发展。今天,我们就简单的聊一下线上程序,要留下哪些证据。
1. 证据
问题之所以成为问题,是因为它留下了证据。没有证据的问题,你虽然看到了影响结果,但是你无法找到元凶。比如,某个同学在办公室的饮水机里放了巴豆,让所有同事都畅快淋漓的发泄了一下。但由于没有安装监控,你也就无法找到这个可恶的同学。
而且问题通常都具有人性化,当它发现无法发现它的时候,它总会再次出现。就如同罪犯发现了漏洞,还会再次尝试利用它。
所以,要想处理线上问题,你需要留下问题发生的证据,这是重中之重。如果没有这些东西,你的公司,绝对会陷入无尽的扯皮之中。
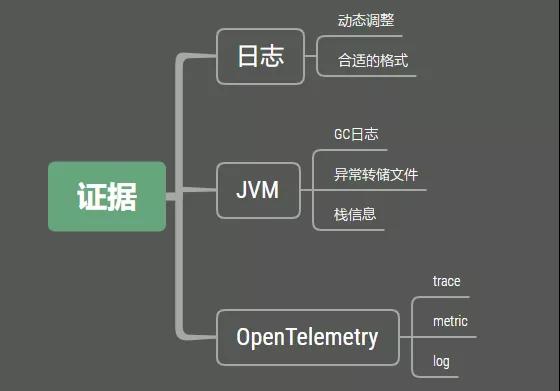
1.1 日志证据
日志是最常见的作法。通过在程序逻辑中进行打点,配合Logback等日志框架,可以快速定位到发生问题的代码行。我们需要看一下bug的详细发生过程,对可能发生问题的逻辑进行详细的日志记录,进行更加细致的日志输出,在发生问题的时候,就可以切换到debug进行调试。
在SpringBoot中,可以通过actuator来动态调整相应类的日志级别。在下面的路径中,可以看到日志级别的具体信息。
localhost:8080/actuator/{loggers}
- 1.
通过发送POST请求到具体的日志控制器,就可以实现动态更改。
curl -X POST \
http://localhost:8080/actuator/loggers/<Package/Class> \
-d '{"configuredLevel":"<LEVEL>"}'
- 1.
- 2.
- 3.
但bug的发生频率可能很小,我们开启了debug后,可能等了好几天,同样的问题也没有再次复现,这是最让人头疼的事情。
接入一些APM平台是非常有必要的。最新的opentelemetry,同时记录了Traces, Metrics, Logs等三种格式的数据,对问题的分析支持非常大。
记录详细的监控信息也是非常有必要的,可以看到监控指标的历史时序,辅助我们查找排查问题。
1.2 JVM证据
在事故出现的时候,通常并不是那么温柔。你可能在半夜里就能接到报警电话,这是因为很多定时任务都设定在夜深人静的时候执行。
这个时候,再去看 jstat 已经来不及了,我们需要保留现场。这个便是看门狗的工作,看门狗可以通过设置一些 JVM 参数进行配置。
Java8的gc日志配置和8以后的版本差异很大,下面直接给出相应的配置示例。
java8:
-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps
-XX:+PrintGCApplicationStoppedTime -XX:+PrintTenuringDistribution
-Xloggc:/tmp/logs/gc_%p.log -XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/tmp/logs -XX:ErrorFile=/tmp/logs/hs_error_pid%p.log
-XX:-OmitStackTraceInFastThrow
- 1.
- 2.
- 3.
- 4.
- 5.
java8+:
-verbose:gc -Xlog:gc,gc+ref=debug,gc+heap=debug,gc+age=trace:file
=/tmp/logs/gc_%p.log:tags,uptime,time,level -Xlog:safepoint:file=/tmp
/logs/safepoint_%p.log:tags,uptime,time,level -XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/tmp/logs -XX:ErrorFile=/tmp/logs/hs_error_pid%p.log
-XX:-OmitStackTraceInFastThrow
- 1.
- 2.
- 3.
- 4.
- 5.
2. 分析
问题分析是最困难的一环。有了证据环节,我们就避免了靠猜去找问题的现状,但如何在这些分散的信息和复杂的路径中,找到问题的根本原因,是非常有挑战的。
如果是大范围的bug,那么强烈建议直接在线上进行调试。不太推荐使用Arthas等工具动态的修改字节码进行测试,当然也不推荐IDEA的远程调试。相反,推荐使用类似金丝雀发布的方式,导出非常小的一部分流量,构造一个新的版本进行测试。如果你没有金丝雀发布平台,类似Nginx的负载均衡工具也可以通过权重做到类似的事情。
在这个新的小版本中,你可以尽情的输出日志,把所有的输入输出都打印到日志里。大多数情况下,你能够通过日志很快发现这个问题。
缓存会是bug产生非常重要的一个影响因素。因为缓存和db通常不在一个基础设施中,通常会存在一致性问题。即使选用了cache aside pattern,实现了延时双删,在某些情况下,数据仍然会发生一致性问题。这种偶发的不一致问题,因为发生频率低,触发条件苛刻,一点发生会非常难以发现。所以一些非常关键的业务,通常会提供一键删除缓存的功能。如果清掉缓存之后,问题消失,那大可不必浪费时间花费在这种小概率事件上。
多线程是另外一个容易出现问题的地方,每个逻辑都必须仔细的进行评估。因为多线程是异步的,有些逻辑只能通过手工去推理,灰度的线上程序可能永远没有条件走到这一步。这个时候,给线程起一个合适的名字,是非常有必要的,这通常是由ThreadFactory去做的。
比如,有些同学,喜欢将字符串拼接起来直接打印成日志。
logger.debug("the request info: userId:{} tel:{},role:{},timeCost:{}")
- 1.
这二种方式不是说不好,但在你处理问题的时候,就会遇到很多障碍,日志的输出不应该太随意。
logger.debug("the request info$ userId{}|tel:{}|role:{}|timeCost:{}")
- 1.
通过这种方式,我们可以很容易的利用各种Linux工具,比如sed、awk、grep进行分析。在日志输出的时候,要有一定的技巧,否则你就只能使用肉眼去分析。
3. 总结
要想解决问题,就得通过不断的试错。试错并不是盲目的,我们必须要有各种证据的支持。手机证据最有效的是通过日志,尤其是有一定规律的日志信息。除了分析正常的业务逻辑,数据问题或者多线程问题,同样是常见的bug引起原因。
日志系统与监控系统,对硬件的需求是比较大的,尤其是你的请求体和返回体比较大的情况下,对存储和计算资源的额要求更是高。它的硬件成本,在整个基础设施中,占比也是比较高的。但这些证据信息,对分析问题来说,是非常有必要的。所以即使比较贵,很多公司依然会有很大的投入在这上面,包括硬件投入和人力投入。
如果你想要这样的功能但是没钱也没人?其实那也没关系,雇一个会扯皮的CTO,你的这些问题和bug,都会在你面前消失不见的。
作者简介:小姐姐味道 (xjjdog),一个不允许程序员走弯路的公众号。聚焦基础架构和Linux。十年架构,日百亿流量,与你探讨高并发世界,给你不一样的味道。