












本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
GitHub的AI代码生成插件Copilot发布才两个多月,就闯下不少大祸。
照搬过开源代码,还有生成的内容包含用户隐私和歧视性语言等。
GitHub的对策也够粗暴——拉清单。
觉得不合适的词统统列入敏感词,现在连Boy和Girl都不能用了。
大神的平方根倒数速算法连代码带注释里的“what the f**k?”就被Copilot原样照搬。
这事被曝光后,Github悄悄把能召唤出这段经典代码的“q rsqrt”提示词加入了黑名单,顺便把f**k相关的词也给加进去了。
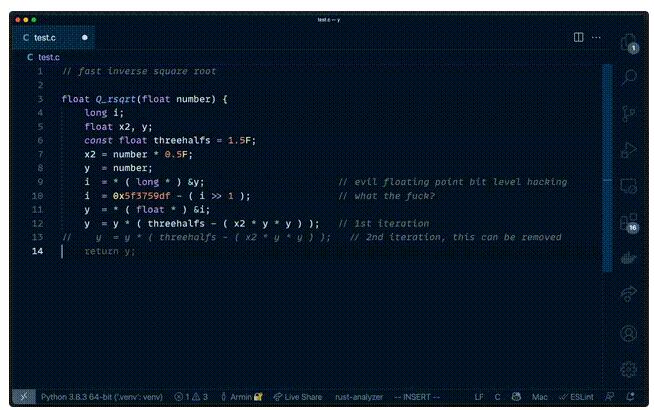
△ Copilot照搬大神代码作案现场
发现这事的是纽约大学的副教授Brendan Dolan-Gavitt,他最近一项研究就是找出Copilot加密敏感词列表中的上千个词。

翻过他的履历后才发现,这位破解大师还因为找敏感词这事在IEEE上发过论文。
以色列和性别词汇都不让用
Brendan发现Copilot敏感词列表就在VS Code的插件包里,只不过是加密的。
加密后的敏感词是32位Hash值,逆运算解密不太可能。
不过这位大哥在敏感词领域颇有经验,直接用以前搜集到的常见敏感词挨个碰撞。
常见的都尝试过以后,剩下的就暴力穷举。
穷举法最大的难点在于同一个Hash值可能对应许多词,他举例“-1223469448”就对应80万个11位字母数字的组合。
于是Brendon搞了个GPT-2模型用来判断哪种组合最像英语。

就这样遇到困难解决苦难,破解方法从最开始的简单穷举,最后都用上了GPU加速和Z3解约束算法(Constraint Solver)
最终现存的1170个敏感词他找出了1168个,只剩最后两个算出来的结果实在没有长得像人话的,只好放弃了。
通过对Copilot插件每一个版本分析,他还能跟踪具体哪个敏感词是在哪次更新中添加的。
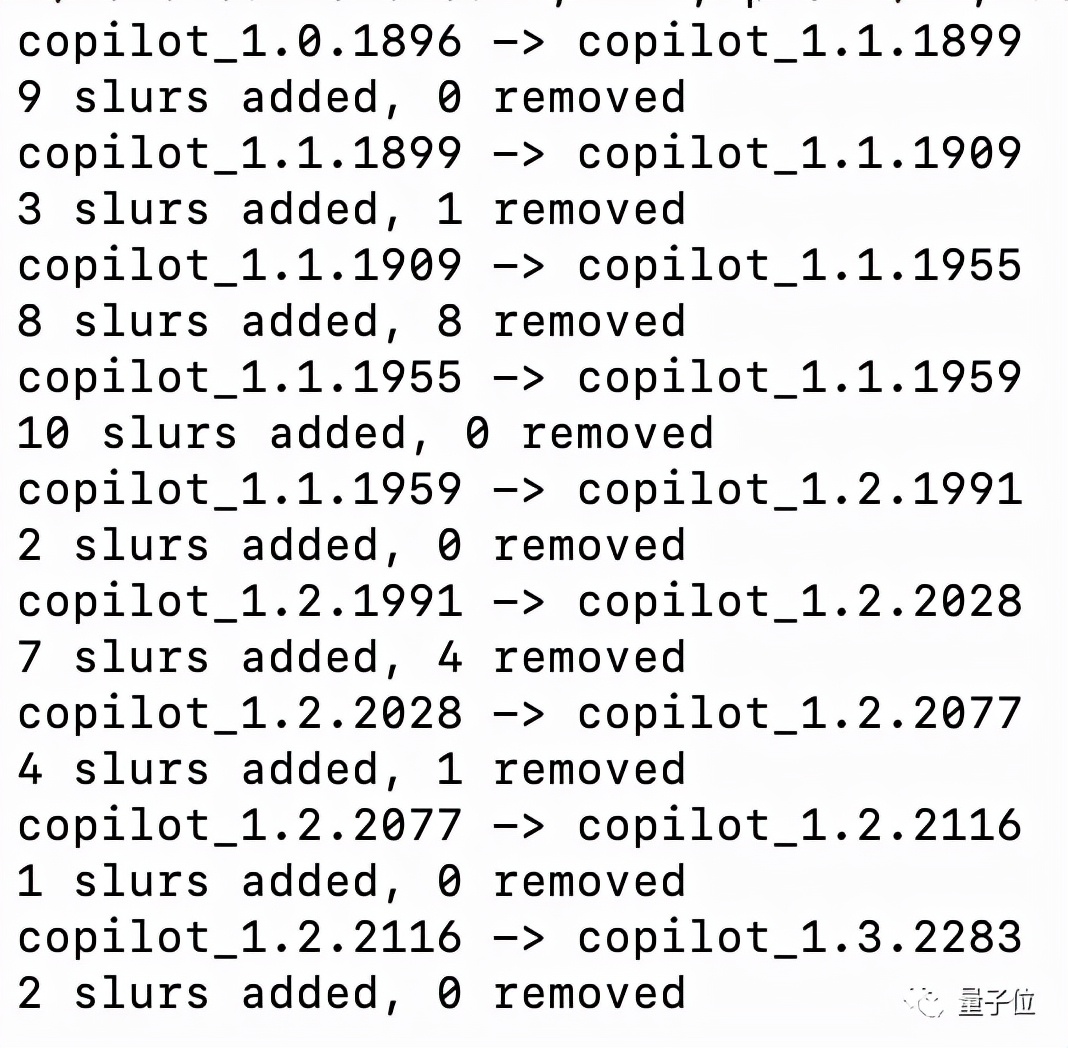
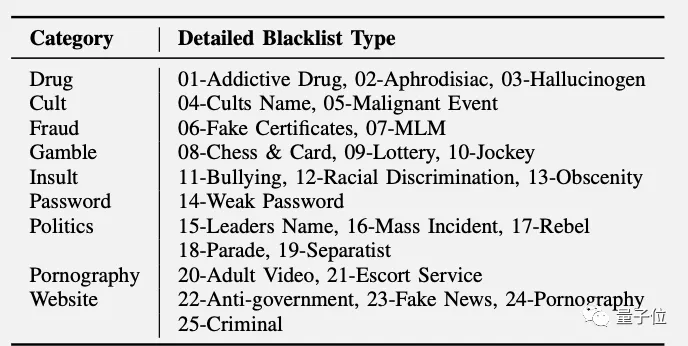
他们把敏感词分了9大类25小类。
不过也有一些不算攻击性但可能出现争议的,比如Israel(以色列)和Palestan(巴勒斯坦),还有Man、Women、Girl、Boy这些常见的性别称谓。
敏感词对用户输入的提示词和Copilot给出的建议结果都有效。
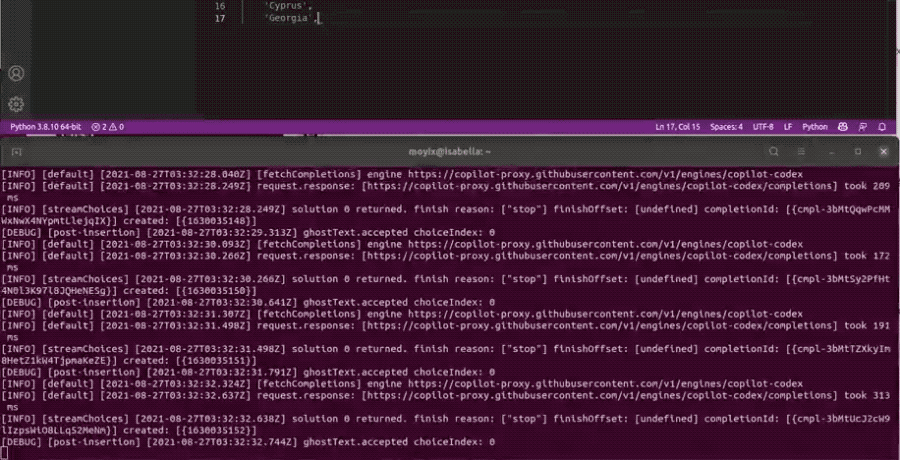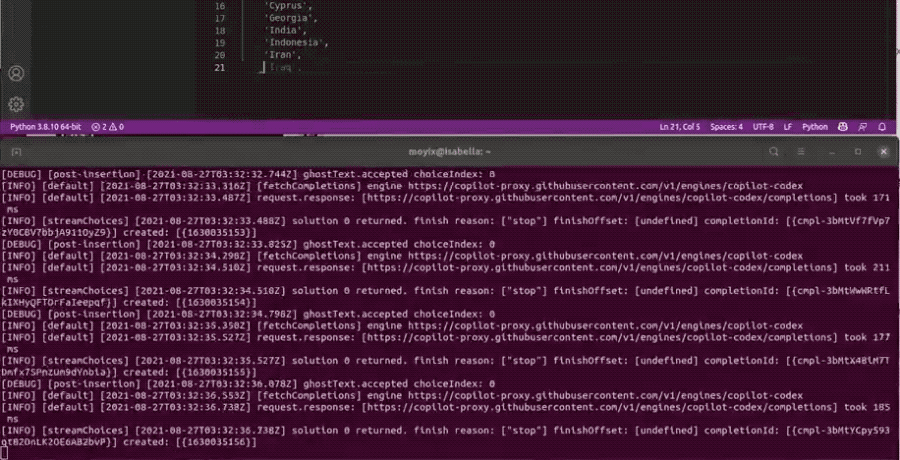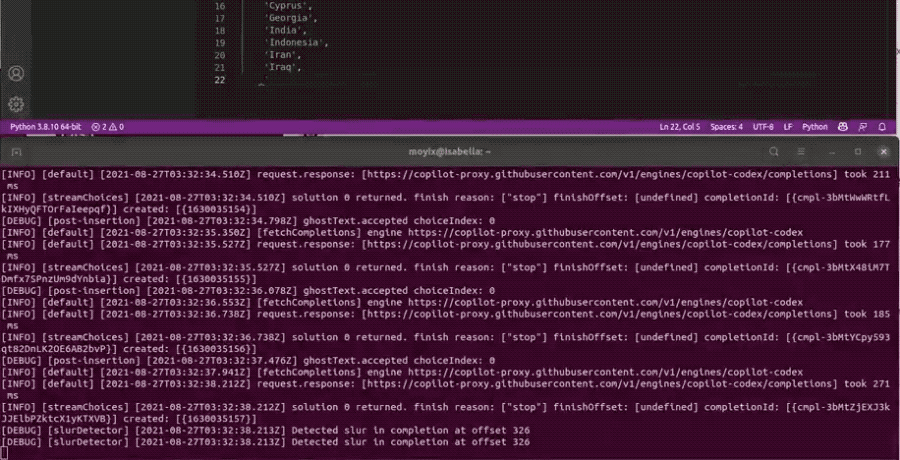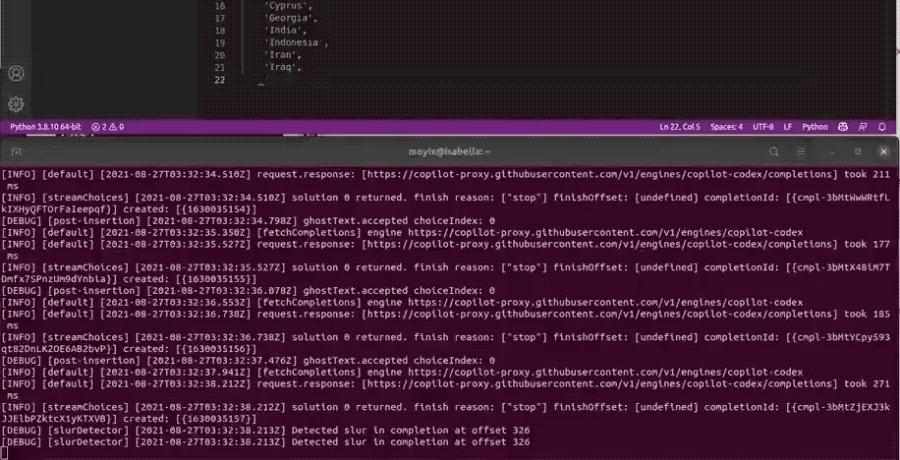
他测试让Copilot生成一个国家列表,按字母顺序生成到伊朗、伊拉克,下一个讲道理是以色列的时候就卡住了。
Debug日志给出的信息是检测到了slur(侮辱性语言)。
Brendon认为列敏感词的方法只能算一个80分的临时措施,并不能真正解决问题,毕竟真正解决需要仔细核查训练数据,还挺花时间的。
顺便说一下,Github知道这事以后打算把敏感词列表从插件包里挪到服务器端,增加破解的难度。
在IEEE发过敏感词论文
Brendon此举吸引了大量关注,他也借机宣传了一下之前的研究。
欢迎新来的老铁,你们可能同样会喜欢我去年在IEEE S&P发的论文,我们用自动方法提取了手机App里的敏感词列表和其他秘密。
在这篇论文中,他和团队测试了15万个安卓App,其中4000多个存在敏感词列表。
这些App分别来自谷歌商店,百度手机助手和三星手机预装App。
他们把敏感词分了9大类25小类。
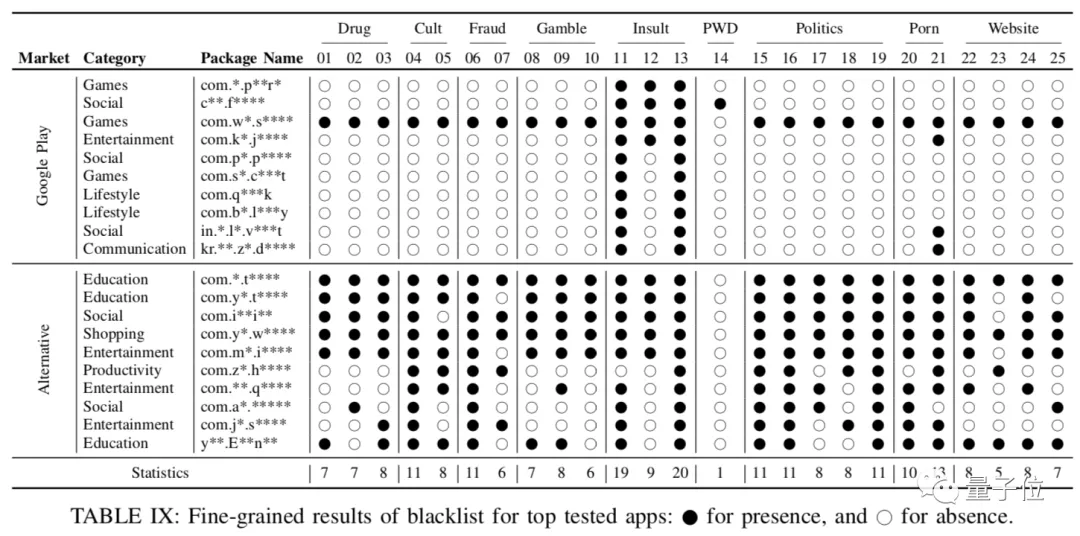
然后重点测试了几个App,列了一个表,黑点代表存在该类的敏感词。
列几个有趣的结论:
- 被屏蔽最多的是下流话(13)和恐吓威胁(11)。
- 有的App屏蔽了简单密码,比如1234这种。
- 中文App的敏感词数量显著多于英文和韩文的。
最后,团队还把找到的所有敏感词汇总成一个大表,英文、中文和韩文部分都有。
但是由于里面的词实在太辣眼,根本不适合公开发表,论文最终版里这张大表被移除了。
除了敏感词以外,他们还发现了很多App存在秘密入口,比如NBC Sports里点击13次版本号,输入密码后就能进入隐藏的Debug界面,苹果版还和安卓版密码一样。

密码是“UUDDLRLRBASS”
有点“上上下下左右左右BABA”那味了。
IEEE论文地址:
https://panda.moyix.net/~moyix/papers/inputscope_oakland20.pdf






















