本文转载自微信公众号「大鱼仙人」,作者大鱼仙人。转载本文请联系大鱼仙人公众号。
前言
之前有了服务的暴露和服务的引用了,服务提供者暴露出来服务了,服务消费者将其引用进来了,就差最后一步了,消费者和提供者之间的调用了,调用也就是真正的通信RPC过程,既然涉及到通信,就涉及到相应的客户端和服务端之间的交互协议,约定,以及序列化和反序列化机制
先说两边的约定其实就是客户端这边需要带着参数、参数类型,以及告诉服务端要调用的是哪个接口,这样服务端就知道要调用的接口了,服务端就可以执行了
关于应用层的协议的交互一般有三种形式,分别是:固定长度形式、特殊字符间隔形式和header+body形式,Dubbo支持dubbo、rmi、hessian、http、webservice、thrift、redis等多种协议,但是Dubbo官网是推荐我们使用Dubbo协议的
Dubbo协议

这种看看就行了,咱们主要了解下相应的特点,Dubbo协议采用单一长连接和NIO异步通讯,适合于小数据量大并发的服务调用,以及服务消费者机器数远大于服务提供者机器数的情况;不适合传送大数据量的服务,比如传文件,传视频等,除非请求量很低。
适用范围:传入传出参数数据包较小(建议小于100K),消费者比提供者个数多,单一消费者无法压满提供者,尽量不要用dubbo协议传输大文件或超大字符串。
为什么要消费者比提供者个数多?
因dubbo协议采用单一长连接,假设网络为千兆网卡(1024Mbit=128MByte),根据测试经验数据每条连接最多只能压满7MByte(不同的环境可能不一样,供参考),理论上1个服务提供者需要20个服务消费者才能压满网卡
为什么采用异步单一长连接?
因为服务的现状大都是服务提供者少,通常只有几台机器,而服务的消费者多,可能整个网站都在访问该服务,如果采用常规的服务,服务提供者很容易就被压跨,通过单一连接,保证单一消费者不会压死提供者,长连接,减少连接握手验证等,并使用异步IO,复用线程池,防止出现网络崩溃。
接口增加方法,对客户端无影响,如果该方法不是客户端需要的,客户端不需要重新部署;输入参数和结果集中增加属性,对客户端无影响,如果客户端并不需要新属性,不用重新部署
另外一个需要特别关注的点就是序列化,涉及到交互就会涉及到对象的传递,就会涉及到序列化,序列化就是内存中的数据对象转换成二进制流才可以进行数据持久化和网络传输,将数据对象转换为二进制流的过程称为对象的序列化(Serialization)。
反之,将二进制流恢复为数据对象的过程称为反序列化(Deserialization)。序列化需要保留充分的信息以恢复数据对象,但是为了节约存储空间和网络带宽,序列化后的二进制流又要尽可能小
常见的序列化方式有三种:Java原生序列化、Hessian序列化、Json序列化
Java原生序列化:Java类通过实现Serializable接口来实现该类对象的序列化,实现Serializable接口的类建议设置serialVersionUID字段值,如果不设置,那么每次运行时,编译器会根据类的内部实现,包括类名、接口名、方法和属性等来自动生成serialVersionUID。如果类的源代码有修改,那么重新编译后serial VersionUID的取值可能会发生变化。
因此实现Serializable接口的类一定要显式地定义serialVersionUID属性值。修改类时需要根据兼容性决定是否修改serialVersionUID值:
如果是兼容升级,请不要修改serialVersionUID字段,避免反序列化失败。
如果是不兼容升级,需要修改serialVersionUID值,避免反序列化混乱。
Hessian序列化:它的实现机制是着重于数据,附带简单的类型信息的方法。就像Integer a = 1,hessian会序列化成I 1这样的流,I表示int or Integer,1就是数据内容。而对于复杂对象,通过Java的反射机制,hessian把对象所有的属性当成一个Map来序列化,而在序列化过程中,如果一个对象之前出现过,hessian会直接插入一个R index这样的块来表示一个引用位置,从而省去再次序列化和反序列化的时间
在父类、子类存在同名成员变量的情况下, Hessian 序列化时,先序列化子类 ,然后序列化父类,因此反序列化结果会导致子类同名成员变量被父类的值覆盖。
Json序列化:是一种轻量级的数据交换格式。JSON 序列化就是将数据对象转换为 JSON 字符串。在序列化过程中抛弃了类型信息,所以反序列化时只有提供类型信息才能准确地反序列化。相比前两种方式,JSON 可读性比较好,方便调试
序列化通常会通过网络传输对象,而对象中往往有敏感数据,所以攻击者可以巧妙地利用反序列化过程构造恶意代码,使得程序在反序列化的过程中执行任意代码。
Java 工程中广泛使用的 Apache Commons Collections 、Jackson 、 fastjson 等都出现过反序列化漏洞。如何防范这种黑客攻击呢?
有些对象的敏感属性不需要进行序列化传输,可以加 transient 关键字,避免把此属性信息转化为序列化的二进制流。如果一定要传递对象的敏感属性,可以使用对称与非对称加密方式独立传输,再使用某个方法把属性还原到对象中。总之吧,就是有一定的防范意识
我们接下来要分析的就是调用过程了,先看一下官网的流程图
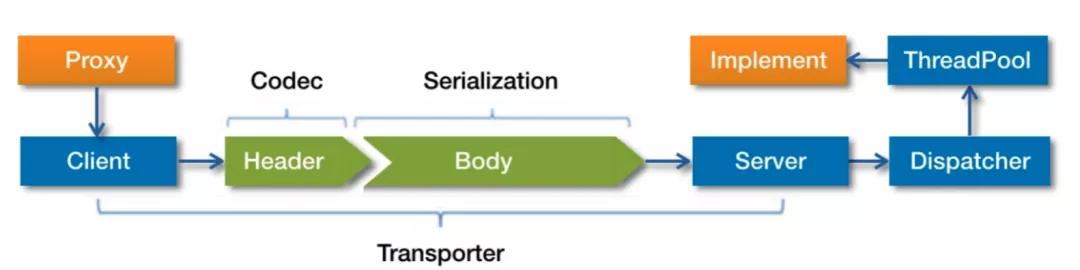
首先服务消费者通过代理对象 Proxy 发起远程调用,接着通过网络客户端 Client 将编码后的请求发送给服务提供方的网络层上,也就是 Server。Server 在收到请求后,首先要做的事情是对数据包进行解码。然后将解码后的请求发送至分发器 Dispatcher,再由分发器将请求派发到指定的线程池上,最后由线程池调用具体的服务。这就是一个远程调用请求的发送与接收过程。
整个调用链路大概就是分为三个步骤,我们按照这几个步骤来分析下:
1、消费者发起调用请求
2、提供者接收处理请求
3、消费者处理响应
消费者发起调用请求
消费者调用 Invoker 时,实际上调用的是一个由 Java 动态代理生成的代理对象。该代理对象经过 Cluster 层的路由与负载均衡,找到一个服务节点,将调用参数封装成 Request 形式,通过 Netty Client 将数据进行序列化,通过 Netty 发送给对应的服务提供者。
调用具体的接口会调用生成的代理类,而代理类会生成一个RpcInvocation对象调用MockClusterInvoke#invoke 方法,包括方法名、参数类和参数值,其实实际上最终调用的是AbstractClusterInvoker#invoker方法
入口在InvocationHandler这个家伙,这个类其中的invoke会得到调用结果,并把结果返回给调用方
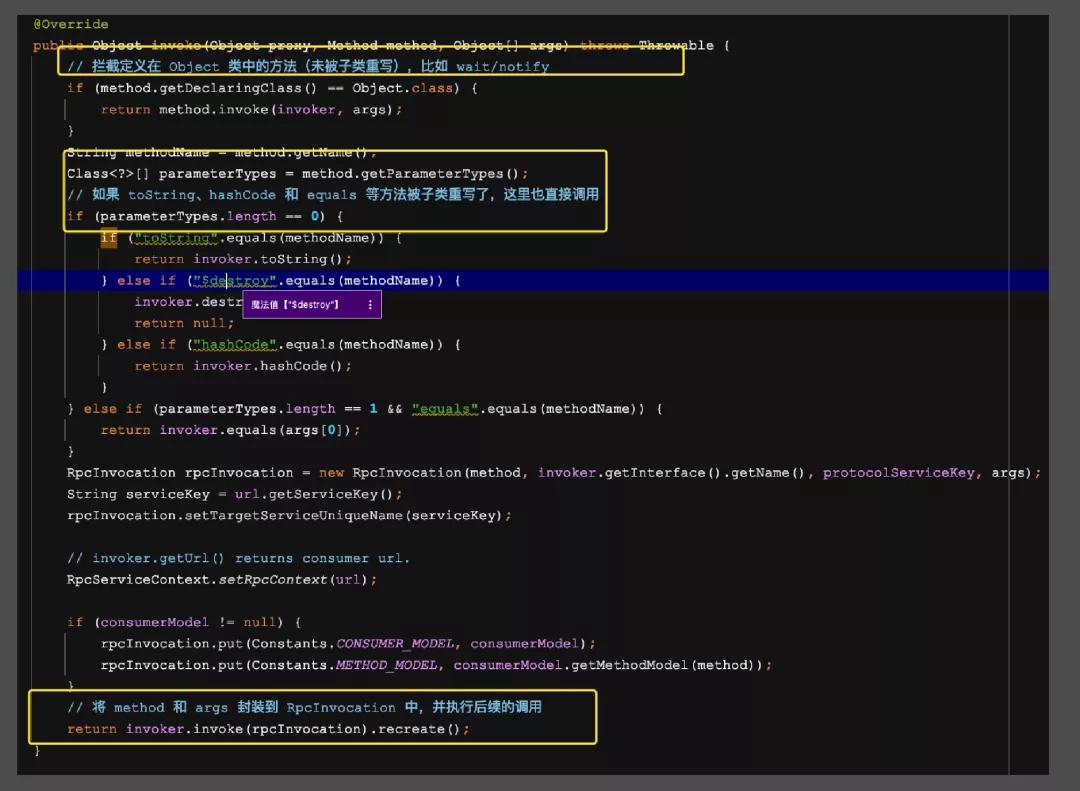
InvokerInvocationHandler 中的 invoker 成员变量类型为 MockClusterInvoker,MockClusterInvoker 内部封装了服务降级逻辑。下面简单看一下:

服务降级就简单看看就行了先,当然这也不是服务调用的重点
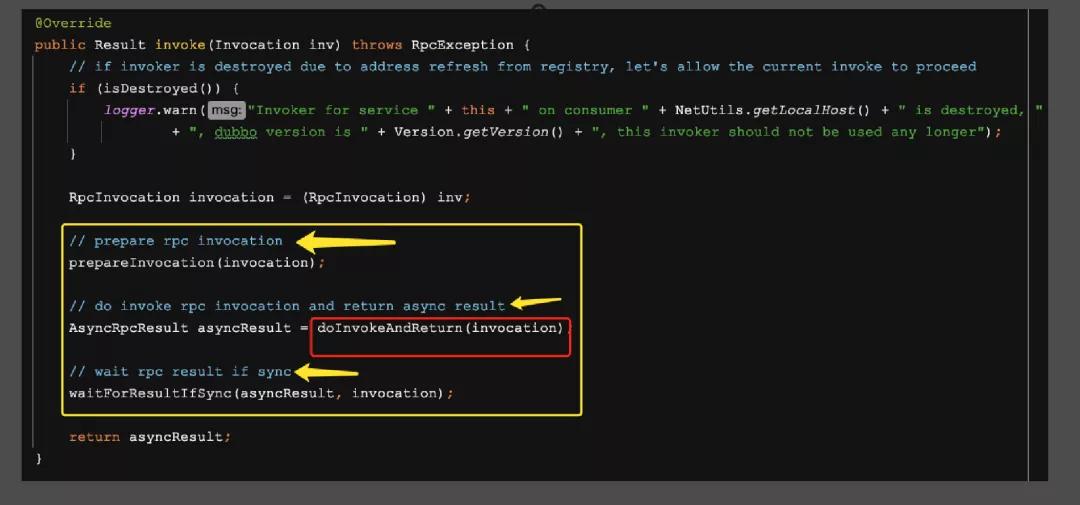
上面这块代码是AbstractInvoker类中的invoke方法,看注释分别是准备RPC的调用列表,然后是真正的调用并且返回结果,如果是异步的,则等待结果返回;
重点在第二步的doInvokeAndReturn中,点进去看到实际执行的是doInvoke方法,而这个方法在这个类中又是个抽象方法,需要由子类实现,下面到 DubboInvoker 中看一下。
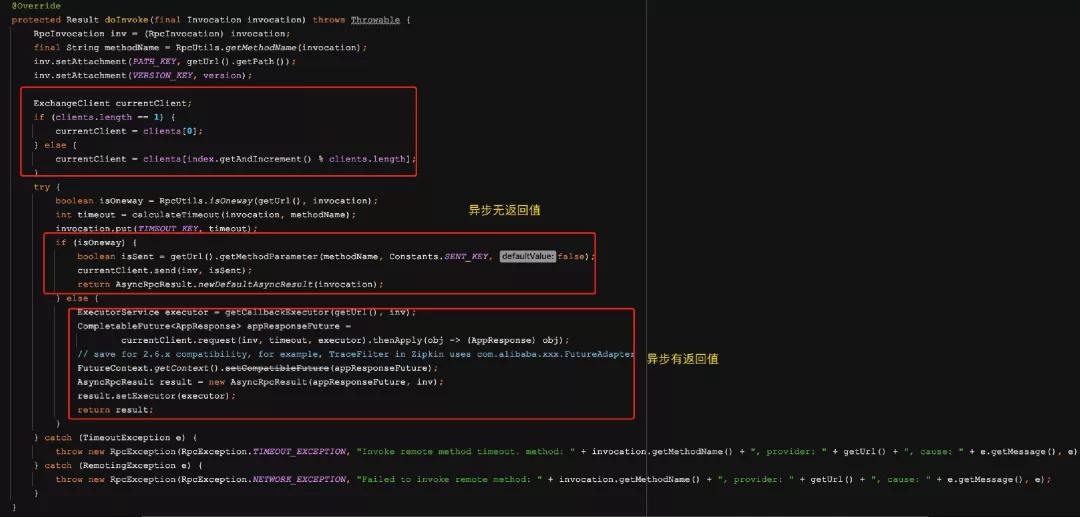
上面的代码包含了 Dubbo 对同步和异步调用的处理逻辑,搞懂了上面的代码,会对 Dubbo 的同步和异步调用方式有更深入的了解。Dubbo 实现同步和异步调用比较关键的一点就在于由谁调用 CompletableFuture 的 get 方法。同步调用模式下,由框架自身调用 CompletableFuture 的 get 方法。异步调用模式下,则由用户调用该方法。
当服务消费者还未接收到调用结果时,用户线程调用 get 方法会被阻塞住。同步调用模式下,框架获得 DefaultFuture 对象后,会立即调用 get 方法进行等待。而异步模式下则是将该对象封装到 FutureAdapter 实例中,并将 FutureAdapter 实例设置到 RpcContext 中,供用户使用
接下来我们看一个客户端HeaderExchangeClient,HeaderExchangeClient 中很多方法只有一行代码,即调用 HeaderExchangeChannel 对象的同签名方法。那 HeaderExchangeClient 有什么用处呢?答案是封装了一些关于心跳检测的逻辑
来到了其内部的属性HeaderExchangeChannel这个类之后,大家终于看到了 Request 语义了,上面的方法首先定义了一个 Request 对象,然后再将该对象传给 NettyClient 的 send 方法,进行后续的调用
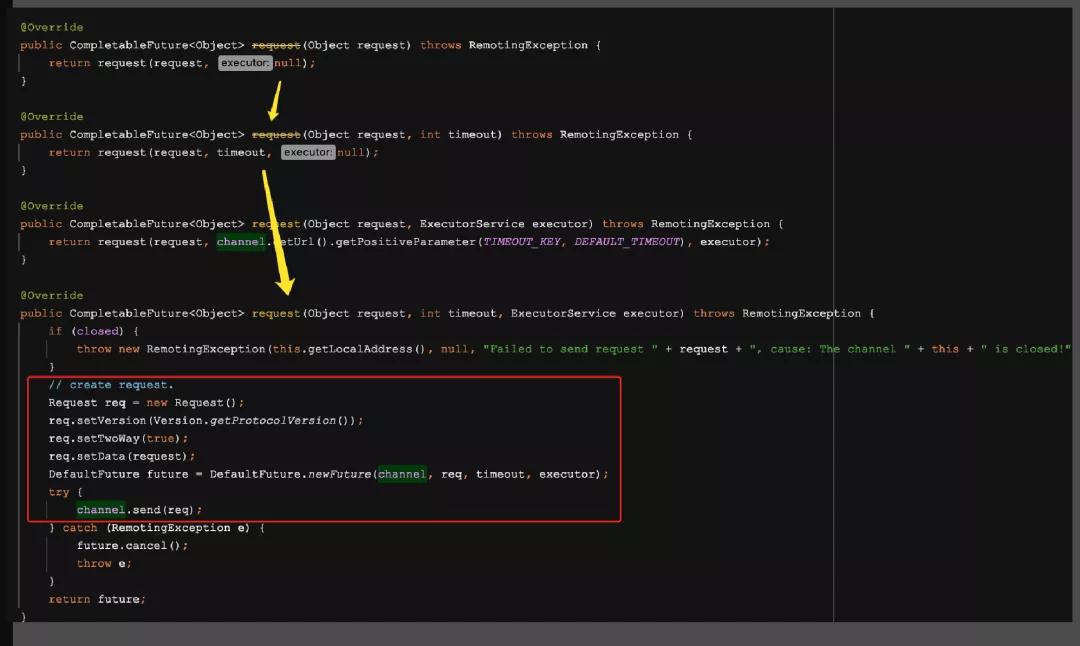
需要说明的是,NettyClient 中并未实现 send 方法,该方法继承自父类 AbstractPeer,看其子类AbstractClient类中的send实现
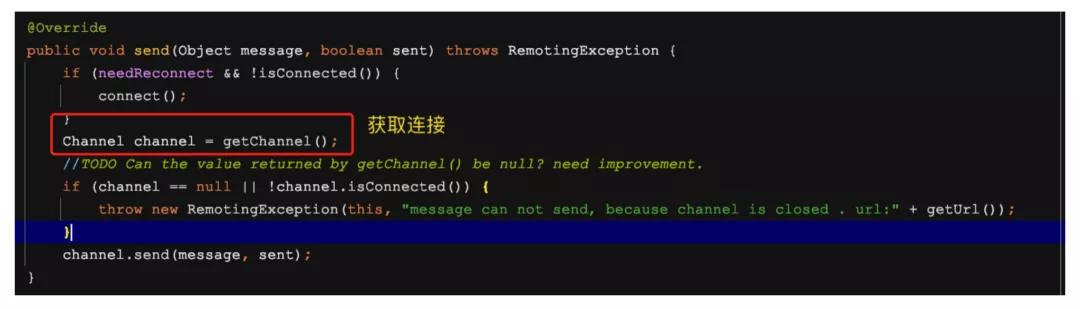
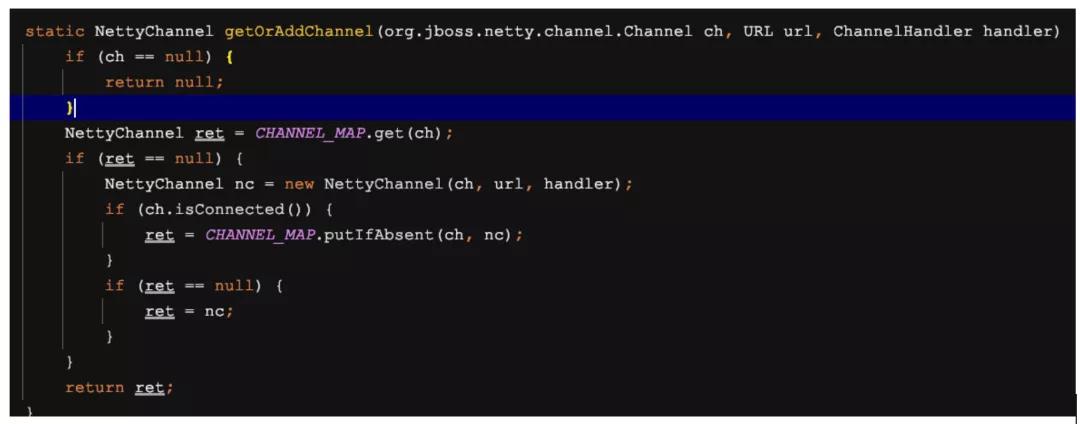
然后就是NettyChannel的send发送了
提供者接收处理请求
默认情况下 Dubbo 使用 Netty 作为底层的通信框架。Netty 检测到有数据入站后,首先会通过解码器对数据进行解码,并将解码后的数据包装成一个request对象传递给下一个入站处理器的指定方法。
解码器将数据包解析成 Request 对象后,NettyHandler 的 messageReceived 方法紧接着会收到这个对象,并将这个对象继续向下传递。
这期间该对象会被依次传递给 NettyServer、MultiMessageHandler、HeartbeatHandler 以及 AllChannelHandler。最后由 AllChannelHandler 将该对象封装到 Runnable 实现类对象中,并将 Runnable 放入线程池中执行后续的调用逻辑
我们了解一下Dubbo的线程派发模型:
背景呢就是如果一个处理事件很快执行完,此时可以直接在IO线程上执行完就行了,但是如果处理比较耗时呢,比如逻辑可能会发起DB查询或者HTTP请求,此时这种就不应该让事件处理逻辑在IO线程上执行,而是直接派发到线程池中去执行
原因很简单,IO线程主要是用来接收请求,如果IO被占满被阻塞,就不能接收新的请求了
举个例子,大公司业务数量大,核心部门A主要是负责分发业务的处理,会有其余部门分别处理,一些很简答的业务处理甚至还没有分发任务的耗时时间长,所以核心部门就直接处理了,你想啊,发一个任务一秒,如果处理这个业务只需要0.5秒,那就没必要去发这个业务了,直接自己处理了就可以了
于是就有了这个线程派发模型

Dispatcher就是线程派发器,但是它本身不具有线程派发能力,它的职责是创建具有线程派发能力的ChannelHandler,比如 AllChannelHandler、MessageOnlyChannelHandler 和 ExecutionChannelHandler 等,Dubbo 支持 5 种不同的线程派发策略

默认配置下,Dubbo 使用 all 派发策略,即将所有的消息都派发到线程池中
处理的逻辑我觉得没什么必要细细分析了,无非就是封装成Runnable交给handler分发的线程来处理,然后把结果封装成response,返回该对象
消费者处理响应
响应数据解码完成后,Dubbo 会将响应对象派发到线程池上。要注意的是,线程池中的线程并非用户的调用线程,所以要想办法将响应对象从线程池线程传递到用户线程上。
一般情况下,服务消费方会并发调用多个服务,每个用户线程发送请求后,会调用不同 DefaultFuture 对象的 get 方法进行等待。
一段时间后,服务消费方的线程池会收到多个响应对象。这个时候要考虑一个问题,如何将每个响应对象传递给相应的 DefaultFuture 对象,且不出错
消费者接收到提供者发来的响应,解码后投入到线程分发器中,置入线程池。
放到线程池的是一个 DefaultFuture 对象,其中包含了响应结果。在前面第一步发起调用请求的过程中,负载均衡之后的调用就是通过 RpcInvocation 代理对象使用 DefaultFuture.get() 方法异步获取响应内容,这也是 RPC 远程调用从同步转为异步的方式。
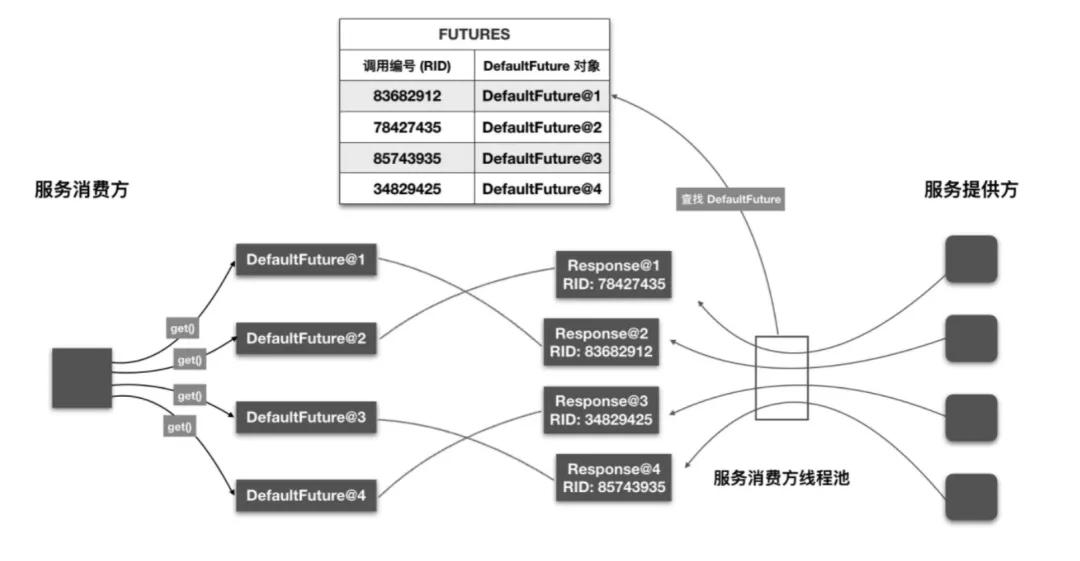
答案是通过调用编号。DefaultFuture 被创建时,会要求传入一个 Request 对象。此时 DefaultFuture 可从 Request 对象中获取调用编号,并将 <调用编号, DefaultFuture 对象> 映射关系存入到静态 Map 中,即 FUTURES
线程池中的线程在收到 Response 对象后,会根据 Response 对象中的调用编号到 FUTURES 集合中取出相应的 DefaultFuture 对象,然后再将 Response 对象设置到 DefaultFuture 对象中。
最后再唤醒用户线程,这样用户线程即可从 DefaultFuture 对象中获取调用结果了