【51CTO.com快译】Pandas是数据科学家处理数据的最重要的Python软件包之一。Pandas库主要用于数据探索和可视化,它随带大量的内置函数。Pandas无法处理大型数据集,因为它无法在CPU的所有核心上扩展或分布进程。
为了加快计算速度,您可以使用CPU的所有核心,并加快工作流程。有各种开源库,包括Dask、Vaex、Modin、Pandarallel和PyPolars等,它们可以在CPU的多个核心上并行处理计算。我们在本文中将讨论PyPolars库的实现和用法,并将其性能与Pandas库进行比较。
PyPolars是什么?
PyPolars是一个类似Pandas的开源Python数据框库。PyPolars利用CPU的所有可用核心,因此处理计算比Pandas更快。PyPolars有一个类似Pandas的API。它是用Rust和Python包装器编写的。
理想情况下,当数据对于Pandas而言太大、对于Spark而言太小时,使用 PyPolars。
PyPolars如何工作?
PyPolars库有两个API,一个是Eager API,另一个是Lazy API。Eager API与Pandas的API非常相似,执行完成后立即获得结果,这类似Pandas。Lazy API与Spark非常相似,一执行查询,就形成地图或方案。然后在CPU的所有核心上并行执行。

图1. PyPolars API
PyPolars基本上是连接到Polars库的Python绑定。PyPolars库好用的地方是,其API与Pandas相似,这使开发人员更容易使用。
安装:
可以使用以下命令从PyPl安装 PyPolars:
- pip install py-polars
并使用以下命令导入库:
- iport pypolars as pl
基准时间约束:
为了演示,我使用了一个含有2500万个实例的大型数据集(~6.4Gb)。
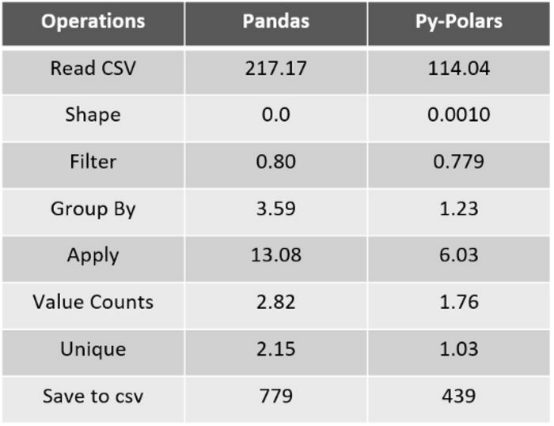
图2. Pandas和Py-Polars基本操作的基准时间数
针对使用Pandas和PyPolars库的一些基本操作的上述基准时间数,我们可以观察到 PyPolars几乎比Pandas快2到3倍。
现在我们知道PyPolars有一个与Pandas非常相似的API,但仍没有涵盖Pandas的所有函数。比如说,PyPolars中就没有.describe()函数,相反我们可以使用df_pypolars.to_pandas().describe()。
用法:
- import pandas as pd
- import numpy as np
- import pypolars as pl
- import time
- WARNING!
- py-polars was renamed to polars, please install polars!
- https://pypi.org/project/polars/
- path = "data.csv"
读取数据:
- s = time.time()
- df_pandas = pd.read_csv(path)
- e = time.time()
- pd_time = e - s
- print("Pandas Loading Time = {}".format(pd_time))
- C:\ProgramData\Anaconda3\lib\site-packages\IPython\core\interactiveshell.py:3071: DtypeWarning: Columns (2,7,14) have mixed types.Specify dtype option on import or set low_memory=False.
- has_raised = await self.run_ast_nodes(code_ast.body, cell_name,
- Pandas Loading Time = 217.1734380722046
- s = time.time()
- df_pypolars = pl.read_csv(path)
- e = time.time()
- pl_time = e - s
- print("PyPolars Loading Time = {}".format(pl_time))
- PyPolars Loading Time = 114.0408570766449
shape:
- s = time.time()
- print(df_pandas.shape)
- e = time.time()
- pd_time = e - s
- print("Pandas Shape Time = {}".format(pd_time))
- (25366521, 19)
- Pandas Shape Time = 0.0
- s = time.time()
- print(df_pypolars.shape)
- e = time.time()
- pl_time = e - s
- print("PyPolars Shape Time = {}".format(pl_time))
- (25366521, 19)
- PyPolars Shape Time = 0.0010192394256591797
过滤:
- s = time.time()
- temp = df_pandas[df_pandas['PAID_AMT']>500]
- e = time.time()
- pd_time = e - s
- print("Pandas Filter Time = {}".format(pd_time))
- Pandas Filter Time = 0.8010377883911133
- s = time.time()
- temp = df_pypolars[df_pypolars['PAID_AMT']>500]
- e = time.time()
- pl_time = e - s
- print("PyPolars Filter Time = {}".format(pl_time))
- PyPolars Filter Time = 0.7790462970733643
Groupby:
- s = time.time()
- temp = df_pandas.groupby(by="MARKET_SEGMENT").agg({'PAID_AMT':np.sum, 'QTY_DISPENSED':np.mean})
- e = time.time()
- pd_time = e - s
- print("Pandas GroupBy Time = {}".format(pd_time))
- Pandas GroupBy Time = 3.5932095050811768
- s = time.time()
- temp = df_pypolars.groupby(by="MARKET_SEGMENT").agg({'PAID_AMT':np.sum, 'QTY_DISPENSED':np.mean})
- e = time.time()
- pd_time = e - s
- print("PyPolars GroupBy Time = {}".format(pd_time))
- PyPolars GroupBy Time = 1.2332513110957213
运用函数:
- %%time
- s = time.time()
- temp = df_pandas['PAID_AMT'].apply(round)
- e = time.time()
- pd_time = e - s
- print("Pandas Loading Time = {}".format(pd_time))
- Pandas Loading Time = 13.081078290939331
- Wall time: 13.1 s
- s = time.time()
- temp = df_pypolars['PAID_AMT'].apply(round)
- e = time.time()
- pd_time = e - s
- print("PyPolars Loading Time = {}".format(pd_time))
- PyPolars Loading Time = 6.03610580444336
值计算:
- %%time
- s = time.time()
- temp = df_pandas['MARKET_SEGMENT'].value_counts()
- e = time.time()
- pd_time = e - s
- print("Pandas ValueCounts Time = {}".format(pd_time))
- Pandas ValueCounts Time = 2.8194501399993896
- Wall time: 2.82 s
- %%time
- s = time.time()
- temp = df_pypolars['MARKET_SEGMENT'].value_counts()
- e = time.time()
- pd_time = e - s
- print("PyPolars ValueCounts Time = {}".format(pd_time))
- PyPolars ValueCounts Time = 1.7622406482696533
- Wall time: 1.76 s
描述:
- %%time
- s = time.time()
- temp = df_pandas.describe()
- e = time.time()
- pd_time = e - s
- print("Pandas Describe Time = {}".format(pd_time))
- Pandas Describe Time = 15.48347520828247
- Wall time: 15.5 s
- %%time
- s = time.time()
- temp = df_pypolars[temp_cols].to_pandas().describe()
- e = time.time()
- pd_time = e - s
- print("PyPolars Describe Time = {}".format(pd_time))
- PyPolars Describe Time = 44.31892013549805
- Wall time: 44.3 s
去重:
- %%time
- s = time.time()
- temp = df_pandas['MARKET_SEGMENT'].unique()
- e = time.time()
- pd_time = e - s
- print("Pandas Unique Time = {}".format(pd_time))
- Pandas Unique Time = 2.1443397998809814
- Wall time: 2.15 s
- %%time
- s = time.time()
- temp = df_pypolars['MARKET_SEGMENT'].unique()
- e = time.time()
- pd_time = e - s
- print("PyPolars Unique Time = {}".format(pd_time))
- PyPolars Unique Time = 1.0320448875427246
- Wall time: 1.03 s
保存数据:
- s = time.time()
- df_pandas.to_csv("delete_1May.csv", index=False)
- e = time.time()
- pd_time = e - s
- print("Pandas Saving Time = {}".format(pd_time))
- Pandas Saving Time = 779.0419402122498
- s = time.time()
- df_pypolars.to_csv("delete_1May.csv")
- e = time.time()
- pd_time = e - s
- print("PyPolars Saving Time = {}".format(pd_time))
- PyPolars Saving Time = 439.16817021369934
结论
我们在本文中简要介绍了PyPolars库,包括它的实现、用法以及在一些基本操作中将其基准时间数与Pandas相比较的结果。请注意,PyPolars的工作方式与Pandas非常相似, PyPolars是一种节省内存的库,因为它支持的内存是不可变内存。
可以阅读说明文档详细了解该库。还有其他各种开源库来并行处理Pandas操作,并加快进程。
参考资料:
Polars说明文档和GitHub存储库:https://github.com/ritchie46/polars
[1] Polars Documentation and GitHub repository: https://github.com/ritchie46/polars
原文标题:Make Pandas 3 Times Faster with PyPolars,作者:Satyam Kumar
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】