本文转载自微信公众号「有关SQL」,作者Lenis 。转载本文请联系有关SQL公众号。
“你们最大的表,有多少数据量?”
圈子里几个常玩的伙伴,聚在一起吃火锅,或者喝咖啡,通常都会问些特技术范儿的问题。上面这个,就是常问的问题之一。
其实,倒也不是真对数据量感兴趣,而是量大了之后,碰到什么特别有意思的事情,以及,用了什么特别的方法解决。
上亿了之后,怎么解决;上 TB 级别的存储量,又怎么解决。
就这样的问题,如果是在星巴克,大家伙儿都能吹到下半夜去。我记得,最带劲的刘哥,一言不合,就打开黑乎乎的 shell, 给我们演示。
像这样的大表场景,如果分库分表,就是最终杀器。刚开始,几个外企和民企的朋友,还经常吵嘴。一波人说分库分表,另一波说 sharding, partitioning, 吵来吵去,都是一个意思。
Partition 不是数据库中常说的表分区,实际上它和分库分表一个意思。而 Sharding (分片)则是 MongoDB, ElasticSearch 等这类 NoSQL 数据库针对分库分表的专有术语。
那么,分库分表究竟该怎么用呢,涉及到的原理都有哪些呢?说实话,这个话题太大,在本文中,并不能全部一一说到,我只挑自己理解的来说。
读和写,数据库之本
这看起来是句废话。数据库可不就用来存储,和返回数据的嘛!是的,同学你可以把搬砖放下,还不到砸我的时候。
读和写是基本,就和人要吃饭运动一样,是最基本生理活动。人吃饭吃多了,或者运动过多了,那问题就大了。一旦读和写,都开始多起来了,同样也会带来一系列的问题。
读自己的数据,让别人无数据可读
这,并不是玩笑话。但它有个前提,数据库的连接数,是有限的。一旦超额,就再也无法新建连接。此时,只有先连上的用户,才能读取数据。之后的请求,只能排队等待,或者干脆收到 timeout(超时) 警告。
说到这,顺便再提下,前两天我在谈到 Replication(复制时), 提到农村里看电影的例子。
80年代的农村,经常有戏班子来放露天电影。所谓“露天”,就是临时在村头,搭个舞台,吊块幕布,把电影投射上去,支个功放,村民就开始看电影了。
画个草图,大概就是这样子:
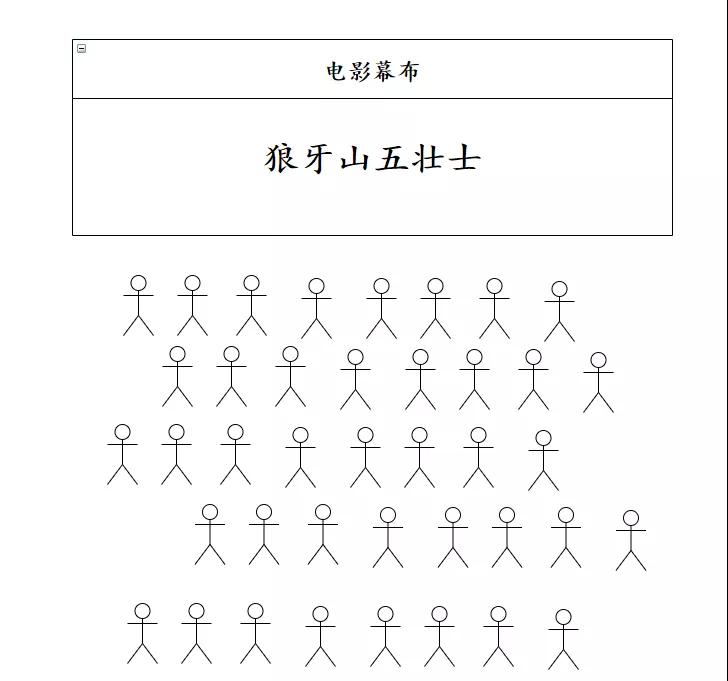
这露天电影有个难受的地方,前排的人,耳朵炸聋,后排的人,啥都听不见。观影体验贼差,所以整场下来,只有小孩和真正的影迷,能坚持到最后。其他人中途都跑了。
所以戏班子想了个法儿,在村头村尾各搭个舞台。这样容纳的人就多了。有些村实在口人太大,那就村东村西,再放两个舞台。这样村子里所有人,都可以照顾到了。而实现这个目的,就只需复刻 3 份胶卷。
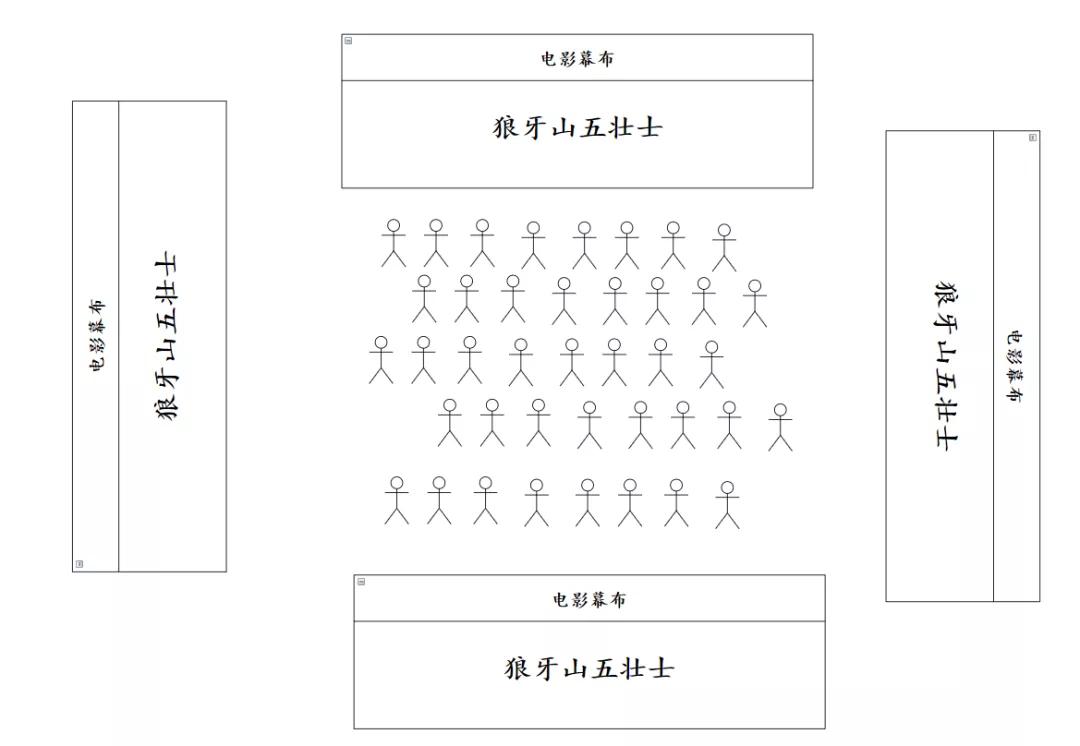
这就是数据库复制原理所在。把数据复刻多份的时候,就可以供更多人读取。
所谓“做人留一线,日后好相见”。看个电影而已,没必要伤害乡里乡亲的感情。大家为了抢一个好位置,最后结局只能是谁都看得不爽。所以这里看不了,我就去别的场地看。
复制技术出来之后,读数据就不抢占一个库了。这台服务器读请求,在排队,那就去另一台服务器。假设网络里,服务器够多,那么总有一台能读到数据。
SQL Server 可以支持 8 台服务器同时服务读,而 MySQL 通过中间件,则可以支持更多,比如 MySQL Proxy, MySQL Cat, MySQL DAL等等。
写入时代大爆炸
之前欣赏电影,只能在电影院,生产这些电影,往往都是大团队。那时,看电影,纯属于消费时代。
但4G, 5G来了之后,消费时代悄然变化了。小团队,甚至个人,开始制作电影。小众视频,胜在长尾效应。比如 Youtube, B 站,这个时代,人人兼可创作。
如此之多的视频,仅靠电影制片厂,是完全来不及生产了。网民集体的创作狂热,必须由民间力量,B站,爱奇艺,腾讯视频等等,来 Hold 住。
就像,你的数据库,在经历了 7, 8年的发展后,受众越来越多,大家写入的热情也越来越高涨。此时,数据库,也将面临跟视频网站一样的困扰,究竟该如何支撑主这些 “洪流”?
经历了大爆炸后,视频平台痛下决心,把视频服务器分散,开到全国去。在全国各个重要的大城市,组建视频中心,让周围的视频创作者,把视频传到这些服务器上。
这就是分库分表的模式。

虽然华东南西北中,是相互独立的,但它们的视频始终都以逻辑整体存在。一个VLOG作者,在北京上传了个视频,如果坐飞机到了广州,他就访问不到在北京上传的那个视频,那怎么也说不过去。
所以,所有这些视频,都是维护在一张逻辑表中。根据这些视频的上传者GIS地址,传到最近的服务器上。这就是分库分表常用的,按 Key 值分区策略。虽然这样的策略,会有一系列问题,但暂且这么理解。
分库分表好处非常明显,一来可以容纳更多数据量,二来访问更快捷。
怎么实现分库分表呢?
有人说,可以用客户端代码来控制访问数据库;也有人说,我就爱写中间件,让服务器自动支持分库分表,并且没有语言限制,也很极客;还有人说,用云原生,程序员负责实现逻辑,运维这档子事交给供应商。
当然,统统都可以。但是本文还是着重讲讲中间件。毕竟,供应商费银子,客户端费脑子,只有中间件,可以一劳永逸。
分享 2 种方法:
Percona XtraDB Cluster方案
Percona XtraDB Cluster简称PXC。Percona Xtradb Cluster的实现是在原mysql代码上通过Galera包将不同的mysql实例连接起来,实现了multi-master的集群架构。
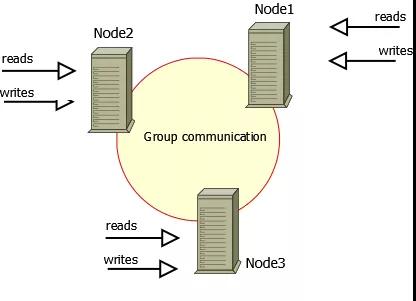
上图中有三个实例,组成了一个集群,而这三个节点与普通的主从架构不同,它们都可以作为主节点,三个节点是对等的,这种一般称为multi-master架构,当有客户端要写入或者读取数据时,随便连接哪个实例都是一样的,读到的数据是相同的,写入某一个节点之后,集群自己会将新数据同步到其它节点上面,这种架构不共享任何数据,是一种高冗余架构。
作者:罗阿红 出处:http://www.cnblogs.com/luoahong/
MySQL DAL (Data Access Layer )
当年手机之家高春辉领导开发的产品。它解决了单台计算机容量有限的难题。真正实现了分库分表的优势。
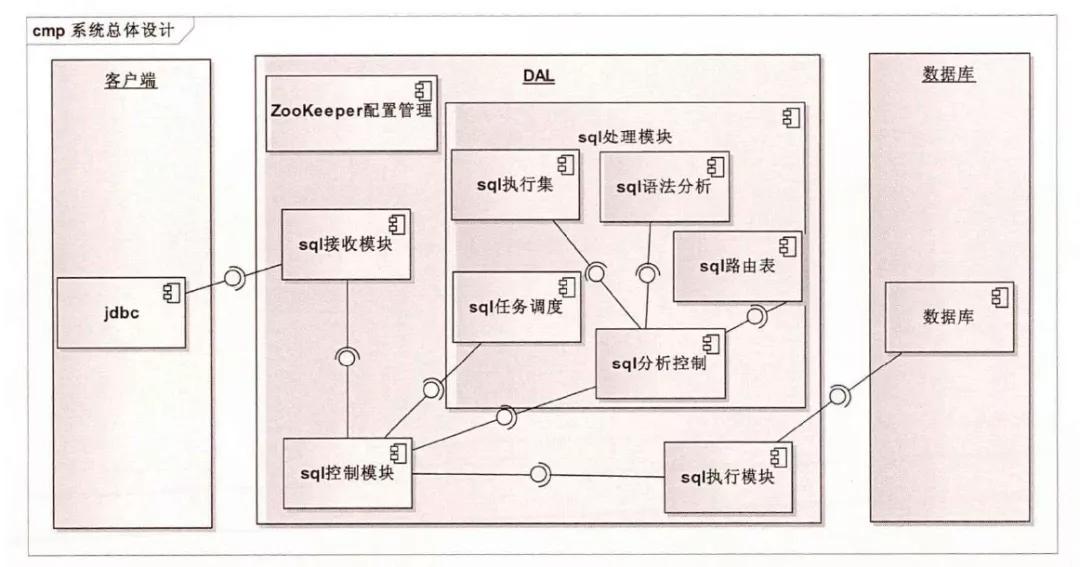
DAL 有三大组件,Java Netty 框架,ZooKeep 控态,SQL 处理模块( 通过分解 SQL 生成语法树,依据 SQL 路由表,生成对应的执行路径)
由于 MySQL DAL 是闭源产品,相关的实现没有源码可看。但我看到这篇论文有提及部分原理:

嗯,上次有微信群水友问,数据库开发与数据库开发有什么区别。大概在这里,可以说的明白了。
一类人,是做CRUD应用系统的开发,比如做个报表,写个ETL;另一类数据库开发,是实现数据库的某项功能,比如分库分表组件。