












本文转载自微信公众号「Python技术」,作者派森酱。转载本文请联系Python技术公众号。
自从我们的 Python技术 作为迁移后,大家留言互动好不热闹,感谢大家一如既往地支持,我将再接再厉,为大家提供更多更有用的文章。
今天我来分享一个迁移过程的幕后小故事,有料,有趣,来听听吧。
并不丝滑
迁移公众号,是一个腾讯提供的业务,就是将原公号主体切换到另一个公号上,然后收回原公号。
其中大部分是腾讯来完成的,但还有些工作,需要自己处理,比如迁移公号的 关键字消息回复。
虽然事情不大,但很重要,做不好,读者就会找不见源码,影响大家学习效率。
但单操作起来还是比较费劲的,因为需要同时登录两个公众号,打开两个页面,来回切换着操作,很不方便,而且容易搞错。
怎么办,求神拜佛肯定是没有用的,不过有位大神还真得去拜拜 —— Python!
提取数据
既然网页上能看到,那么就一定能用爬虫获取到。
咱们故伎重演,浏览器中按下 F12,进入魔法世界。
你知道百度的校招启事就藏在这里吗?
别说是我告诉你的
第一步,先清空请求记录,刷新页面,然后从第一条请求记录开始分析。
实际上就是看看请求的返回值,是否包含了,页面上列表中的数据。
幸运的是第一条就是,不过呢,数据不是直接给的,而是返回了一个大 js 脚本,当页面加载后,运算出的。
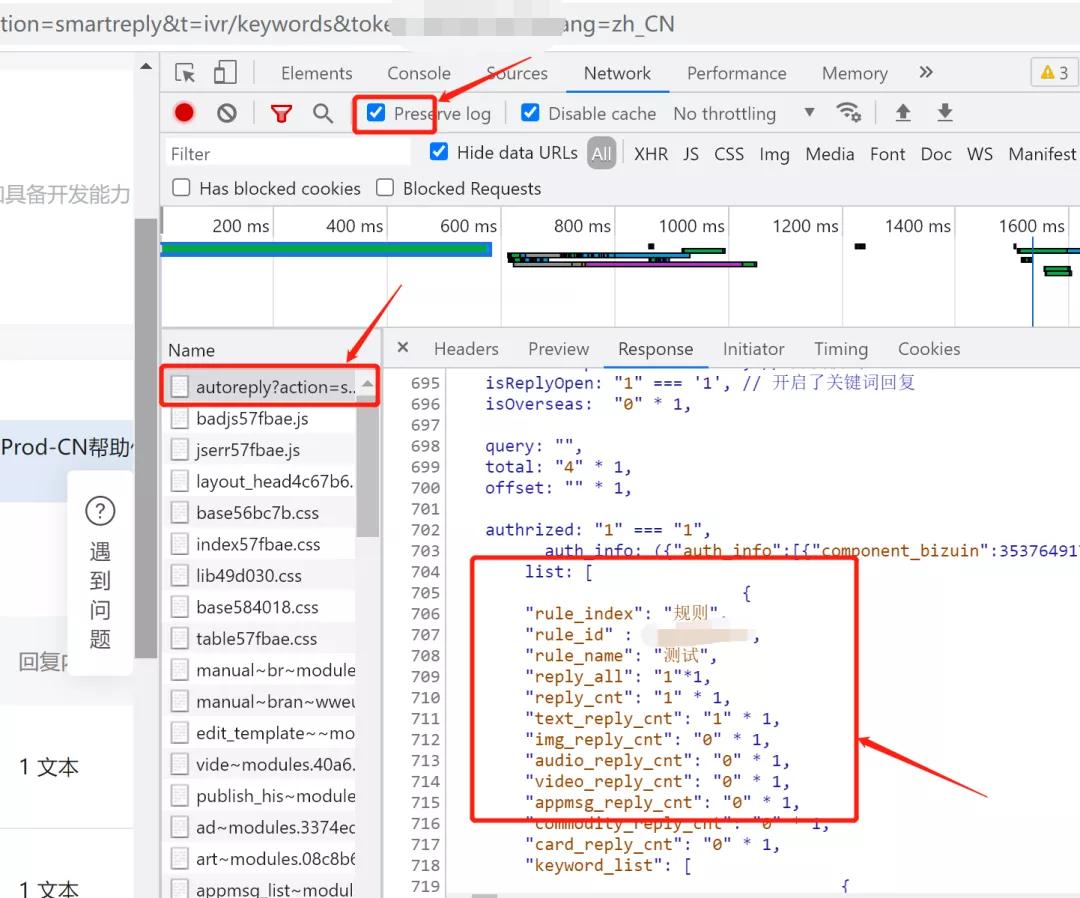
分析请求
需要勾上 Perserve Log 否则有用页面切换可能看不见请求记录
这个不是困难,将js复制出来,提取其中关键字回复的信息整理一下就可以了。
问题是,每页只显示十条,有二十多页,复杂的成本有点高呀。
得想想办法,观察了一下网址,其中有两个参数,一个是 count,另一个是 offset,很熟悉呀,不和分页参数是一回事儿吗?
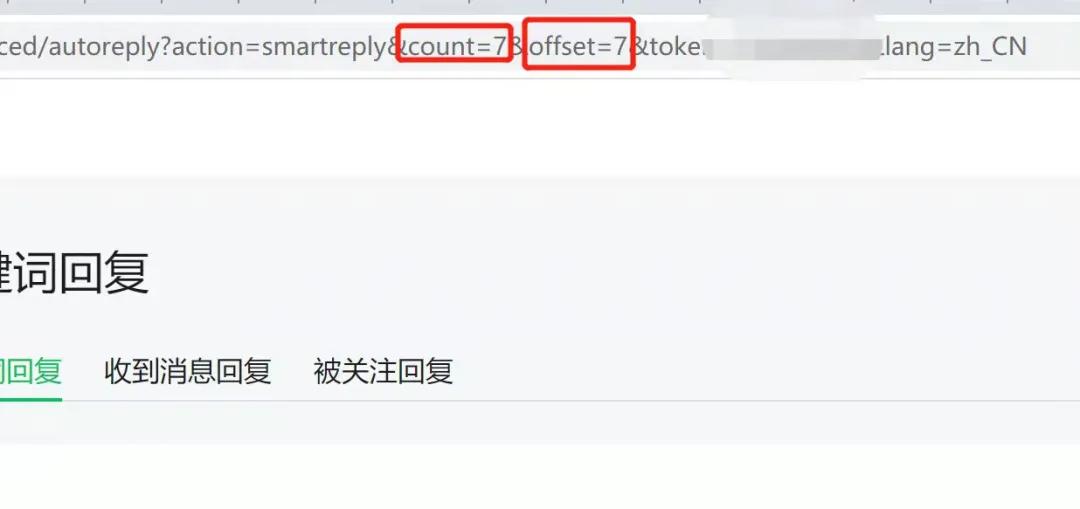
分析请求
改一下试试,将 count 改为 1000,offset 改为 0,意思是从第一行开始,获取一千条,按下回车 ……
搞定!
仔细检查,确实返回了所有记录,因为总共也没有一千行。
现在可以蛮干了,因为就干一次。
复制出来,用文本编辑器(最好支持列编辑)简单处理一下,得到一个 json
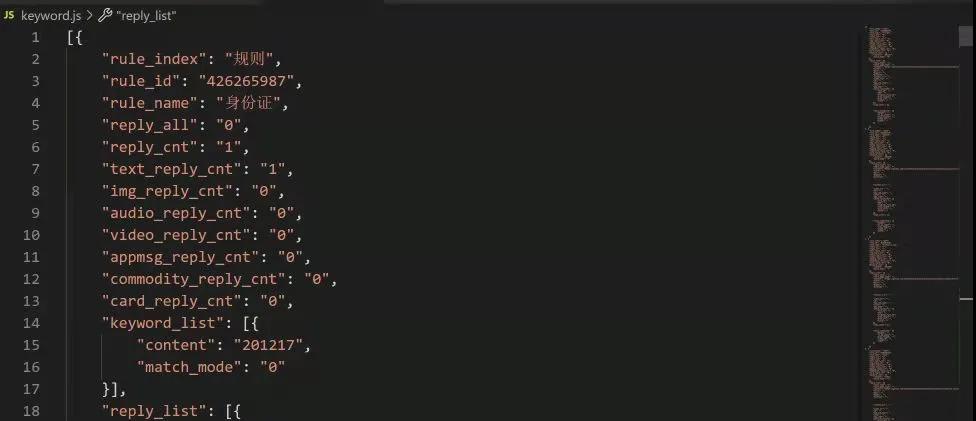
json
所以方法需要灵活应用,如果能直接通过程序获取最好,如果不行,手动辅助也是可以的。
分析写入
接下来,才是重头戏,如何将这些数据写入。
进入新公众号的管理后台,新建一个关键字回复,分析下请求,此时别忘记,打开开发者工具(浏览器上按 F12)。
一般提交类请求都是第一个,看一下果然是,不过肉眼看不清具体数据,怎么办?
还记得前面好多次提到的将请求复制为 curl bash 吗?对就用它,在请求上右键,选择 Copy as cURL(bash)
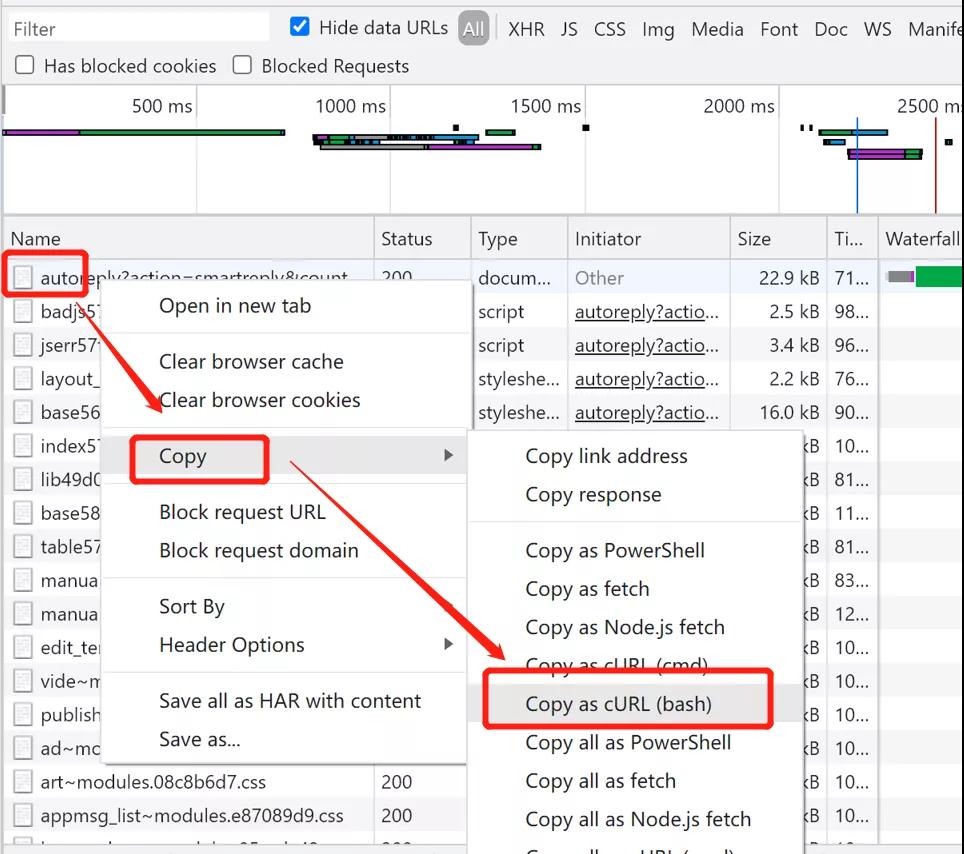
copy cURL
放在哪里呢?当然不是放在文本文件里了,除非你是想做一下暂存。
我们直接粘贴到 https://curl.trillworks.com/ 里,可以直接获得 转化好的 Python 代码。
然后将 Python 代码复制到文件中,执行看看效果,果然,新增了一条记录。
数据处理
下面分析请求数据, 与刚才 json 文件中的做对比,一般名称很相近,所以容易找出来。
字段相同,可能是来自同一个架构设计,不太可能出自不同的团队开发,哈哈,我竟然看的这么深!
这样边找边写,等找完,代码也就完成了,像这样:
- data = {
- 'replytype': 'smartreply',
- 'ruleid': '0',
- 'rulename': kw['rule_name'], # 规则名
- 'allreply': kw['reply_all'], # 全回复
- 'replycnt': kw['reply_cnt'], # 回复数量
- 'keywordcnt': len(kw['keyword_list']), # 关键字数量
- 'keyword0': kw['keyword_list'][0]['content'], # 关键字
- 'matchmode0': kw['keyword_list'][0]['match_mode'], # 匹配模式
- 'type0': kw['reply_list'][0]['reply_type'], # 消息类型
- 'fileid0': 'undefined',
- 'content0': kw['reply_list'][0]['content'], # 回复内容
- 'token': '105xxxx502',
- 'lang': 'zh_CN',
- 'f': 'json',
- 'ajax': '1'
- }
- kw 就是从 json 中读取到的每一行回复数据
- token 是登录凭证,如果不传或错误,会创建失败,说明腾讯还是做了很多防护的
集成
现在将各部分的代码组合起来。
首先是解析 json 的代码:
- with open("keyword.js", 'r', encoding='utf-8') as word:
- d = json.load(word)
超级简单,利用 json 库将 keyword.js 文件中的内容转化为 Python List 对象
然后是数据组合,代码已经在上面展示了。
最后发送请求:
- add(data)
- print('处理完成,休息2秒...')
- time.sleep(2)
- add 方法是将 Python 请求代码做了下封装,便于调用,其中将动态的部分用,通过参数 data 替换
- time.sleep(2) 是一种友好,休息 2 秒钟,以免惊醒反爬神兽(友情提醒:惊醒反爬机制一点都不好玩)
好了,这样搞定了,写代码用了一个多小时,跑完不到两分钟。
收尾
美中不足的是,代码只照顾了大多数的一条消息的回复(代码中直接获取的数组中第一个元素, 如 kw['reply_list'][0]),还有几条回复是多条消息,照顾不上。
如果要照顾,可能的话 80% 以上的时间,以兼容 20% 不到的情况,不划算。
怎么办?凉拌!—— 直接手动添加。
哈哈,我很乐意做这一点手工活儿。
总结
类似这样的方式,用在其他的地方,完全是可以的,比如之前的约马程序,训练营运营数据提取 等等,都是一样的套路:
- 分析浏览器的请求,推荐使用 Chrome 浏览器
- 将请求复制为 cURL bash 命令
- 粘贴到 CURL to Python 中提取 Python 代码
- 修改 Python 代码,以动态处理数据
就这么简单,Get 到了吗?
那,赶紧找个地方试试吧。
每天进步一点点,生活更美好,比心!


















