本文转载自微信公众号「Golang梦工厂」,作者AsongGo 。转载本文请联系Golang梦工厂公众号。
背景
伴随着微服务架构被宣传得如火如茶,一些概念也被推到了我们的面前。一提到微服务,就离不开这几个字:高内聚低耦合;微服务的架构设计最终目的也就是实现这几个字。在微服务架构中,微服务就是完成一个单一的业务功能,每个微服务可以独立演进,一个应用可能会有多个微服务组成,微服务之间的数据交可以通过远程调用来完成,这样在一个微服务架构下就会形成这样的依赖关系:
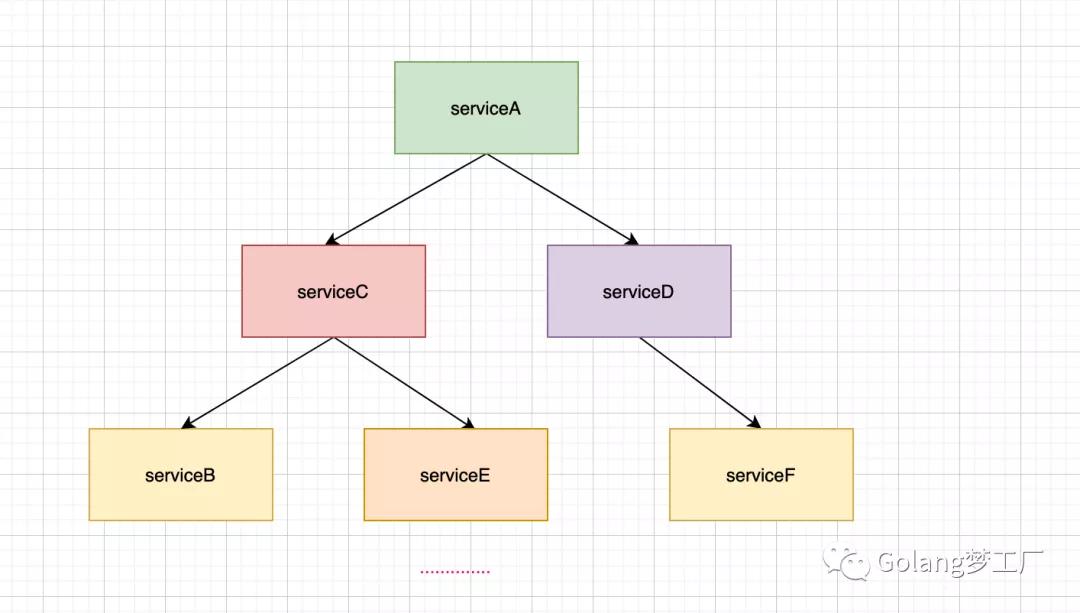
微服务A调用微服务C、D,微服务B又依赖微服务B、E,微服务D依赖于服务F,这只是一个简单的小例子,实际业务中服务之间的依赖关系比这还复杂,这样在调用链路上如果某个微服务的调用响应时间过长或者不可用,那么对上游服务(按调用关系命名)的调用就会占用越来越多的系统资源,进而引起系统崩溃,这就是微服务的雪蹦效应。
为了解决微服务的雪蹦效应,提出来使用熔断机制为微服务链路提供保护机制。熔断机制大家应该都不陌生,电路的中保险丝就是一种熔断机制,在微服务中的熔断机制是什么样的呢?
当链路中的某个微服务不可用或者响应的时间太长时,会进行服务的降级,进而熔断该节点微服务的调用,快速返回错误的响应信息,当检测到该节点微服务调用响应正常后,恢复调用链路。
本文我们就介绍一个开源熔断框架:hystrix-go。
熔断框架(hystrix-go)
Hystrix是一个延迟和容错库,旨在隔离对远程系统、服务和第三方服务的访问点,停止级联故障并在故障不可避免的复杂分布式系统中实现弹性。hystrix-go 旨在允许 Go 程序员轻松构建具有与基于 Java 的 Hystrix 库类似的执行语义的应用程序。所以本文就从使用开始到源码分析一下hystrix-go。
快速安装
- go get -u github.com/afex/hystrix-go/hystrix
快速使用
hystrix-go真的是开箱即用,使用还是比较简单的,主要分为两个步骤:
- 配置熔断规则,否则将使用默认配置。可以调用的方法
- func Configure(cmds map[string]CommandConfig)
- func ConfigureCommand(name string, config CommandConfig)
Configure方法内部也是调用的ConfigureCommand方法,就是传参数不一样,根据自己的代码风格选择。
- 定义依赖于外部系统的应用程序逻辑 - runFunc 和服务中断期间执行的逻辑代码 - fallbackFunc,可以调用的方法:
- func Go(name string, run runFunc, fallback fallbackFunc) // 内部调用Goc方法
- func GoC(ctx context.Context, name string, run runFuncC, fallback fallbackFuncC)
- func Do(name string, run runFunc, fallback fallbackFunc) // 内部调用的是Doc方法
- func DoC(ctx context.Context, name string, run runFuncC, fallback fallbackFuncC) // 内部调用Goc方法,处理了异步过程
Go和Do的区别在于异步还是同步,Do方法在调用Doc方法内处理了异步过程,他们最终都是调用的Goc方法。后面我们进行分析。
举一个例子:我们在Gin框架上加一个接口级的熔断中间件
- // 代码已上传github: 文末查看地址
- var CircuitBreakerName = "api_%s_circuit_breaker"
- func CircuitBreakerWrapper(ctx *gin.Context){
- name := fmt.Sprintf(CircuitBreakerName,ctx.Request.URL)
- hystrix.Do(name, func() error {
- ctx.Next()
- code := ctx.Writer.Status()
- if code != http.StatusOK{
- return errors.New(fmt.Sprintf("status code %d", code))
- }
- return nil
- }, func(err error) error {
- if err != nil{
- // 监控上报(未实现)
- _, _ = io.WriteString(f, fmt.Sprintf("circuitBreaker and err is %s\n",err.Error())) //写入文件(字符串)
- fmt.Printf("circuitBreaker and err is %s\n",err.Error())
- // 返回熔断错误
- ctx.JSON(http.StatusServiceUnavailable,gin.H{
- "msg": err.Error(),
- })
- }
- return nil
- })
- }
- func init() {
- hystrix.ConfigureCommand(CircuitBreakerName,hystrix.CommandConfig{
- Timeout: int(3*time.Second), // 执行command的超时时间为3s
- MaxConcurrentRequests: 10, // command的最大并发量
- RequestVolumeThreshold: 100, // 统计窗口10s内的请求数量,达到这个请求数量后才去判断是否要开启熔断
- SleepWindow: int(2 * time.Second), // 当熔断器被打开后,SleepWindow的时间就是控制过多久后去尝试服务是否可用了
- ErrorPercentThreshold: 20, // 错误百分比,请求数量大于等于RequestVolumeThreshold并且错误率到达这个百分比后就会启动熔断
- })
- if checkFileIsExist(filename) { //如果文件存在
- f, errfile = os.OpenFile(filename, os.O_APPEND, 0666) //打开文件
- } else {
- f, errfile = os.Create(filename) //创建文件
- }
- }
- func main() {
- defer f.Close()
- hystrixStreamHandler := hystrix.NewStreamHandler()
- hystrixStreamHandler.Start()
- go http.ListenAndServe(net.JoinHostPort("", "81"), hystrixStreamHandler)
- r := gin.Default()
- r.GET("/api/ping/baidu", func(c *gin.Context) {
- _, err := http.Get("https://www.baidu.com")
- if err != nil {
- c.JSON(http.StatusInternalServerError, gin.H{"msg": err.Error()})
- return
- }
- c.JSON(http.StatusOK, gin.H{"msg": "success"})
- }, CircuitBreakerWrapper)
- r.Run() // listen and serve on 0.0.0.0:8080 (for windows "localhost:8080")
- }
- func checkFileIsExist(filename string) bool {
- if _, err := os.Stat(filename); os.IsNotExist(err) {
- return false
- }
- return true
- }
指令:wrk -t100 -c100 -d1s http://127.0.0.1:8080/api/ping/baidu
运行结果:
- circuitBreaker and err is status code 500
- circuitBreaker and err is status code 500
- .....
- circuitBreaker and err is hystrix: max concurrency
- circuitBreaker and err is hystrix: max concurrency
- .....
- circuitBreaker and err is hystrix: circuit open
- circuitBreaker and err is hystrix: circuit open
- .....
对错误进行分析:
- circuitBreaker and err is status code 500:因为我们关闭了网络,所以请求是没有响应的
- circuitBreaker and err is hystrix: max concurrency:我们设置的最大并发量MaxConcurrentRequests是10,我们的压测工具使用的是100并发,所有会触发这个熔断
- circuitBreaker and err is hystrix: circuit open:我们设置熔断开启的请求数量RequestVolumeThreshold是100,所以当10s内的请求数量大于100时就会触发熔断。
简单对上面的例子做一个解析:
- 添加接口级的熔断中间件
- 初始化熔断相关配置
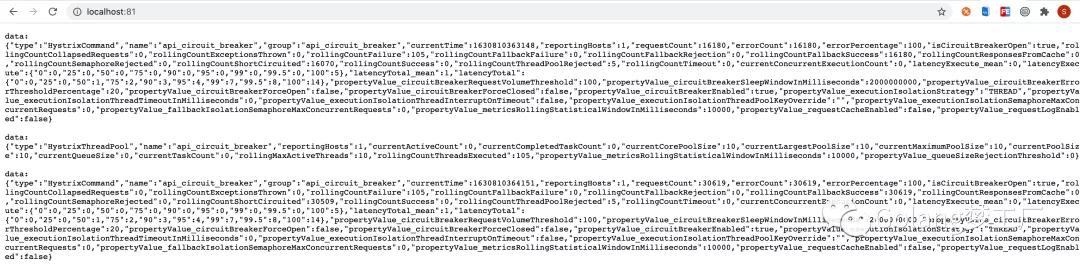
- 开启dashboard 可视化hystrix的上报信息,浏览器打开http://localhost:81,可以看到如下结果:
hystrix-go流程分析
本来想对源码进行分析,代码量有点大,所以就针对流程来分析,顺便看一些核心代码。
配置熔断规则
既然是熔断,就要有熔断规则,我们可以调用两个方法配置熔断规则,不会最终调用的都是ConfigureCommand,这里没有特别的逻辑,如果我们没有配置,系统将使用默认熔断规则:
- var (
- // DefaultTimeout is how long to wait for command to complete, in milliseconds
- DefaultTimeout = 1000
- // DefaultMaxConcurrent is how many commands of the same type can run at the same time
- DefaultMaxConcurrent = 10
- // DefaultVolumeThreshold is the minimum number of requests needed before a circuit can be tripped due to health
- DefaultVolumeThreshold = 20
- // DefaultSleepWindow is how long, in milliseconds, to wait after a circuit opens before testing for recovery
- DefaultSleepWindow = 5000
- // DefaultErrorPercentThreshold causes circuits to open once the rolling measure of errors exceeds this percent of requests
- DefaultErrorPercentThreshold = 50
- // DefaultLogger is the default logger that will be used in the Hystrix package. By default prints nothing.
- DefaultLogger = NoopLogger{}
- )
配置规则如下:
- Timeout:定义执行command的超时时间,时间单位是ms,默认时间是1000ms;
- MaxConcurrnetRequests:定义command的最大并发量,默认值是10并发量;
- SleepWindow:熔断器被打开后使用,在熔断器被打开后,根据SleepWindow设置的时间控制多久后尝试服务是否可用,默认时间为5000ms;
- RequestVolumeThreshold:判断熔断开关的条件之一,统计10s(代码中写死了)内请求数量,达到这个请求数量后再根据错误率判断是否要开启熔断;
- ErrorPercentThreshold:判断熔断开关的条件之一,统计错误百分比,请求数量大于等于RequestVolumeThreshold并且错误率到达这个百分比后就会启动熔断 默认值是50;
这些规则根据command的name进行区分存放到一个map中。
执行command
执行command主要可以调用四个方法,分别是:
- func Go(name string, run runFunc, fallback fallbackFunc)
- func GoC(ctx context.Context, name string, run runFuncC, fallback fallbackFuncC)
- func Do(name string, run runFunc, fallback fallbackFunc)
- func DoC(ctx context.Context, name string, run runFuncC, fallback fallbackFuncC)
Do内部调用的Doc方法,Go内部调用的是Goc方法,在Doc方法内部最终调用的还是Goc方法,只是在Doc方法内做了同步逻辑:
- func DoC(ctx context.Context, name string, run runFuncC, fallback fallbackFuncC) error {
- ..... 省略部分封装代码
- var errChan chan error
- if fallback == nil {
- errChan = GoC(ctx, name, r, nil)
- } else {
- errChan = GoC(ctx, name, r, f)
- }
- select {
- case <-done:
- return nil
- case err := <-errChan:
- return err
- }
- }
因为他们最终都是调用的Goc方法,所以我们执行分析Goc方法的内部逻辑;代码有点长,我们分逻辑来分析:
创建command对象
- cmd := &command{
- run: run,
- fallback: fallback,
- start: time.Now(),
- errChan: make(chan error, 1),
- finished: make(chan bool, 1),
- }
- // 获取熔断器
- circuit, _, err := GetCircuit(name)
- if err != nil {
- cmd.errChan <- err
- return cmd.errChan
- }
介绍一下command的数据结构:
- type command struct {
- sync.Mutex
- ticket *struct{}
- start time.Time
- errChan chan error
- finished chan bool
- circuit *CircuitBreaker
- run runFuncC
- fallback fallbackFuncC
- runDuration time.Duration
- events []string
- }
字段介绍:
- ticket:用来做最大并发量控制,这个就是一个令牌
- start:记录command执行的开始时间
- errChan:记录command执行错误
- finished:标志command执行结束,用来做协程同步
- circuit:存储熔断器相关信息
- run:应用程序
- fallback:应用程序执行失败后要执行的函数
- runDuration:记录command执行消耗时间
- events:events主要是存储事件类型信息,比如执行成功的success,或者失败的timeout、context_canceled等
上段代码重点是GetCircuit方法,这一步的目的就是获取熔断器,使用动态加载的方式,如果没有就创建一个熔断器,熔断器结构如下:
- type CircuitBreaker struct {
- Name string
- open bool
- forceOpen bool
- mutex *sync.RWMutex
- openedOrLastTestedTime int64
- executorPool *executorPool
- metrics *metricExchange
- }
解释一下这几个字段:
- name:熔断器的名字,其实就是创建的command名字
- open:判断熔断器是否打开的标志
- forceopen:手动触发熔断器的开关,单元测试使用
- mutex:使用读写锁保证并发安全
- openedOrLastTestedTime:记录上一次打开熔断器的时间,因为要根据这个时间和SleepWindow时间来做恢复尝试
- executorPool:用来做流量控制,因为我们有一个最大并发量控制,就是根据这个来做的流量控制,每次请求都要获取令牌
metrics:用来上报执行状态的事件,通过它把执行状态信息存储到实际熔断器执行各个维度状态 (成功次数,失败次数,超时……) 的数据集合中。
后面会单独分析executorPool、metrics的实现逻辑。
定义令牌相关的方法和变量
因为我们有一个条件是最大并发控制,采用的是令牌的方式进行流量控制,每一个请求都要获取一个令牌,使用完毕要把令牌还回去,先看一下这段代码:
- ticketCond := sync.NewCond(cmd)
- ticketChecked := false
- // When the caller extracts error from returned errChan, it's assumed that
- // the ticket's been returned to executorPool. Therefore, returnTicket() can
- // not run after cmd.errorWithFallback().
- returnTicket := func() {
- cmd.Lock()
- // Avoid releasing before a ticket is acquired.
- for !ticketChecked {
- ticketCond.Wait()
- }
- cmd.circuit.executorPool.Return(cmd.ticket)
- cmd.Unlock()
- }
使用sync.NewCond创建一个条件变量,用来协调通知你可以归还令牌了。
然后定义一个返回令牌的方法,调用Return方法归还令牌。
定义上报执行事件的方法
前面我们也提到了,我们的熔断器会上报执行状态的事件,通过它把执行状态信息存储到实际熔断器执行各个维度状态 (成功次数,失败次数,超时……) 的数据集合中。所以要定义一个上报的方法:
- reportAllEvent := func() {
- err := cmd.circuit.ReportEvent(cmd.events, cmd.start, cmd.runDuration)
- if err != nil {
- log.Printf(err.Error())
- }
- }
开启协程一:执行应用程序逻辑 - runFunc
协程一的主要目的就是执行应用程序逻辑:
- go func() {
- defer func() { cmd.finished <- true }() // 标志协程一的command执行结束,同步到协程二
- // 当最近执行的并发数量超过阈值并且错误率很高时,就会打开熔断器。
- // 如果熔断器打开,直接拒绝拒绝请求并返回令牌,当感觉健康状态恢复时,熔断器将允许新的流量。
- if !cmd.circuit.AllowRequest() {
- cmd.Lock()
- // It's safe for another goroutine to go ahead releasing a nil ticket.
- ticketChecked = true
- ticketCond.Signal() // 通知释放ticket信号
- cmd.Unlock()
- // 使用sync.Onece保证只执行一次。
- returnOnce.Do(func() {
- // 返还令牌
- returnTicket()
- // 执行fallback逻辑
- cmd.errorWithFallback(ctx, ErrCircuitOpen)
- // 上报状态事件
- reportAllEvent()
- })
- return
- }
- // 控制并发
- cmd.Lock()
- select {
- // 获取到令牌
- case cmd.ticket = <-circuit.executorPool.Tickets:
- // 发送释放令牌信号
- ticketChecked = true
- ticketCond.Signal()
- cmd.Unlock()
- default:
- // 没有令牌可用了, 也就是达到最大并发数量则直接处理fallback逻辑
- ticketChecked = true
- ticketCond.Signal()
- cmd.Unlock()
- returnOnce.Do(func() {
- returnTicket()
- cmd.errorWithFallback(ctx, ErrMaxConcurrency)
- reportAllEvent()
- })
- return
- }
- // 执行应用程序逻辑
- runStart := time.Now()
- runErr := run(ctx)
- returnOnce.Do(func() {
- defer reportAllEvent() // 状态事件上报
- // 统计应用程序执行时长
- cmd.runDuration = time.Since(runStart)
- // 返还令牌
- returnTicket()
- // 如果应用程序执行失败执行fallback函数
- if runErr != nil {
- cmd.errorWithFallback(ctx, runErr)
- return
- }
- cmd.reportEvent("success")
- })
- }()
总结一下这个协程:
- 判断熔断器是否打开,如果打开了熔断器直接进行熔断,不在进行后面的请求
- 运行应用程序逻辑
开启协程二:同步协程一并监听错误
先看代码:
- go func() {
- // 使用定时器来做超时控制,这个超时时间就是我们配置的,默认1000ms
- timer := time.NewTimer(getSettings(name).Timeout)
- defer timer.Stop()
- select {
- // 同步协程一
- case <-cmd.finished:
- // returnOnce has been executed in another goroutine
- // 是否收到context取消信号
- case <-ctx.Done():
- returnOnce.Do(func() {
- returnTicket()
- cmd.errorWithFallback(ctx, ctx.Err())
- reportAllEvent()
- })
- return
- // command执行超时了
- case <-timer.C:
- returnOnce.Do(func() {
- returnTicket()
- cmd.errorWithFallback(ctx, ErrTimeout)
- reportAllEvent()
- })
- return
- }
- }()
这个协程的逻辑比较清晰明了,目的就是监听业务执行被取消以及超时。
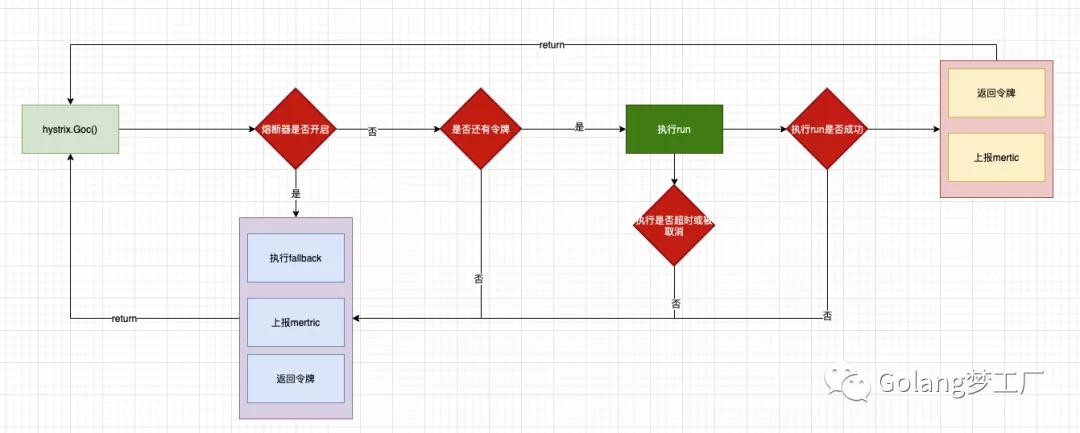
画图总结command执行流程
上面我们都是通过代码来进行分析的,看起来还是有点乱,最后画个图总结一下:
上面我们分析了整个具体流程,接下来我们针对一些核心点就行分析
上报状态事件
hystrix-go为每一个Command设置了一个默认统计控制器,用来保存熔断器的所有状态,包括调用次数、失败次数、被拒绝次数等,存储指标结构如下:
- type DefaultMetricCollector struct {
- mutex *sync.RWMutex
- numRequests *rolling.Number
- errors *rolling.Number
- successes *rolling.Number
- failures *rolling.Number
- rejects *rolling.Number
- shortCircuits *rolling.Number
- timeouts *rolling.Number
- contextCanceled *rolling.Number
- contextDeadlineExceeded *rolling.Number
- fallbackSuccesses *rolling.Number
- fallbackFailures *rolling.Number
- totalDuration *rolling.Timing
- runDuration *rolling.Timing
- }
使用rolling.Number结构保存状态指标,使用rolling.Timing保存时间指标。
最终监控上报都依靠metricExchange来实现,数据结构如下:
- type metricExchange struct {
- Name string
- Updates chan *commandExecution
- Mutex *sync.RWMutex
- metricCollectors []metricCollector.MetricCollector
- }
上报command的信息结构:
- type commandExecution struct {
- Types []string `json:"types"` // 区分事件类型,比如success、failure....
- Start time.Time `json:"start_time"` // command开始时间
- RunDuration time.Duration `json:"run_duration"` // command结束时间
- ConcurrencyInUse float64 `json:"concurrency_inuse"` // command 线程池使用率
- }
说了这么多,大家还是有点懵,其实用一个类图就能表明他们之间的关系:
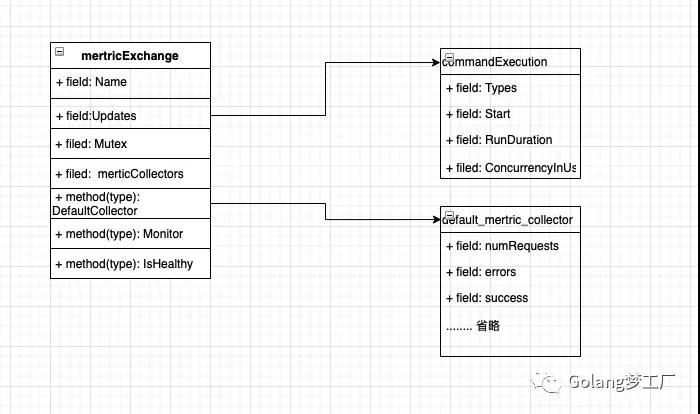
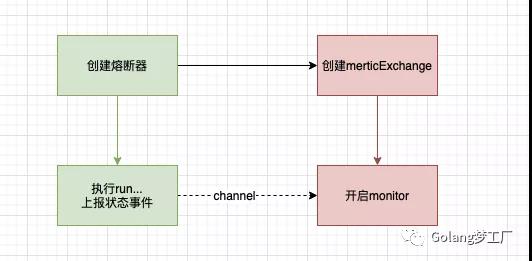
我们可以看到类mertricExchange提供了一个Monitor方法,这个方法主要逻辑就是监听状态事件,然后写入指标,所以整个上报流程就是这个样子:
流量控制
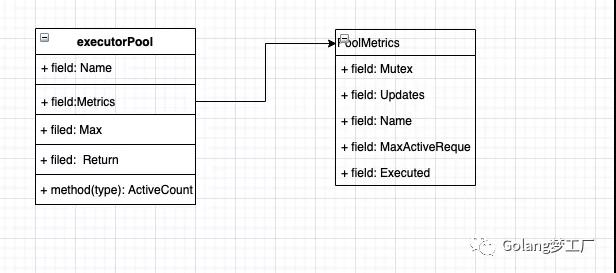
hystrix-go对流量控制采用的是令牌算法,能得到令牌的就可以执行后继的工作,执行完后要返还令牌。结构体executorPool就是hystrix-go 流量控制的具体实现。字段Max就是每秒最大的并发值。
- type executorPool struct {
- Name string
- Metrics *poolMetrics // 上报执行数量指标
- Max int // 最大并发数量
- Tickets chan *struct{} // 代表令牌
- }
这里还有一个上报指标,这个又单独实现一套方法用来统计执行数量,比如执行的总数量、最大并发数等,我们依赖画一个类图来表示:
上报执行数量逻辑与上报状态事件的逻辑是一样的,使用channel进行数据通信的,上报与返还令牌都在Return方法中:
- func (p *executorPool) Return(ticket *struct{}) {
- if ticket == nil {
- return
- }
- p.Metrics.Updates <- poolMetricsUpdate{
- activeCount: p.ActiveCount(),
- }
- p.Tickets <- ticket
- }
主要逻辑两步:
- 上报当前可用的令牌数
- 返回令牌
熔断器
我们最后来分析熔断器中一个比较重要的方法:AllowRequest,我们在执行Command是会根据这个方法来判断是否可以执行command,接下来我们就来看一下这个判断的主要逻辑:
- func (circuit *CircuitBreaker) AllowRequest() bool {
- return !circuit.IsOpen() || circuit.allowSingleTest()
- }
内部就是调用IsOpen()、allowSingleTest这两个方法:
- IsOpen()
- func (circuit *CircuitBreaker) IsOpen() bool {
- circuit.mutex.RLock()
- o := circuit.forceOpen || circuit.open
- circuit.mutex.RUnlock()
- // 熔断已经开启
- if o {
- return true
- }
- // 判断10s内的并发数是否超过设置的最大并发数,没有超过时,不需要开启熔断器
- if uint64(circuit.metrics.Requests().Sum(time.Now())) < getSettings(circuit.Name).RequestVolumeThreshold {
- return false
- }
- // 此时10s内的并发数已经超过设置的最大并发数了,如果此时系统错误率超过了预设值,那就开启熔断器
- if !circuit.metrics.IsHealthy(time.Now()) {
- //
- circuit.setOpen()
- return true
- }
- return false
- }
- allowSingleTest()
先解释一下为什么要有这个方法,还记得我们之前设置了一个熔断规则中的SleepWindow吗,如果在开启熔断的情况下,在SleepWindow时间后进行尝试,这个方法的目的就是干这个的:
- func (circuit *CircuitBreaker) allowSingleTest() bool {
- circuit.mutex.RLock()
- defer circuit.mutex.RUnlock()
- // 获取当前时间戳
- now := time.Now().UnixNano()
- openedOrLastTestedTime := atomic.LoadInt64(&circuit.openedOrLastTestedTime)
- // 当前熔断器是开启状态,当前的时间已经大于 (上次开启熔断器的时间 +SleepWindow 的时间)
- if circuit.open && now > openedOrLastTestedTime+getSettings(circuit.Name).SleepWindow.Nanoseconds() {
- // 替换openedOrLastTestedTime
- swapped := atomic.CompareAndSwapInt64(&circuit.openedOrLastTestedTime, openedOrLastTestedTime, now)
- if swapped {
- log.Printf("hystrix-go: allowing single test to possibly close circuit %v", circuit.Name)
- }
- return swapped
- }
这里只看到了熔断器被开启的设置了,但是没有关闭熔断器的逻辑,因为关闭熔断器的逻辑是在上报状态指标的方法ReportEvent内实现,我们最后再看一下ReportEvent的实现:
- func (circuit *CircuitBreaker) ReportEvent(eventTypes []string, start time.Time, runDuration time.Duration) error {
- if len(eventTypes) == 0 {
- return fmt.Errorf("no event types sent for metrics")
- }
- circuit.mutex.RLock()
- o := circuit.open
- circuit.mutex.RUnlock()
- // 上报的状态事件是success 并且当前熔断器是开启状态,则说明下游服务正常了,可以关闭熔断器了
- if eventTypes[0] == "success" && o {
- circuit.setClose()
- }
- var concurrencyInUse float64
- if circuit.executorPool.Max > 0 {
- concurrencyInUse = float64(circuit.executorPool.ActiveCount()) / float64(circuit.executorPool.Max)
- }
- select {
- // 上报状态指标,与上文的monitor呼应
- case circuit.metrics.Updates <- &commandExecution{
- Types: eventTypes,
- Start: start,
- RunDuration: runDuration,
- ConcurrencyInUse: concurrencyInUse,
- }:
- default:
- return CircuitError{Message: fmt.Sprintf("metrics channel (%v) is at capacity", circuit.Name)}
- }
- return nil
- }
可视化hystrix的上报信息
通过上面的分析我们知道hystrix-go上报了状态事件、执行数量事件,那么这些指标我们可以怎么查看呢?
设计者早就想到了这个问题,所以他们做了一个dashborad,可以查看hystrix的上报信息,使用方法只需在服务启动时添加如下代码:
- hystrixStreamHandler := hystrix.NewStreamHandler()
- hystrixStreamHandler.Start()
- go http.ListenAndServe(net.JoinHostPort("", "81"), hystrixStreamHandler)
然后打开浏览器:http://127.0.0.1:81/hystrix-dashboard,进行观测吧。
总结
故事终于接近尾声了,一个熔断机制的实现确实不简单,要考虑的因素也是方方面面,尤其在微服务架构下,熔断机制是必不可少的,不仅要在框架层面实现熔断机制,还要根据具体业务场景使用熔断机制,这些都是值得我们深思熟虑的。本文介绍的熔断框架实现的还是比较完美的,这种优秀的设计思路值得我们学习。
文中代码已上传github:https://github.com/asong2020/Golang_Dream/tree/master/code_demo/hystrix_demo,欢迎star。