












一 背景
订单系统存在于各行各业,如电商订单、银行流水、运营商话费账单等,是一个非常广泛、通用的系统。对于这类系统,在过去十几年发展中已经形成了经典的做法。但是随着互联网的发展,以及各企业对数据的重视,需要存储和持久化的订单量越来越大,数据的重视程度与数据规模的膨胀带来了新的挑战。首先,订单量对于数据的存储、持久化、访问带来了挑战,这不仅增加了开发面对的困难,也为系统的运维带来了挑战。其次,随着大数据技术的发展以及运营水平的不断提高,订单数据的后续数据分析工作,如流批处理、ETL,也越来越重要,这也对数据的存储系统提出了更高的要求。
本文提出了一种基于MySQL + Tablestore 的大规模订单系统设计方案。这种方案基于分层存储的思想,使用 Tablestore 辅助 MySQL 共同完成订单系统支持。在系统中,利用 MySQL 的事务能力来处理对事务强需求的写操作与部分读操作;利用 Tablestore 的检索能力、大数据存储能力等弥补 MySQL 在功能上的短板。详细可见文章:云上应用系统数据存储架构演进。
本文作为 MySQL + Tablestore 分层存储架构的大规模订单系统的架构篇。
首先详细阐述,在大规模订单系统中,存在哪些需求,存在哪些痛点。
进而比较传统的架构,其现状如何,各存在什么样的劣势,无法满足哪些需求。
然后讲述 MySQL + Tablestore 架构,阐述这种架构是如何满足大规模订单系统的需求的。
二 需求场景
订单系统,面向 C 端,除了在系统性能要求高外,对于数据的存储、后续数据的计算、数据实时处理、数据批处理都有一定的要求。而对于 C 端客户、产品运营、系统运维等不同的角色,他们对系统的需求也有所不同。
1 C 端需求
对于 C 端客户以及面向 C 端的开发而言,系统首先需要支持高并发、高稳定性。其次,系统需要能够支持基于用户 id 的搜索以及搜索用户 id 下包含特定关键词的记录。具体的需求有:
基于用户 id 查找用户近一月的订单。
基于订单号查询订单详情。
搜索用户购买过的包含某关键字的商品。
这对于系统的索引能力以及搜索能力有较高的要求。
2 运营需求
运营同学需要能够在不影响线上的情况下使用 SQL 对实时数据进行分析,能够根据非主键字段进行检索;他们还需要系统对流批计算的支持,需要流式数据处理来进行实时数据统计,需要批处理来进行历史数据统计。运营同学常见的需求场景有:
- 统计在某旗舰店消费过的用户有哪些。
- 统计消费过某一件产品的客户有哪些并且他们还购买了什么产品,进而向客户推荐商品。
- 实时统计双十一开始后的实时成交额,用于宣传时的实时数据展示。
- 统计某店铺过去 10 年的成交额。
- 依赖订单数据对客户做实时更新的画像分析,以支持商品的推荐。
3 运维需求
运维同学更关注系统的稳定性、复杂度并期待低运维成本。而基于 MySQL + Tablestore 的订单系统可以将运维同学从繁琐的运维工作中解放出来,大大降低运维成本。它能够做到:
系统高可用,并发能力强。
系统复杂度低,不需要维护多个集群,也不需要关注各集群间的数据同步过程,运维工作简单易上手。
三 传统订单系统
1 订单系统架构演进
最简单的订单系统就是单点的 MySQL 架构,但随着订单规模的增长,用户采用分库分表的 MySQL 替代单点 MySQL 方案。但这种方案下,当数据量达到当前 MySQL 集群瓶颈,集群扩容仍然会相当具有难度,需要更大的集群以及大量数据的迁移工作。数据迭代、膨胀带来的困扰,是分库分表 MySQL 方案难于逾越的。
NoSQL 被引入,MySQL + HBase 的方案应运而生。这种方案将实时数据和历史数据分层存储,MySQL 中只存储实时数据,历史数据归档进入 HBase 存储。这种方案解决了数据扩容带来的存储和运维难题,但它的缺点在于,存储于HBase的数据很难被合理利用,并且方案整体也不支持检索功能。
因此,架构中引入了 Elasticsearch,形成了 MySQL + HBase + Elasticsearch 的方案。这种方案利用了 Elasticsearch 提供的数据检索能力,解决了订单数据的搜索问题。但在这种架构下,用户要维护 HBase、Elasticsearch 两个集群,还需要关注向HBase、Elasticsearch 同步数据的任务,维护成本很高。并且这种架构仍无法支持流批处理、ETL等数据分析、加工工作。
MySQL 分库分表方案
MySQL 自身拥有强大的数据查询、分析功能,基于 MySQL 创建订单系统,可以应对订单数据多维查询、统计场景。伴随着订单数据量的增加,用户会采取分库、分表方案应对,通过这种伪分布式方案,解决数据膨胀带来的问题。但数据一旦达到瓶颈,便需要重新创建更大规模的分库 + 数据的全量迁移,麻烦就会不断出现。数据迭代、膨胀带来的困扰,是MySQL 方案难于逾越的。仅仅依靠 MySQL 的传统订单方案短板凸显。
1、数据纵向(数据规模)膨胀:采用分库分表方案,MySQL 在部署时需要预估分库规模,数据量一旦达到上限后,重新部署并做数据全量迁移;
2、数据横向(字段维度)膨胀:schema 需预定义,迭代新增新字段变更复杂。而维度到达一定量后影响数据库性能;数据膨胀还会提高系统运维难度和成本。且 MySQL 集群一般采用双倍策略扩容,在重储存低计算的订单场景下,CPU的浪费情况也会比较严重。
MySQL + HBase 方案
引入双数据的方案应运而生,通过实时数据、历史数据分存的方案,可以一定程度解决数据量膨胀问题。该方案将数据归类成两部分存储:实时数据、历史数据。同时通过数据同步服务,将过期数据同步至历史数据。
1、实时订单数据(例如:近 3 个月的订单):将实时订单存入 MySQL 数据库。实时订单的总量膨胀的速度得到了限制,同时保证了实时数据的多维查询、分析能力;
2、历史订单数据(例如:3 个月以前的订单):将历史订单数据存入 HBase,借助于 HBase 这一分布式 NoSQL 数据库,有效应对了订单数据膨胀困扰。也保证了历史订单数据的持久化;
但是,该方案牺牲了历史订单数据对用户、商家、平台的使用价值,假设了历史数据的需求频率极低。但是一旦有需求,便需要全表扫描,查询速度慢、IO 成本很高。而维护数据同步又带来了数据一致性、同步运维成本飙升等难题;
MySQL + HBase + Elasticsearch 方案
MySQL + HBase + Elasticsearch 方案通过引入 Elasticsearch 集群,解决了其他方案无法应对的数据检索问题。
1、实时订单数据(例如:近 3 个月的订单):将实时订单存入 MySQL 数据库。实时订单的总量膨胀的速度得到了限制,同时保证了实时数据的多维查询、分析能力;
2、历史订单数据(例如:3 个月以前的订单):将历史订单数据存入 HBase,借助于 HBase 这一分布式 NoSQL 数据库,有效应对了订单数据膨胀困扰。也保证了历史订单数据的持久化;
3、数据检索:数据同步任务将需要检索的字段从 HBase 同步至 Elasticsearch,借助于 Elasticsearch 的索引能力,为系统提供数据检索能力。然后必要时反查 MySQL 获取订单完整信息;
该方案虽然解决了数据膨胀带来的扩容问题,也能够支持数据检索。但可以看到的是,客户要维护至少两套集群,关注两处数据同步任务,该方案的系统复杂度很高,运维成本也会很高。此外,这个方案依然不能对数据的流批处理、数据 ETL 再加工提供支持。
2 传统订单架构总结
总之,MySQL 分库分表方案无法解决数据膨胀带来的扩容问题。基于 MySQL + HBase 的架构在数据检索上面存在明显短板。而 MySQL + HBase + Elasticsearch 的方案,虽然能够解决扩容和数据检索问题,但其系统复杂,维护成本高;另外,这种方案无法对数据分析工作、数据再加工 ETL 工作提供有效支持。而 MySQL + Tablestore 不仅解决了扩容问题、检索问题,还支持数据流批处理以及 ETL 再加工工作,且系统复杂度低,运维成本低,能够满足大规模订单系统的各项需求。
四 MySQL + Tablestore 方案
表格存储(Tablestore)是阿里云自研的多模型结构化数据存储,提供海量结构化数据存储以及快速的查询和分析服务。
MySQL + Tablestore 后,可以很好的满足大规模订单场景下遇到的各种需求。其整体架构图如图。
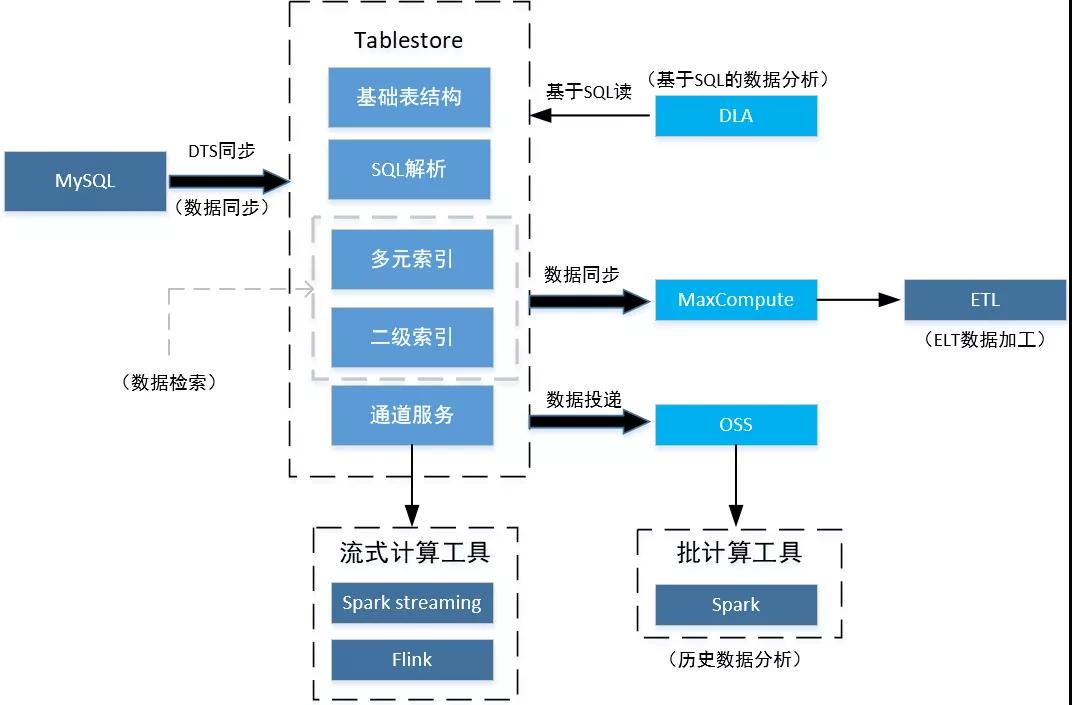
MySQL 处理订单的写入和近期数据的基本读取,并且利用数据同步工具如 DTS 将数据实时同步给 Tablestore。在 Tablestore 中,利用其二级索引和多元索引,可以处理检索需求。通过 DLA,可以实现使用 SQL 直接查询 Tablestore。Tablestore 的通道服务可以对接 Spark streaming 以及 Flink,可以实现实时数据分析。将 Tablestore 和 ODPS 对接,可以很便捷的实现对订单数据的 ETL 作业。而结合 OSS 和 Tablestore,可以实现订单数据的归档,并且可以在 OSS 中实现全量历史数据的分析工作。
1 数据同步
传统的订单架构中,开发者不可避免需要处理数据同步进入 HBase 或者 Elasticsearch 之类的工作。这不仅加重了开发者的开发工作,也提高了运维难度。在 Tablestore 中,阿里云提供 DataX、Data Transmission Service(DTS)、Canal 多种数据同步工具完成数据从 MySQL 到 Tablestore 的同步工作。用户只需要进行少量的开发和配置工作就可以完成数据实时同步。操作方便简单,实时性高,大大降低了维护成本。
2 数据检索
Tablestore 提供了二级索引和多元索引来支持数据的检索。二级索引可以完成基于主键列和预定义列的数据查询,例如查询用户过去一个月成交的订单情况。而多元索引,基于倒排索引和列式存储,对外提供了更加强大的数据检索功能,他解决大数据的复杂查询难题。它可以实现如搜索购买过某产品的用户这样的需求。
Tablestore 的多元索引补齐了 MySQL、HBase 等在搜索上面的短板。而相对于 Elasticsearch,多元索引不再需要使用者专门维护集群、维护数据同步任务,成本更低。
3 基于SQL的数据分析
Tablestore 以多种方式支持 SQL 对 Tablestore 中数据的读写。若想直接读取 Tablestore 中的数据,建议直接使用 Tablestore 的 SQL 支持能力进行操作;而若希望进行多数据存储的联邦查询,推荐使用 DLA 所支持的 SQL。对于两种形式的SQL,Tablestore 都利用多元索引对其进行了充分的优化。拥有 SQL 处理能力,开发者可以更加高效率的进行代码开发、代码迁移工作。直接使用 SQL 查询 Tablestore 也会为 MySQL 主库卸载流量。
4 实时数据分析
Tablestore 的通道服务,可以将 Tablestore 库中数据的变化传入通道。使用 Spark streaming或者 Flink 等流式数据处理工具对接通道,可以实现例如统计实时成交额这一类的实时数据分析需求。
5 历史数据分析
Tablestore 可以将数据投递到 OSS 系统,这样可以完成订单的归档需求,并且利用 OSS 系统对接 Spark ,可以完成对全量历史数据的分析工作。这样,在 Tablestore 中存储近期数据,在 OSS 中存储全量历史数据,以 OSS 来支持涉及全量历史数据的分析工作。
6 ETL数据再加工
通过将 Tablestore 数据接入 ODPS ,可以利用 ODPS 强大的数据处理能力,更便捷的对数据做 ETL 作业,进行数据的再次加工。
五 总结
本文简要介绍了基于 MySQL 结合 Tablestore 的大规模订单系统方案。这种方案支持大数据存储、高性能数据检索、SQL搜索、实时与全量数据分析,且部署简单、运维成本低。

















