













在做软件开发的时候,总会有一些奇奇怪怪的问题难以解答:
- 栈是向上增长还是向下增长?(这其实是个不严谨的问题)
- arm 是 little endian 还是 big endian?
- 闭包究竟是一个什么样的数据结构?它占用多少内存?
- ...
这些让人摸不着头脑的问题,只要你耐心查找,在 stackoverflow 或者各种论坛上,一般能够找到答案。不过,别人给出来的答案很可能是模棱两可的,不好理解的,甚至是错误的。我们需要花时间甄别那些正确的、并且精准的答案,还需要花时间阅读这些答案。有时候,即便是你得到了答案甚至记住了答案,你可能还是没有完全理解别人给出的答案。当你需要把这样的答案讲给别人时,你会发现自己似乎无法讲得清楚。
在我的职业生涯中,遇见过很多所谓的「高手」,漫长的职业生涯让他们遇见了各种奇葩的问题,通过各种知识搜索和整理的手段,他们也记住了这些问题的答案。他们经常能抛出一些冷门的知识,知识储备之丰富让我叹为观止。但当我想深入下去时,就发现他们对事物的理解不过是一个指向别处的引用(reference),是借来(borrow)的知识,自己没有知识的所有权(ownership),所以往往容易语焉不详,只能给出浅层的回答。
那么,如何避免这种情况,让自己成为知识的所有者呢?
我们要学会不依赖别人的断言,单单通过代码本身来探索问题的答案。作为开发者,我们最大的优势就是我们研究的对象,计算机和计算机软件,就放在离我们唾手可得的地方。我们只要想办法用代码构造研究这个问题的实验,就能不断迭代够逐渐找到答案。而且,这答案是第一手的,不是别人咀嚼后喂给你的,而是你通过实验验证出来的,所以它是你自己的知识,即便过了十年二十年,你依然能清晰地给出答案,或者至少给出通往这个答案的途径。
问有意思的问题
最近在我的极客时间的专栏《陈天 · Rust 第一课》中,有个同学在看到我画的这张图时:
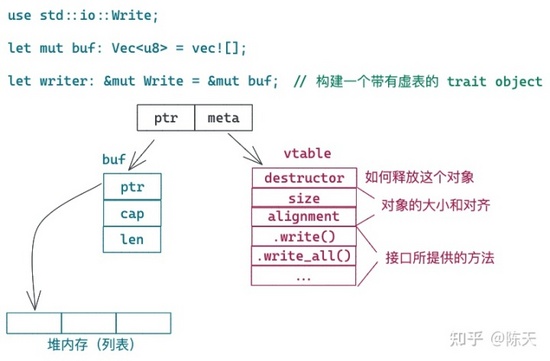
问了这样一个问题:
虚表是每个类有一份,还是每个对象有一份,还是每个胖指针有一份?
这是一个非常棒的问题。我不知道有多少人在学习的时候会发出这样的疑问,但我猜很少,因为至少我之前在直播讲 Rust 时,在我公司内部讲 Rust 时,没有人关心过这个问题。
而 问对问题,比知道答案更重要 。一个好的问题,就已经离知识很近了。
<爱因斯坦>
如何才能问出有意思的问题?
我在学习 trait object 的时候,也问过同样的问题,并且顺着问题,找到了答案。你想想,什么样的思考会触发问这个问题呢?
也许来自对比学习(我自己的情况):因为 C++ 每个类有一个自己的虚表,所以不免会好奇 trait object 是不是也是类似的实现?
也许来自对内存效率的担忧:trait object 有个指针指向虚表,那么如果在每个 trait object 生成时都生成一张虚表,那么很浪费内存啊。对于上面的 Write trait,还好,只有几个方法,但对一些比较大的 trait,如 Iterator,有近七十个方法,也就是说光这些方法组成的虚表,就有五百多字节!如果每个 trait object 都自己生成这样一张表,内存占用多可怕!所以如果不搞明白,不敢大量使用啊。
也许还有其它什么思考触发了这个问题。
不管怎么样,能问出好的问题,一定会现有一些先验知识,然后通过细致的观察,深入的思考,才会慢慢萌发问题。
从假设到通过实验验证假设
那么,有了好问题,我们如何解答这个问题呢?
我们可以根据自己已有的知识,思考最可能接近真相的方向,然后动手做实验来验证自己的假设。对于这个问题,我认为为每个 trait object 生成一张表效率太低,不太可能,所以倾向于像 C++ 那样,每个类型都有静态的虚表。既然我有了这样的假设,那么怎么验证它呢?我可以用两个字符串分别生成 trait object,然后打印虚表的地址进行对比。如果一致,那么符合我的假设:每个类型都有静态的虚表。
实验一
有了这个方向,查阅资料,写出下面的第一个实验的代码并非难事:
- use std::fmt::Debug;
- use std::mem::transmute;
- fn main() {
- let s1 = String::from("hello");
- let s2 = String::from("goodbye");
- let w1: &dyn Debug = &s1;
- let w2: &dyn Debug = &s2;
- // 强行把 triat object 转换成两个地址 (usize, usize)
- // 这是不安全的,所以是 unsafe
- let (addr1, vtable1) = unsafe { transmute::<_, (usize, usize)>(w1 as *const dyn Debug) };
- let (addr2, vtable2) = unsafe { transmute::<_, (usize, usize)>(w2 as *const dyn Debug) };
- // trait object(s / Display) 的 ptr 地址和 vtable 地址
- println!("addr1: 0x{:x}, vtable1: 0x{:x}", addr1, vtable1);
- // trait object(s / Debug) 的 ptr 地址和 vtable 地址
- println!("addr2: 0x{:x}, vtable2: 0x{:x}", addr2, vtable2);
- // String 类型拥有相同的 vtable?
- assert_eq!(vtable1, vtable2);
- }
如果你在 rust playground 里运行,会得到下面的结果:
addr1: 0x7ffd1c524910, vtable1: 0x556591eae4c8
addr2: 0x7ffd1c524928, vtable2: 0x556591eae4c8
从实验一中,我们得出结论: 虚表是共享的,不是每一个 trait object 都有一张虚表 。从虚表的地址上看,它既不是堆地址,也不是栈地址。目测像是代码段或者数据段的地址?
你看,我们通过观测实验结果,又有了新的发现,同时有了新的问题。
于是我们继续迭代。
实验二
在实验一的基础上,我们可以定义一个静态变量 V,打印一下它的地址(DATA 段),以及打印一下 main() 函数的地址(TEXT 段)来比较:
- static V: i32 = 0;
- println!("V: {:p}, main(): {:p}", &V, main as *const ());
打印结果(注意每次编译后运行地址都会不同):
- addr1: 0x7fff2dd3e7f8, vtable1: 0x557a21b9e488
- addr2: 0x7fff2dd3e810, vtable2: 0x557a21b9e488
- V: 0x557a21b910ec, main(): 0x557a21b63e40
Bingo!实验二证明了我们的猜测没错, 虚表是编译时就生成好,塞入二进制文件中的 。当生成 trait object 时,根据是哪个类型,再指向对应的位置。
那么,Rust 为每个类型(比如 String )编译时只生成一个 vtable,对么?
我们目前很接近真相,但还有未解的疑问。从目前的实验中,我们还无法得出这个结论。实验一里,我们只用了 Debug trait,这个样本太小,不具备普遍性。如果对同一个数据类型(比如 String)使用不同的 trait,会导致不同的结果么?我们并不知道。如果结果相同,那么我们就大概率可以确定,一个类型一张虚表,否则,就应该是每个类型的每个 trait 实现,都有一张虚表。
实验三
于是在实验三里,我们用同一个类型的两个不同的 Trait,来生成不同的 trait object,看看其虚表是否是同一个地址:
- use std::fmt::{Debug, Display};
- use std::mem::transmute;
- fn main() {
- let s1 = String::from("hello world!");
- let s2 = String::from("goodbye world!");
- // Display / Debug trait object for s
- let w1: &dyn Display = &s1;
- let w2: &dyn Debug = &s1;
- // Display / Debug trait object for s1
- let w3: &dyn Display = &s2;
- let w4: &dyn Debug = &s2;
- // 强行把 triat object 转换成两个地址 (usize, usize)
- // 这是不安全的,所以是 unsafe
- let (addr1, vtable1) = unsafe { transmute::<_, (usize, usize)>(w1 as *const dyn Display) };
- let (addr2, vtable2) = unsafe { transmute::<_, (usize, usize)>(w2 as *const dyn Debug) };
- let (addr3, vtable3) = unsafe { transmute::<_, (usize, usize)>(w3 as *const dyn Display) };
- let (addr4, vtable4) = unsafe { transmute::<_, (usize, usize)>(w4 as *const dyn Debug) };
- // s 和 s1 在栈上的地址,以及 main 在 TEXT 段的地址
- println!(
- "s1: {:p}, s2: {:p}, main(): {:p}",
- &s1, &s2, main as *const ()
- );
- // trait object(s / Display) 的 ptr 地址和 vtable 地址
- println!("addr1: 0x{:x}, vtable1: 0x{:x}", addr1, vtable1);
- // trait object(s / Debug) 的 ptr 地址和 vtable 地址
- println!("addr2: 0x{:x}, vtable2: 0x{:x}", addr2, vtable2);
- // trait object(s1 / Display) 的 ptr 地址和 vtable 地址
- println!("addr3: 0x{:x}, vtable3: 0x{:x}", addr3, vtable3);
- // trait object(s1 / Display) 的 ptr 地址和 vtable 地址
- println!("addr4: 0x{:x}, vtable4: 0x{:x}", addr4, vtable4);
- // 指向同一个数据的 trait object 其 ptr 地址相同
- assert_eq!(addr1, addr2);
- assert_eq!(addr3, addr4);
- // 指向同一种类型的同一个 trait 的 vtable 地址相同
- // 这里都是 String + Display
- assert_eq!(vtable1, vtable3);
- // 这里都是 String + Debug
- assert_eq!(vtable2, vtable4);
- }
结果令人惊喜:String + Display 生成的 trait object,和 String + Debug 生成的 trait object,使用的是不同的 vtable:
- s1: 0x7ffc7d427a08, s2: 0x7ffc7d427a20, main(): 0x561b76ff2e90
- addr1: 0x7ffc7d427a08, vtable1: 0x561b7702d3b8
- addr2: 0x7ffc7d427a08, vtable2: 0x561b7702d3d8
- addr3: 0x7ffc7d427a20, vtable3: 0x561b7702d3b8
- addr4: 0x7ffc7d427a20, vtable4: 0x561b7702d3d8
所以,我们可以确定, 虚表是每个 (Trait, Type) 一份,在编译时就生成好了 。
那么,编译器在什么时机来生成这张虚表呢?有理由推断,在编译器编译 impl 某个 trait 的代码时生成了虚表,比如:
- impl Debug for String {...}
因为此时编译器有生成虚表所需要的一切信息:
- 数据如何销毁:String 的 drop 方法的地址此时需要已经编译得出
- 数据的大小和对齐:此刻是 String 类型,所以大小 24 字节,对齐 8 字节
- trait 方法:在编译 impl Debug 时就已经得到 fmt() 方法的地址
如果我是编译器的开发者,此时不做,更待何时?所以我们可以做出这个推断。这个推断逻辑自洽,看上去非常合理,大概率是对的。不过要验证起来不那么容易,除非我们继续在 Rust 编译器源码中做实验。
从实验结果中最终得出结论
好,综合上述三个实验,我们的脑海中,已经可以构筑出这样一幅图:
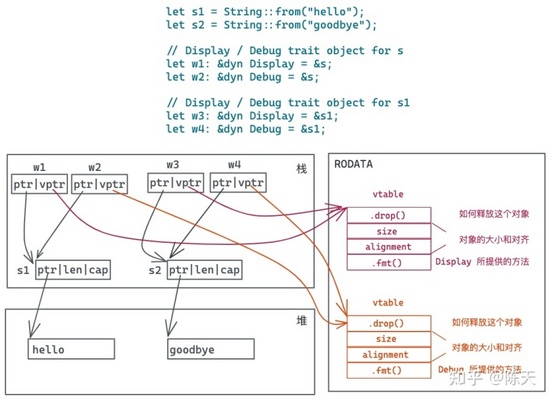
此刻,我们就完美地找到了一开始的问题我们想要的答案。对于开头的问题,我是这么回答的:
好问题。这个在讲 trait 的那一课有讲到。虚表在每个 impl TraitA for TypeB {} 实现时就会编译出一份。比如 String 的 Debug 实现, String 的 Display 实现各有一份虚表,它们在编译时就生成并放在了二进制文件中(大概是 RODATA 段中)。 所以虚表是每个 (Trait, Type) 一份。并且在编译时就生成好了。 如果你感兴趣,可以在 playground 里运行这段代码(这是后面讲 trait 时使用的代码): https://play.rust-lang.org/?version=stable&mode=debug&edition=2018&gist=89311eb50772982723a39b23874b20d6 。限于篇幅,代码就不贴了。
因为我自己通过做实验,找到了答案,所以,我对自己的结论和推断都很有信心。同时,因为这是我自己探索出来的知识,我并非借用别人脑海中的想法,而是对它拥有所有权,所以,我可以自如地从各个角度来构筑我的答案。
小结
在韦氏词典中,是这么定义科学方法的:科学方法是一种有系统地寻求知识的程序,涉及了以下三个步骤:问题的认知与表述、实验数据的收集、假说的构成与测试。我们在探索 Rust 的 vtable 是如何构建的过程中,使用了科学方法。它是一个不断迭代的过程,从观测开始,一路经历问问题,做出假设,构建实验来验证假设,观察实验结果,提出新的问题,进一步迭代下去,直到我们形成了一个自洽的理论:
本文我们通过一个 Rust 的例子来探讨这个方法。当这个方法本身跟 Rust 无关。我们在学习编程语言,使用第三方库,构建复杂的系统,都可以用这个方法。如果你能够掌握和使用这个方法,那么,慢慢地你就能成为知识的所有者。

















