SQL是一种简单易用的业务逻辑表达语言,但随着扫描数据量和查询复杂度的增加,查询性能会变得越来越慢。想要对SQL进行调优,往往需要关注以下几个部分:
需要了解引擎架构:用户往往需要对SQL引擎的架构特点有一定的了解,才能和业务的数据分布特征以及业务场景特征完美结合,来进行数据建模,从而设计出符合SQL引擎架构特点的表结构。
SQL特征差异较大:即席查询的SQL往往变化较大,包括参与Join的表个数、Join条件、分组聚合的字段个数以及过滤条件等。
数据特征差异较大:用户的数据分布特征是会随着业务特征的变化而变化的,如果一直按照最初的建模方式和SQL语句,也是无法保障能发挥出SQL引擎的最大优势,数据特征或者业务模型的变化,都会导致SQL性能回退。
基于此,AnalyticDB For MySQL(新一代云原生实时数据仓库,语法兼容MySQL,以下简称ADB)为用户提供了高效、实时、功能丰富并且智能化的「SQL智能诊断」和「SQL智能调优」功能,提供用户SQL性能调优的思路、方向和具体的方法,降低用户使用成本,提高用户使用ADB的效率。
下面我们通过「发现慢查询」+「诊断慢查询」两个步骤,并结合一个场景Case,来介绍ADB新发布的「SQL智能诊断」功能。(PS:「SQL智能调优」会在后续版本中发布)
一、发现慢查询
用户要定位慢查询,首先需要找到慢查询。ADB的用户控制台提供了多样的方式来帮助用户,例如「甘特图」和「查询列表」等,都可以在多个维度进行检索,帮助用户快速定位慢查询,而且诊断工具确保用户可以进行最近两周的全量查询检索和分析。
(一)甘特图
用户可以通过「集群控制台」-「诊断与优化」 - 「SQL诊断」进入SQL智能诊断功能。
首先会看到一个甘特图(也称泳道图,查询从不同的泳道流过,这里的泳道并不是ADB的查询队列,只是为了区分开不同时间执行的查询),甘特图以图形化的方式形象的展示了查询在ADB实例上的执行顺序,每个色块表示了一条查询,色块左侧为查询的提交时间,色块右侧为查询的结束时间,色块的相对长度表示了某条查询的执行时间,色块的颜色没有特殊含义,只是为了区分不同的泳道。

通过甘特图,用户可以非常直观的看到当前时间范围内执行耗时较长的查询,并且可以直观的看到哪些查询是在并行的执行以及并行执行的时间段,这可以帮助用户判断出哪些查询是受到了某条Bad SQL的影响。色块的密集度则可以用来直观的判断ADB实例压力较大的时段是否和某些查询的并发度较高相关。
(二)查询列表
甘特图能够以直观的方式体现出查询之间的时间相关性,但是当用户选择的时间范围较大,甘特图中的色块会密集分布不容易分辨,而且甘特图上的指标较为有限,此时用户可以使用诊断工具中的查询列表功能。查询列表提供了多大10余项查询级别的重要指标,例如数据库名、用户名、客户端段IP、耗时、消耗内存以及扫描量等,这些信息和指标可以帮助用户进一步判断慢查询的来源和资源消耗等。
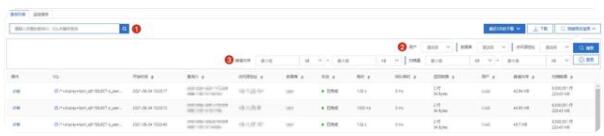
高级检索能力方面,诊断工具提供了三种类型的检索方法:
1.模糊检索和精确检索:用户可以根据SQL中的关键字进行模糊匹配,精确检索功能则帮助用户在确定查询ID的情况下,精确的检索到这条查询;
2.字符串类型的检索条件:检索工具会自动识别出用户所选时间范围内使用的数据名、用户名、客户端IP以及资源组等,提供下拉框的形式供用户选择,提高用户检索效率;
3.数值类型的检索条件:用户可以自由选择检索的指标单位,例如KB、MB、GB等,不需要进行手动的换算。
同时,用户在使用诊断工具时,往往有对慢查询的下载需求,下载后的慢查询可以在例如Excel等工具中进行更多自定义的慢查询治理和分析,所以我们也提供了查询列表的下载功能。
二、诊断慢查询
(一)查询在ADB中的执行流程
在介绍ADB执行流程前需要简单介绍一下三个相关的基本概念:
Stage
在执行阶段,ADB中的查询会首先根据是否产生Shuffle被切分为多个Stage来执行,一个Stage就是执行计划中某一部分的物理实体。Stage的数据来源可以是底层存储系统中的数据或者网络中传输的数据,一个Stage由分布在不同计算节点上相同类型的Task组成,多个Task会并行处理数据。
Task
Task是一个Stage在某个Executor节点上的执行实体,多个同类型的Task组成一个Stage,在集群内部并行处理数据。
Operator
Operator(算子)是ADB的最小数据处理单元。ADB会根据算子所表达的语义或算子间的依赖关系,决定使用并行还是串行执行来处理数据。
下面以一个典型的分局聚合查询为例来了解ADB中查询的执行流程,SQL语句如下:
- SELECT COUNT(*), SUM(salary)
- FROM emplayee
- WHERE age>30 ADN age<32
- GROUP BY sex
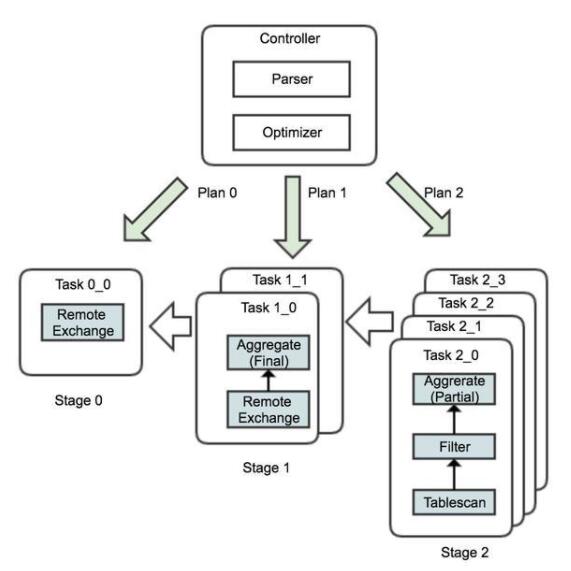
在ADB内部,首先由前端的Controller节点接收SQL语句请求,并对SQL语句进行语句解析和语法分析(Parser),最后使用优化器(Optimizer)生成最终的执行计划,整体执行计划会根据Stage的划分原则被切分为子计划,如图中的Plan0、Plan1和Plan2,分别被下发到对应的节点上。
其中子计划Plan2会并行的在4个计算节点上以Task实例的形式处理数据,首先执行数据的扫描和过滤,然后执行数据的局部聚合,处理完之后的数据会根据sex字段Repartition到下游的计算节点,即Stage1的节点,按照子计划Plan1的要求执行数据的最终聚合。最后,数据由Stage0的节点汇总并返回到客户端。
和典型的数据仓库一样,ADB的执行计划一般分为「逻辑执行计划」和「物理执行计划」:
逻辑执行计划:宏观层面了解查询的处理流程
逻辑执行计划在较高的层面展示查询的处理逻辑,基于规则的执行计划(RBO)会判断过滤条件是否可以下推,而基于代价的执行计划(CBO)会判断出多表关联时的顺序等。所以逻辑执行计划并不关注在物理执行时的具体处理方式,例如是否在执行时需要对多个算子进行融合以减少函数调用,或者自动生成代码的粒度,这些逻辑执行计划并不关注,这也就导致了逻辑执行计划往往只包含了Stage级别的执行统计信息。但是用户调优时往往是需要精确到算子级别的统计信息。
物理执行计划:微观层面了解每个算子的处理性能
相对于逻辑执行计划,物理执行计划包含了算子间的数据处理流图,也包含了算子的执行统计信息,可以精确的看到某个Join算子或者聚合算子占用的内存,也可以看到过滤算子过滤前后的数据量。但是并不是所有的算子用户都需要能正确理解其含义,特别是有些物理算子和用户的SQL语句找不到关联之处,这也会给用户单独使用物理执行计划定位问题带来较大的疑惑。
ADB的「SQL智能诊断」功能,提供给了用户一个逻辑执行计划和物理执行计划的融合视图,用户使用融合的执行计划即可以从宏观层面了解查询的处理流程,也可以从微观层面了解每个算子的处理性能,从而可以更加准确快速的帮助用户定位查询的性能瓶颈点。
(二)SQL自诊断功能
虽然我们提供了融合的和分层的执行计划来帮助用户分析查询的性能问题,但是我们发现在两类场景中用户使用融合执行计划会遇到困难:
ADB的初级使用者
ADB为了减少MySQL用户的学习和迁移成本,做到了绝大多数语法和MySQL兼容,但是ADB的后台并非MySQL内核,而是独立自研的一套分布式数据存储和分布式计算系统,面对ADB的执行计划,ADB的初级使用者往往不知道优化的重点在哪里,无从下手。
ADB中的复杂SQL
对于复杂的SQL,往往涉及几百张表的连接操作,Stage个数会达到几百个以上,算子个数更是会达到上千,执行计划图非常大,即使是ADB的高级使用者,面对这样复杂的执行计划,往往也无从下手,如下图是个196个Stage的执行计划图:

针对以上问题,我们在执行计划图中加入了SQL自诊断能力,SQL自诊断能力会将专家经验以规则的形式体现在执行计划中,对于ADB的初次接触者,即可以根据诊断结果确定查询执行过程中的性能瓶颈点,也可以根据诊断结果学习到ADB执行计划中需要关注的重点算子。针对复杂执行计划,SQL自诊断可以帮助用户快速定位到执行计划中需要调优的位置,并提供了调优的相关方法和文档,让用户在调优过程中更有针对性。
SQL自诊断能力通过「Query级别诊断结果」、「Stage级别诊断结果」、「算子级别诊断结果」这三层来展示诊断结果和优化建议。
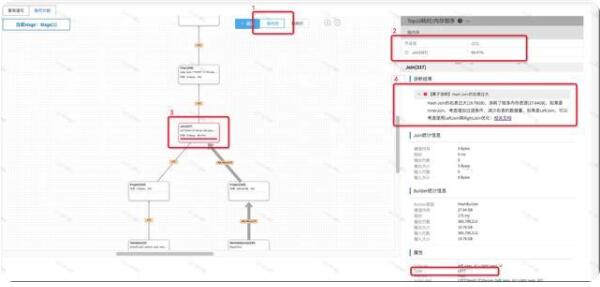
我们以一个线上的复杂SQL为例来介绍使用执行计划和SQL自诊断工具来进行性能问题定位的例子。首先我们通过慢查询检索工具搜索到一个内存消耗较大的查询,点击「诊断」打开该查询的诊断页面,切换到「执行计划」页签,我们会看到查询级别诊断结果已经判断出当前查询数据一个内存消耗较大的查询,如下图中的1所示:
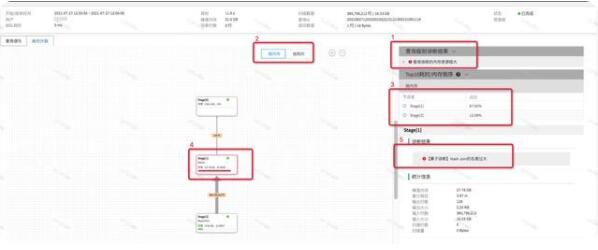
这时,我们需要定位内存效果较大的原因,我们点击按内存排序,可以看到在右侧,会根据Stage消耗的内存百分比进行了倒叙排序,可以非常明显的看出,Stage[1]占用的当前查询87%以上的内存比例,我们点击Stage[1],诊断工具会自动聚焦到执行计划树的Stage[1]的位置,点击Stage[1],我们可以看到Stage[1]的执行统计信息,同时,我们可以看到在5的位置,提示我们当前Stage1内部有个算子占用内存较大,但是并没有详细信息,所以接下来,我们需要进入到Stage[1]的内部,看看Stage[1]具体是哪个算子占用了较多内存。
点击「查看Stage执行计划」,进入到Stage[1]内部,首先,我们依然根据内存排序,可以看到,其中的Join[317]这个算子占用了整个Stage 99%以上的内存,点击该算子,算子执行计划树自动定位到当前算子,这时我们就可以看到算子诊断结果的详细信息了,信息提示我们,在构建Hash表用户Left Join时,占用了较大的内存,诊断结果还提供了官方的调优文档链接,根据文档中给出的调优方法,我们就可以减少该算子的内存占用。
以上的例子通过「查询级别诊断结果」和「算子级别诊断结果」进行SQL性能问题定位的方法,我们再来看一个「Stage级别诊断结果」的例子。
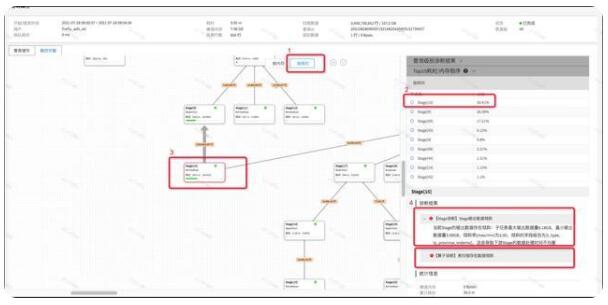
如下图所示,我们可以看到根据耗时排序后,Stage[10]的耗时比例最大,点击执行计划图中的Stage[10],可以在诊断结果栏看到两类诊断结果,一类是“Stage诊断”,一类是“算子诊断”,其中的Stage诊断告诉我们当前Stage的输出数据有倾斜,并且告诉我们倾斜的字段是哪些(数据倾斜是分布式系统中严重影响性能的问题,Stage输出数据倾斜不但会当时当前Stage处理数据在时间上存在长尾,而且会导致下游的数据处理存在长尾),同时可以看到有一个算子诊断结果,提示我们表扫描存在倾斜,那么我们可以初步判断当前Stage输出数据倾斜是因为扫描了一个数据倾斜的表导致的。接下来我们进入到Stage[0]内部进行定位和分析。
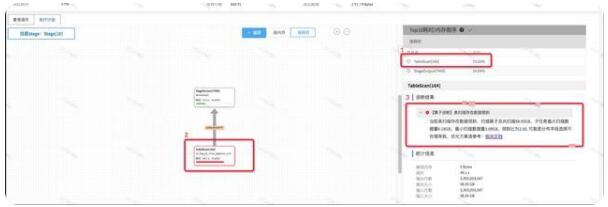
进入到Stage内存,我们根据耗时排序,可以看到TableScan算子耗时最大,这时我们点击TableScan算子,可以看到在诊断结果里,有关于该表数据倾斜的详细诊断结果信息,这张表由于数据分布字段选择的不合适,存在严重的数据倾斜问题,同时可以看到有相关的官方调优文档,我们根据调优文档,就可以调整为合适的分布字段,减少表数据倾斜对查询性能的影响。
通过以上的两个例子,我们可以看到,融合执行计划和SQL自诊断功能,可以快速的帮我们定位到查询的性能问题,并给出一定的调优建议,减少大量不必要的时间和精力的浪费,降低了初级使用者使用ADB的门槛。关于SQL自诊断更多的诊断结果可以参考官网文档:SQL自诊断,目前已经有20+诊断规则上线,涉及查询相关的内存消耗、耗时、数据倾斜、磁盘IO以及执行计划等多个方面,后续还有更多诊断规则陆续上线。
三、 后续规划
通过以上的阐述和例子分析,可以看到当前的诊断调优工具已经可以帮助用户进行多方面的SQL性能问题排查,但是我们在实际的线上问题处理和值班时仍然发现总结了多个用户在分析实例性能问题时的需求:
我应该调优哪些SQL?
用户在打开诊断调优页面时,面对实例上运行的上万甚至上千万条SQL,虽然可以通过耗时、内存消耗或者扫描量等进行排序来初步筛选出需要调优的SQL,但是其实其实用户欠缺了一个特定诊断结果的视角,例如:
哪些SQL是数据扫描倾斜的?
哪些SQL是索引过滤不高效的?
哪些SQL是Stage输出倾斜的?
哪些SQL是分区选择不合理的?
用户在针对某一个SQL的特定诊断结果调优完成后,其实需要知道有哪些类似的SQL都需要调优的,所以我们后续会提供给用户一个从特定诊断结果维度进行分析的工具,一次性地解决某个特定问题。
我的SQL有问题,和建表方式不优有关吗?
ADB后台是一个分布式的数据存储和分布式的执行框架,依赖数据均匀的分布到各个后台节点上,同时ADB针对不同的业务场景设计了不同的表类型,例如分区表、复制表,有些表字段在存储时进行聚集存储,也会提升查询性能,但是用户往往不知道建表方式不优到底影响了哪些查询。后续我们会把「数据建模诊断结果」和「查询诊断结果」关联,用户通过数据建模的诊断结果即可快速知道不良的表结构影响了哪些SQL,同时反过来也可以通过某条SQL的诊断结果知道哪些表需要优化。两类诊断结果联动调优,可以从根源上解决实例的查询性能问题。