












在分布式数据库系统领域, 多主(多写入点, Leader-less)是一个非常诱人的特性, 因为客户端可以随机请求任何一个节点. 这种可随机选择访问点(写入点)的特性, 使得系统的高可用唾手可得, 因为当客户端发现某个节点出故障时, 更换另一个节点重试就可以了, 只要系统没有完全宕机, 几次重试之后一定成功, 也就可以达到百分之百高可用。
传统的 Basic Paxos 常常被误认为是 Leader-less 的, 也即多主, 但 Basic Paxos 只能用于确定一个实例的共识, 真正落地还需要结合日志复制状态机, 如果复制组(多节点)不指定 Leader 的话, 那么就会出现争取同一个位置的日志的情况, 也就是在尝试达成这个位置的日志的共识时出现活锁. 这种多节点争取同一个位置的情况, 在实践上将导致系统不可用, 因为, 通常自称采用 Paxos 的多副本数据库系统, 依然要显式指定 Leader, 并不是真正 Leader-less 的.
借鉴 vector 时钟和多复制组的思路(如 Multi Raft Group), 是可以避免多主冲突的, 因为, 不同的节点作为各自组的 Leader, 分别写入不同的日志序列, 也就完全没有争取同一个位置的日志而导致冲突了.
以一个3节点的集群来举例, 通过预先配置强制指定各为其主, 结构为:
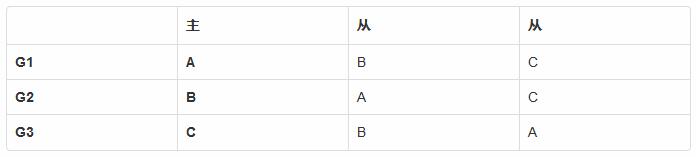
有复制组 G1, 成员节点是 {A, B, C} , 其中节点 A 是主. 类似的, 复制组 G2 和 G3 的主是 B, C. 当客户端请求不同节点时, 将日志写入不同复制组的日志序列, 因此不会产生冲突.
某一时刻, 所有节点的状态是:
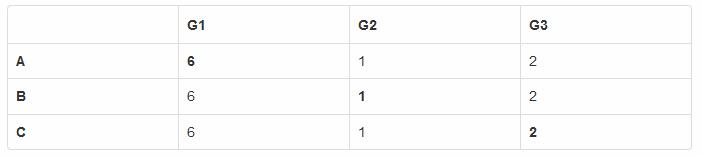
这个状态表明, 复制组 G1 累计有 6 条日志, 复制组 G2 是 1 条, 复制组 G3 是 2 条.
到目前为此, 似乎一切顺利, 写入没有冲突, 还能通过复制组形成多副本. 但是, 现实不是这样的, 一个只能写入的数据库几乎没有任何用处, 数据库必须支持读取, 所以, 日志复制状态机架构必须有状态机, 也即这 3 条日志序列必须在所有节点 Apply 到各节点的状态机实例中.
最简单的方法是在各个节点上把 3 条日志序列合并成(Merge)一条日志序列, 通过某种算法保证所有节点上的合并结果一定是相同的, 例如按时间戳排序, 这样才能保证状态机一致(相同).
但是, 节点不能只依赖自己本地的 3 条日志序列合并, 在每一次合并时, 它需要获取其它复制组的最新信息, 判断自己本地的日志序列是不是足够新. 自己作为 Leader 的那一条序列, 当然自己能确定, 但其它两条不能, 需要询问其它节点, 不能定死询问 Leader, 因为需要容忍某个复制组的 Leader 宕机的情况.
所以, 针对其它复制组, 采取 Read Index 逻辑, 可以判断是否最新. 并且在其它组 Leader 宕机的情况下, 将对应的日志序列从其它 Follower 那里补齐.
日志序列中可能包含非幂等的指令, 通过加入时间戳之后, 非幂等的指令可以变成幂等的.(需要文章论证). 以一个 key 为例, 状态机中的 key-value 带有初始化时间戳和最新更新时间戳 {reset_time, modify_time} . 当收到一条 incr 指令时, 指令中带有时间戳, 与 key-value 中的 meta 信息比对之后, 就能知道 Apply 算法.
- if key.reset_time < op.time {
- value += 1
- } else {
- // 忽略在初始化之前的指令
- }
例如, 在 A 节点上针对 key 执行了 set 操作, 便会复位其 reset_time, 之后, 再收到其它节点的更早的 incr 指令时, 这个 incr 指令就不能修改状态机了, 因为这个指令发生在复位之前.
各个节点的系统时钟不同步没关系, 因为一致性与系统时钟没有必然联系(需要文章论证). 只要确保所有节点最终的结果是一致的(相同)的就行. 不要让 A 节点先执行 set 再执行 incr, 而 B 节点先执行 incr 再执行 set 这种情况出现. 在这个例子中, 从上帝视角知道 incr 在 set 之前, 所以, A 节点先执行 set, 然后遇到 incr 指令时会忽略.
上面的时间戳比较要求不同的节点产生的时间戳不能相同, 可以把节点ID当作时间戳的最低位, 避免两个时间戳相同.
对于 incr 操作, 初始化比较简单, 但是, 对于 pop 这种非幂等性的操作, 并不是初始化, 很难解决. 本质上, 是一种回滚操作, 能实现, 但成本太大, 要讨论起来真是够多的.
不同的节点收到不是自己负责的日志序列的延迟不一定, 但是, 我们又不能等确保全部日志序列都收到之后再 Apply, 虽然等全部日志序列都到齐之后再 Apply 可以不需要回滚操作, 但等待行为不能容忍宕机(CAP 理论).
总结起来, 就是 没有银弹 . vector 时钟看起来很美好, 但日志序列之间的相互依赖问题, 要么通过停止等待来解决, 要么通过回滚操作来解决, 否则无法保证多副本一致(相同). 但是, 某些操作的回滚成本太大.
注: 有一种技术叫 CRDT, 思想类似, 但是上面讨论的问题依然存在.
考虑过这个问题:
- C 宕机, 但是它上面有一条日志还没有复制到其它节点.
- A 和 B 各自合并日志序列之后 Apply 了, 两者的状态机一致, 没问题.
这时, C 恢复, 那条日志得以复制出去, 这时, A 和 B 需要回滚, 然后重新合并, 再 Apply.
如果 C 在恢复之后, 给那条日志赋予新的时间戳, 那么也会有一种场景(C 宕机前日志已经复制出去了, 但它还没知道结果), 同样需要回滚, 因为别的节点可能已经 Apply 过那条日志了.













