












图片来自 包图网
某日,阿雄跑去面试!于是有如下情形:
- 面试官:"阿雄是吧,做做自我介绍!"
- 阿雄:"我叫阿雄,来自某 a 国际电商公司!"
- 面试官:"我看你项目里用了 Elasticsearch,你是怎么同步数据的呢?"
- 阿雄:"在代码里写入数据库的时候,同时再写入 Elasticsearch!"
- 面试官:"那你如何保证写入数据库,和写入 Elasticsearch 原子性问题呢?万一写入数据库成功了,写入 Elasticsearch 失败了怎么处理?"
- 阿雄:"我还是回去等通知吧!"
其实这篇文章所探讨的数据同步策略并不限于某两种固定的存储系统之间,而想去探讨一种通用的数据同步策略。
主要分为以下三个部分:
- 背景介绍
- 双写缺点
- 改良方案
背景介绍
话说阿雄在加入某 a 国际电商公司的时候,业务系统十分简单,一个 DataBase 就能搞定一切!
可是某 a 国际电商公司在产品韩的领导下,业务增长迅速,阿雄发现了数据库越来越慢,于是乎阿雄加入了一些缓存,如 Redis 来缓存一些数据,提高系统的响应能力。
又过了一段时间,产品韩发现搜索的速度灰常慢,让阿雄去改。阿雄在网上发现,现在业内都用一些 Elasticsearch 做一些全文检索的操作,于是乎阿雄将一些需要全文检索的数据放入 Elasticsearch,提高了系统的搜索能力!
随着数据的膨胀,阿雄慢慢的发现了,对数据库做一些数据分析操作,性能明显的跟不上了。于是乎阿雄将数据库里的数据,导入 Hadoop,然后进行数据分析。
省略一万字….最后,阿雄和产品韩幸福的在一起了。OK,好,现在分析上面的场景!思考第一个问题。
①在 DataBase,Redis,Elasticsearch,Hadoop 中的数据是有关系的,还是彼此独立的?
显然是有关系的,在这几个数据源中的数据都是相关的。只是格式不一样而已!
例如,对于一条 Product 数据,在数据库里是:

在 Redis 里就是 key 为 product:pId:1,value 是:
- { "pId": "1",
- "productName": "macbook"
- }
如上所示,只是数据格式不一样而已!那好,现在思考第二个问题。
②既然这些数据源之间数据是相关的,如何保证这几个数据源之间数据一致性?
一种比较简单且容易想到的方案是,hardcode 在程序中。例如现在有两个数据源 DataSouce1 和 DataSource2,我们往里头写数据。
代码如下:
- ProductService{
- \\省略
- public void syncData(){
- x1. writeDataSource1();
- x2. writeDataSource2();
- }
- }
这就是我们标题中所提到的双写!那么,双写会带来什么坏处呢?OK,继续往下看!
双写缺点
①一致性问题
打个比方我们现在有两个 client,同时往两个 DataSouce 写数据:
- 一个 client 往里头入 X 为 1
- 一个 client 往里头入 X 为 5
那么会有如下情形出现:
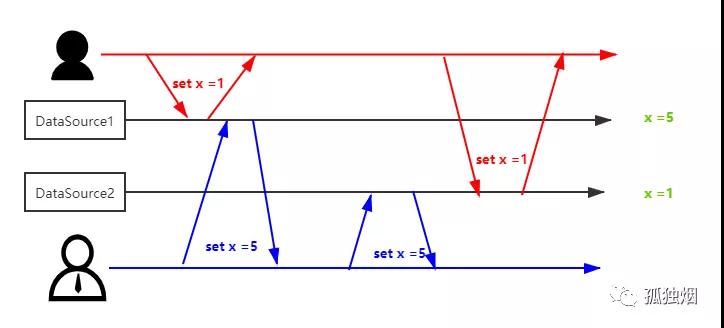
如图所示,两个 DataSouce 的数据就不一致了,一个为 1,一个为 5。除非接下来有一个新的请求,对 x 数据发生了变更,才能修正这种现象!否则,你可能永远都发现不了。
②原子性问题
因为我们需要同时往 DataSource1 和 DataSource2 一起写数据,你需要保证:
- x1. writeDataSource1();
- x2. writeDataSource2();
这两个操作一起成功,或者一起失败!如果采用双写的方法,是避不开这个问题的!
那么有没有通用的办法来解决这些问题呢?有的,只要能按顺序记录数据的变更即可!那具体怎么做呢,我们继续往下看!
改良方案
假设,如果我们能将数据按顺序记录,写入某个消息队列,然后其他系统按消息顺序恢复数据,看看 what happen?
此时架构图如下:
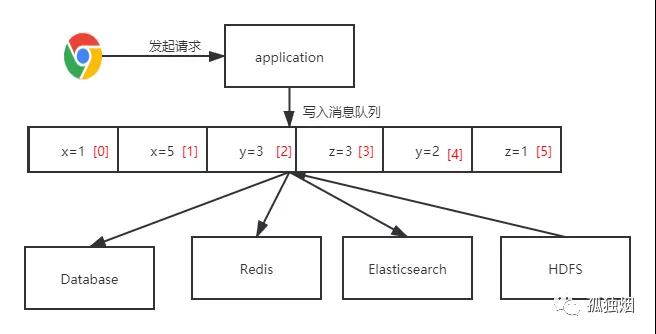
在该架构下,所有的数据变更写入一个消息队列里去。其他各数据源从消息队列里恢复数据即可!
那么,此时还有一致性问题,和原子性问题么?
①一致性问题
OK,这种情况下,各个数据源之间数据肯定是一致的。因为写入顺序已经在消息队列中定义好,各数据源按照消息队列中的消息顺序,恢复数据即可,并不存在竞争现象。因此,不会出现不一致的问题!
②原子性问题
OK,这种情况下,如果写入 DataSource 失败会怎么样?例如出现了网络问题,这条消息恢复失败了。
这个问题其实好解决,一般我们在顺序根据消息恢复数据的时候,会记录下坐标。如果写入失败,停止恢复数据。下次从该坐标处恢复数据即可。
但是在上面那张图中,写入 DataBase 是异步写入的。这样就不符合很多业务场景的"写后即读"的要求,因此,在实际落地中,做了一些变更!通用做法是去提取数据库的变化!
如下图所示:
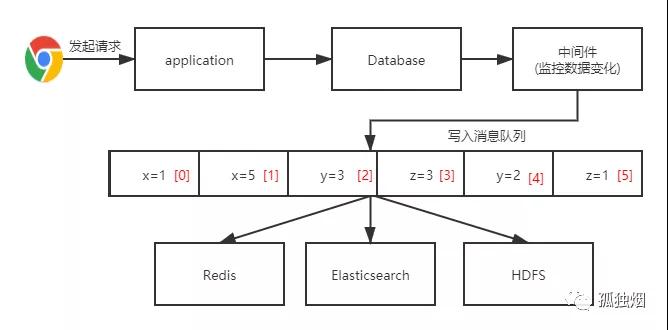
在该图中的中间件,例如 Oracle 中的 oracle golden gate 可以提取数据变化。
MySQL 中的 Canal 能提取数据的变化。至于消息队列,可以选用 Kafka。直接提取数据变化到 Kafka 中,其他数据源从 Kafka 中获取数据,避免了直接双写从而导致一致性和原子性问题。
总结
本文讨论了在项目中常见的数据同步问题,希望大家有所收获。
作者:孤独烟
编辑:陶家龙
出处:转载自公众号孤独烟(ID:zrj_guduyan)


























