













本文转载自微信公众号「数仓宝贝库」,作者赵志强 等。转载本文请联系数仓宝贝库公众号。
现实世界中的数据量越来越大,也越来越容易受到噪声、缺失值和不一致数据等的影响。数据库太大,如若有不同的来源,那么脏数据问题一定会存在,这是不可避免的。为了使数据中的各种问题对我们的建模影响最小化,需要对数据进行预处理。
在实际操作中,数据预处理通常分为两大步,一是数据清洗,二是数据的基本分析。这两步并不一定是按先后顺序进行的,通常也会相互影响。比如,有的错误数据(不可能出现的极值),必须通过基本的统计分析才能发现。
有一种说法,数据的预处理会占据绝大部分的工作量,有的甚至会达到所有工作量的80%,建模和算法真正的工作量其实只有20%。这个结论在互联网或者传统IT领域,特别是面对大量的非结构化数据时,确实是事实。
所以第一步,也是非常关键的一步,就是数据清理。为了清理数据,我们必须要知道可能存在的问题,才能针对相应的问题设计相应的方法。
原始数据可能存在如下三种问题。
- 数据缺失:数据缺失的问题在高频数据里面特别常见。而且由于很多投资者是自己实时下载的数据,因此即使之后发现也很难弥补。
- 噪声或者离群点:由于系统或者人为的失误,导致数据出现明显的错误,比如某支股票的价格本应在12元左右,结果突然出现了100元的价格数据。
- 数据不一致:很多投资者,为了确保数据正确性,会使用多个数据源进行交叉验证,这时往往会出现数据不一致的问题。即使是同一个数据源,有时候也会出现数据不一致的问题。比如期货行情数据,Wind、文华、MC的数据都有可能出现不一致的问题,数据频率越高,不一致的可能性就越大。
01缺失值
针对缺失值,实际操作中,需要两套程序:一套程序是检查缺失值,一套程序是填补缺失值。一般流程是,先检查缺失值,研究缺失值,选择填补方法,进行填补,然后再次检查。这样迭代循环,直到将数据缺失控制在可接受范围内。
缺失值,也有多种类型,一种是“正常缺失”,比如股票在某一天停牌,那么这一天的交易数据就是没有的。一种是“非正常缺失”,比如明明有交易,但就是没有交易数据。
举个例子,在下载5分钟数据的时候,发现20160104的数据都有缺失,但Wind上的数据又显示当天的交易情况为“交易”。实际情况是当天发生了“熔断”,因为是新的机制,所以Wind还没来得及准备一个字段用于表示当天的交易状态。这种情况就属于数据的“正常缺失”,只是交易状态与数据不一致而已。Wind的交易状态字段如下图所示。
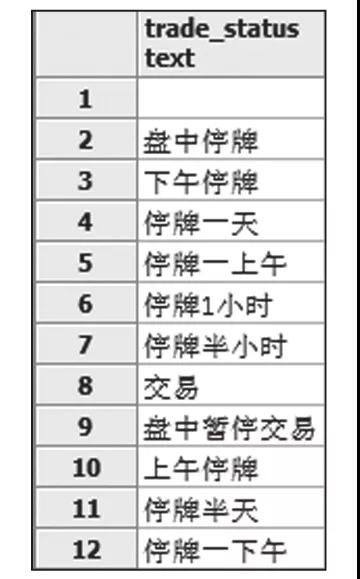
在检查缺失值时,这两种缺失需要分辨清楚,因为不同的缺失值,处理方法也不一样。检查好缺失值之后,就需要进行处理了。先处理“非正常缺失”,一般流程具体如下。
1)检查提取数据是否出错。有时候,数据源本身是完整的,然而自己在提取数据的时候出现了问题。比如,笔者在使用市场上某家的金融高频数据的时候,下载5分钟数据计算高频波动率,发现存在很多缺失的数据。经该公司后台查询后发现,他们的数据库其实是有这个数据的,这说明是在下载数据的过程中出现了问题。
2)从其他数据源提取。有的数据源本身就缺失了数据,对于这种情况可以再寻找另外一个数据源进行补充。
算法填充。有的时候,我们没有办法使用多数据源进行补充,而且有的数据本身就有空缺,无法补充。这个时候,可以退而求其次,使用算法填充。
常用算法有向前填充和向后填充两种。所谓向前填充是指使用之前最近的一个数据对空值进行填充。向后填充是指使用之后最近的一个数据对空值进行填充。
Pandas提供了一个函数用于数据填充。示例代码如下:
- df = pd.DataFrame([[np.nan, 2, np.nan, 0],
- ... [3, 4, np.nan, 1],
- ... [np.nan, np.nan, np.nan, 5],
- ... [np.nan, 3, np.nan, 4]],
- ... columns=list('ABCD'))
- df
- A B C D
- 0 NaN 2.0 NaN 0
- 1 3.0 4.0 NaN 1
- 2 NaN NaN NaN 5
向前填充的示例代码如下:
- df.fillna(method='ffill')
- A B C D
- 0 NaN 2.0 NaN 0
- 1 3.0 4.0 NaN 1
- 2 3.0 4.0 NaN 5
- 3 3.0 3.0 NaN 4
除了向前填充,该函数也支持向后填充,不过,要使用特定的值进行填充。
有的数据发生了缺失,无法使用简单的向前填充或向后填充来处理。比如,使用Wind下载a股复权数据,会发现交易状态trade_status在1999年之前都是空值,虽然实际上是有交易的,但如果直接按照trade_status=‘交易’这个条件来筛选,将会把1999年之前的所有数据都去掉。这个时候就需要根据逻辑设计一个算法来进行填充,比如将成交量volume>0的都填充为“交易”。
02 噪声或者离群点
噪声或离群点的问题一般有两种情况,一种是数据错误导致的,比如本来应该是10.0的数据,错误显示为10000;另一种则是其本身是真实数据,但就是离群点,比如金融危机中的收益率或者波动率,可能就非常极端,成为离群点。
一般的处理步骤具体如下。
1)通过一定的算法识别出离群点。一般是使用该数据标准差的多少倍来判断。比如正太分布中,正负标准差3倍以上的概率是99.7%,可以将其认定为可疑离群点。
2)人工判断离群点是属于错误数据导致的,还是正常的离群点。
3)对离群点进行处理。一般来说,错误的离群点需要更正或者删除。正常的离群点则需要另外建模进行分析。
03数据不一致
为了确保数据的准确性,有时候需要使用多种数据源进行交叉验证。比如,在研究港股的时候,对比了Wind和Bloomberg的后复权数据之后,发现两者存在很大的差别,这就是数据不一致的问题,但我们并不能确定哪一个才是正确的,于是又加入了同花顺和CSMAR的数据进行对比,发现后者与Wind的数据是一致的。所以可以确认是Bloomberg的问题,因而采用Wind的数据。
当然,在实际工作中,数据清理的问题要远远多于这里介绍的几种,需要系统性地、仔细地去处理。
本书摘编自《Python量化投资:技术、模型与策略》,经出版方授权发布。














