本文转载自微信公众号「明哥的IT随笔」,作者IT明哥。转载本文请联系明哥的IT随笔公众号。
1 前言
大家好,我是明哥!
本文是大数据问题排查系列 的 kerberos问题排查子序列博文之一,讲述大数据集群开启 kerberos 安全认证后,hive作业执行失败的根本原因,解决方法与背后的原理和机制。 以下是正文。
2 问题现象
大数据集群开启 kerberos 安全认证后,HIVE ON SPARK 作业执行失败。通过客户端 beeline 提交作业,报错 spark client 创建失败,其报错信息是:
- Failed to create spark client for spark session xxx: java.util.concurrent.TimeoutException: client xxx timedout waiting for connection from the remote spark driver
或者是:
- Failed to create spark client for spark session xxx: java.lang.RuntimeException: spark-submit
客户端 beeline 的报错信息截图如下图所示:

error-msg-beeline1

error-msg-beeline2
3 问题分析
按照问题排查的常规思路,我们首先查看 hiveserver2 的日志,能发现核心报错信息 “Error while waiting for Remote Spark Driver to connect back to HiveServer2”,hiveserver2 的完整相关日志如下所示:
- 2021-09-02 11:01:29,496 ERROR org.apache.hive.spark.client.SparkClientImpl: [HiveServer2-Background-Pool: Thread-135]: Error while waiting for Remote Spark Driver to connect back to HiveServer2.
- java.util.concurrent.ExecutionException: java.lang.RuntimeException: spark-submit process failed with exit code 1 and error ?
- at io.netty.util.concurrent.AbstractFuture.get(AbstractFuture.java:41) ~[netty-common-4.1.17.Final.jar:4.1.17.Final]
- at org.apache.hive.spark.client.SparkClientImpl.<init>(SparkClientImpl.java:103) [hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hive.spark.client.SparkClientFactory.createClient(SparkClientFactory.java:90) [hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.RemoteHiveSparkClient.createRemoteClient(RemoteHiveSparkClient.java:104) [hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.RemoteHiveSparkClient.<init>(RemoteHiveSparkClient.java:100) [hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.HiveSparkClientFactory.createHiveSparkClient(HiveSparkClientFactory.java:77) [hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionImpl.open(SparkSessionImpl.java:131) [hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionManagerImpl.getSession(SparkSessionManagerImpl.java:132) [hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.SparkUtilities.getSparkSession(SparkUtilities.java:131) [hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.SparkTask.execute(SparkTask.java:122) [hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.Task.executeTask(Task.java:199) [hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.TaskRunner.runSequential(TaskRunner.java:97) [hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.Driver.launchTask(Driver.java:2200) [hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.Driver.execute(Driver.java:1843) [hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:1563) [hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1339) [hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1334) [hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hive.service.cli.operation.SQLOperation.runQuery(SQLOperation.java:256) [hive-service-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hive.service.cli.operation.SQLOperation.access$600(SQLOperation.java:92) [hive-service-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hive.service.cli.operation.SQLOperation$BackgroundWork$1.run(SQLOperation.java:345) [hive-service-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at java.security.AccessController.doPrivileged(Native Method) ~[?:1.8.0_201]
- at javax.security.auth.Subject.doAs(Subject.java:422) [?:1.8.0_201]
- at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1875) [hadoop-common-3.0.0-cdh6.3.2.jar:?]
- at org.apache.hive.service.cli.operation.SQLOperation$BackgroundWork.run(SQLOperation.java:357) [hive-service-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) [?:1.8.0_201]
- at java.util.concurrent.FutureTask.run(FutureTask.java:266) [?:1.8.0_201]
- at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_201]
- at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_201]
- at java.lang.Thread.run(Thread.java:748) [?:1.8.0_201]
- Caused by: java.lang.RuntimeException: spark-submit process failed with exit code 1 and error ?
- at org.apache.hive.spark.client.SparkClientImpl$2.run(SparkClientImpl.java:495) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- ... 1 more
- 2021-09-02 11:01:29,505 ERROR org.apache.hadoop.hive.ql.exec.spark.SparkTask: [HiveServer2-Background-Pool: Thread-135]: Failed to execute Spark task "Stage-1"
- org.apache.hadoop.hive.ql.metadata.HiveException: Failed to create Spark client for Spark session f43a158c-168a-4117-8993-8f1780913715_0: java.lang.RuntimeException: spark-submit process failed with exit code 1 and error ?
- at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionImpl.getHiveException(SparkSessionImpl.java:286) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionImpl.open(SparkSessionImpl.java:135) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionManagerImpl.getSession(SparkSessionManagerImpl.java:132) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.SparkUtilities.getSparkSession(SparkUtilities.java:131) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.SparkTask.execute(SparkTask.java:122) [hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.Task.executeTask(Task.java:199) [hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.TaskRunner.runSequential(TaskRunner.java:97) [hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.Driver.launchTask(Driver.java:2200) [hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.Driver.execute(Driver.java:1843) [hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:1563) [hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1339) [hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1334) [hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hive.service.cli.operation.SQLOperation.runQuery(SQLOperation.java:256) [hive-service-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hive.service.cli.operation.SQLOperation.access$600(SQLOperation.java:92) [hive-service-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hive.service.cli.operation.SQLOperation$BackgroundWork$1.run(SQLOperation.java:345) [hive-service-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at java.security.AccessController.doPrivileged(Native Method) ~[?:1.8.0_201]
- at javax.security.auth.Subject.doAs(Subject.java:422) [?:1.8.0_201]
- at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1875) [hadoop-common-3.0.0-cdh6.3.2.jar:?]
- at org.apache.hive.service.cli.operation.SQLOperation$BackgroundWork.run(SQLOperation.java:357) [hive-service-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) [?:1.8.0_201]
- at java.util.concurrent.FutureTask.run(FutureTask.java:266) [?:1.8.0_201]
- at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_201]
- at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_201]
- at java.lang.Thread.run(Thread.java:748) [?:1.8.0_201]
- Caused by: java.lang.RuntimeException: Error while waiting for Remote Spark Driver to connect back to HiveServer2.
- at org.apache.hive.spark.client.SparkClientImpl.<init>(SparkClientImpl.java:124) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hive.spark.client.SparkClientFactory.createClient(SparkClientFactory.java:90) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.RemoteHiveSparkClient.createRemoteClient(RemoteHiveSparkClient.java:104) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.RemoteHiveSparkClient.<init>(RemoteHiveSparkClient.java:100) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.HiveSparkClientFactory.createHiveSparkClient(HiveSparkClientFactory.java:77) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionImpl.open(SparkSessionImpl.java:131) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- ... 22 more
- Caused by: java.util.concurrent.ExecutionException: java.lang.RuntimeException: spark-submit process failed with exit code 1 and error ?
- at io.netty.util.concurrent.AbstractFuture.get(AbstractFuture.java:41) ~[netty-common-4.1.17.Final.jar:4.1.17.Final]
- at org.apache.hive.spark.client.SparkClientImpl.<init>(SparkClientImpl.java:103) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hive.spark.client.SparkClientFactory.createClient(SparkClientFactory.java:90) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.RemoteHiveSparkClient.createRemoteClient(RemoteHiveSparkClient.java:104) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.RemoteHiveSparkClient.<init>(RemoteHiveSparkClient.java:100) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.HiveSparkClientFactory.createHiveSparkClient(HiveSparkClientFactory.java:77) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionImpl.open(SparkSessionImpl.java:131) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- ... 22 more
- Caused by: java.lang.RuntimeException: spark-submit process failed with exit code 1 and error ?
- at org.apache.hive.spark.client.SparkClientImpl$2.run(SparkClientImpl.java:495) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- ... 1 more
- 2021-09-02 11:01:29,506 ERROR org.apache.hadoop.hive.ql.Driver: [HiveServer2-Background-Pool: Thread-135]: FAILED: Execution Error, return code 30041 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. Failed to create Spark client for Spark session f43a158c-168a-4117-8993-8f1780913715_0: java.lang.RuntimeException: spark-submit process failed with exit code 1 and error ?
- 2021-09-02 11:01:29,507 INFO org.apache.hadoop.hive.ql.Driver: [HiveServer2-Background-Pool: Thread-135]: Completed executing command(queryId=hive_20210902110125_ca2ab819-fb9c-4540-8690-2a1ed303186d); Time taken: 3.722 seconds
- 2021-09-02 11:01:29,526 ERROR org.apache.hive.service.cli.operation.Operation: [HiveServer2-Background-Pool: Thread-135]: Error running hive query:
- org.apache.hive.service.cli.HiveSQLException: Error while processing statement: FAILED: Execution Error, return code 30041 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. Failed to create Spark client for Spark session f43a158c-168a-4117-8993-8f1780913715_0: java.lang.RuntimeException: spark-submit process failed with exit code 1 and error ?
- at org.apache.hive.service.cli.operation.Operation.toSQLException(Operation.java:329) ~[hive-service-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hive.service.cli.operation.SQLOperation.runQuery(SQLOperation.java:258) ~[hive-service-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hive.service.cli.operation.SQLOperation.access$600(SQLOperation.java:92) ~[hive-service-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hive.service.cli.operation.SQLOperation$BackgroundWork$1.run(SQLOperation.java:345) [hive-service-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at java.security.AccessController.doPrivileged(Native Method) ~[?:1.8.0_201]
- at javax.security.auth.Subject.doAs(Subject.java:422) [?:1.8.0_201]
- at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1875) [hadoop-common-3.0.0-cdh6.3.2.jar:?]
- at org.apache.hive.service.cli.operation.SQLOperation$BackgroundWork.run(SQLOperation.java:357) [hive-service-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) [?:1.8.0_201]
- at java.util.concurrent.FutureTask.run(FutureTask.java:266) [?:1.8.0_201]
- at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_201]
- at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_201]
- at java.lang.Thread.run(Thread.java:748) [?:1.8.0_201]
- Caused by: org.apache.hadoop.hive.ql.metadata.HiveException: Failed to create Spark client for Spark session f43a158c-168a-4117-8993-8f1780913715_0: java.lang.RuntimeException: spark-submit process failed with exit code 1 and error ?
- at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionImpl.getHiveException(SparkSessionImpl.java:286) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionImpl.open(SparkSessionImpl.java:135) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionManagerImpl.getSession(SparkSessionManagerImpl.java:132) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.SparkUtilities.getSparkSession(SparkUtilities.java:131) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.SparkTask.execute(SparkTask.java:122) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.Task.executeTask(Task.java:199) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.TaskRunner.runSequential(TaskRunner.java:97) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.Driver.launchTask(Driver.java:2200) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.Driver.execute(Driver.java:1843) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:1563) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1339) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1334) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hive.service.cli.operation.SQLOperation.runQuery(SQLOperation.java:256) ~[hive-service-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- ... 11 more
- Caused by: java.lang.RuntimeException: Error while waiting for Remote Spark Driver to connect back to HiveServer2.
- at org.apache.hive.spark.client.SparkClientImpl.<init>(SparkClientImpl.java:124) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hive.spark.client.SparkClientFactory.createClient(SparkClientFactory.java:90) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.RemoteHiveSparkClient.createRemoteClient(RemoteHiveSparkClient.java:104) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.RemoteHiveSparkClient.<init>(RemoteHiveSparkClient.java:100) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.HiveSparkClientFactory.createHiveSparkClient(HiveSparkClientFactory.java:77) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionImpl.open(SparkSessionImpl.java:131) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionManagerImpl.getSession(SparkSessionManagerImpl.java:132) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.SparkUtilities.getSparkSession(SparkUtilities.java:131) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.SparkTask.execute(SparkTask.java:122) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.Task.executeTask(Task.java:199) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.TaskRunner.runSequential(TaskRunner.java:97) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.Driver.launchTask(Driver.java:2200) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.Driver.execute(Driver.java:1843) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:1563) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1339) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1334) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hive.service.cli.operation.SQLOperation.runQuery(SQLOperation.java:256) ~[hive-service-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- ... 11 more
- Caused by: java.util.concurrent.ExecutionException: java.lang.RuntimeException: spark-submit process failed with exit code 1 and error ?
- at io.netty.util.concurrent.AbstractFuture.get(AbstractFuture.java:41) ~[netty-common-4.1.17.Final.jar:4.1.17.Final]
- at org.apache.hive.spark.client.SparkClientImpl.<init>(SparkClientImpl.java:103) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hive.spark.client.SparkClientFactory.createClient(SparkClientFactory.java:90) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.RemoteHiveSparkClient.createRemoteClient(RemoteHiveSparkClient.java:104) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.RemoteHiveSparkClient.<init>(RemoteHiveSparkClient.java:100) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.HiveSparkClientFactory.createHiveSparkClient(HiveSparkClientFactory.java:77) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionImpl.open(SparkSessionImpl.java:131) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionManagerImpl.getSession(SparkSessionManagerImpl.java:132) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.SparkUtilities.getSparkSession(SparkUtilities.java:131) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.spark.SparkTask.execute(SparkTask.java:122) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.Task.executeTask(Task.java:199) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.exec.TaskRunner.runSequential(TaskRunner.java:97) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.Driver.launchTask(Driver.java:2200) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.Driver.execute(Driver.java:1843) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:1563) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1339) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1334) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- at org.apache.hive.service.cli.operation.SQLOperation.runQuery(SQLOperation.java:256) ~[hive-service-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- ... 11 more
- Caused by: java.lang.RuntimeException: spark-submit process failed with exit code 1 and error ?
- at org.apache.hive.spark.client.SparkClientImpl$2.run(SparkClientImpl.java:495) ~[hive-exec-2.1.1-cdh6.3.2.jar:2.1.1-cdh6.3.2]
- ... 1 more
- 2021-09-02 11:01:29,552 INFO org.apache.hadoop.hive.conf.HiveConf: [HiveServer2-Handler-Pool: Thread-128]: Using the default value passed in for log id: f43a158c-168a-4117-8993-8f1780913715
但是因为 “Error while waiting for Remote Spark Driver to connect back to HiveServer2” 造成 “Failed to create spark client for spark session xxx:” 的根本原因,相对难发现,因为在hiveserver2的日志,hive on spark 作业的日志 (通过yarn logs -applicationId xx 查看),甚至yarn的日志中,都找不到明显的相关信息;
4 问题原因
进一步排查问题,需要 在理解作业的底层执行机制的基础上, 大胆猜想,小心求证。
HIVE 作业的执行机制如下:
- 终端业务用户比如 xyz 提交给 HIVESERVER2 的 SQL作业,经过 HIVESERVER2 的解析编译和优化后,一般会生成 MR/TEZ/SPARK 任务(之所以说一般,是因为有的 SQL 是直接在HIVESERVER2中执行的,不会生成分布式的 MR/TEZ/SPARK 任务),这些 MR/TEZ/SPARK 任务最终访问底层的基础设施 HDFS 和 YARN 时,一样要经过 kerberos 安全认证;
- 当启用了 HIVE 的代理机制时(hive.server.enable.doAs=true),业务终端用户如 xyz 提交的 HIVE SQL 作业底层的 MR/TEZ/SPARK 任务访问 HDFS/YARN 时,HDFS/YARN 验证的是业务终端用户 xyz 的身份 (后续 HDFS/YARN 的权限校验,校验的也是 xyz 用户的权限);
- 当没有启用 HIVE 的代理机制时(hive.server.enable.doAs=false),业务终端用户提交的 HIVE SQL 作业底层的 MR/TEZ/SPARK 任务访问 HDFS/YARN 时,需要验证的是 hiveserver2 服务对应的用户,即 hive 的身份 (后续 HDFS/YARN 的权限校验,校验的也是 hive 用户的权限);
至此问题就比较清晰了:
- 在上述集群环境中,cdh 集群管理员开启了 kerberos 安全认证,即集群中 hdfs/yarn/hive/spark/kafka 等服务的使用,都需要经过kerberso 安全认证;
- 当 hiveserver2 执行业务用户提交的 sql 作业时,由于业务用户配置了使用 spark 执行引擎,所以 hiveserver2 需要首先为业务用户用户创建 spark 集群;
- 在上述集群环境中,cdh 集群管理员开启了 hive.server.enable.doAs=true,所以 hiveserver2 创建 spark集群时,spark 集群的 driver 向 yarn 申请资源时,yarn 校验的是 xyz 的身份;
- 由于 hiveserver2 没有提供一致机制将业务用户 xyz的 principal 和对应的 keytab 透传到 yarn, 所以 yarn 对 xyz 的用户认证失败,没有相应其资源请求,从而 spark driver 因获取不到 yarn资源无法成功启动,自然也就不会回连到spark driver的客户端即hiveserver2,所以才有相关报错:"Failed to create spark client for spark session xxx“,“Error while waiting for Remote Spark Driver to connect back to HiveServer2”等。
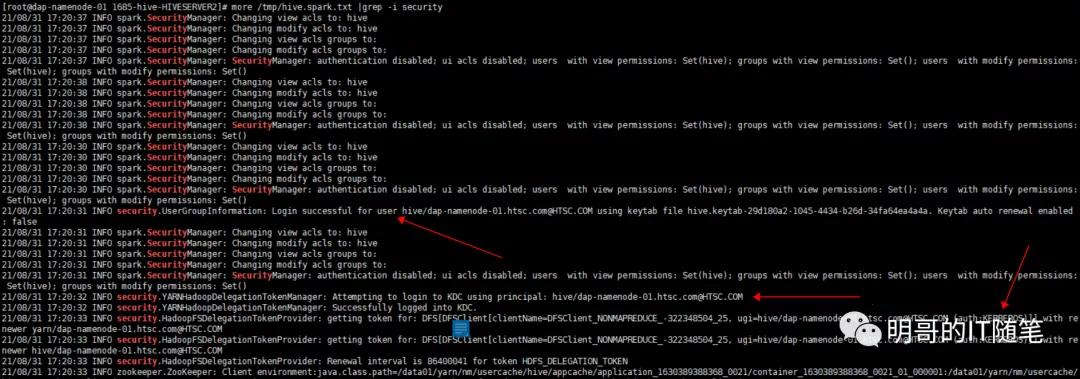
事实上,细心的小伙伴,能在 hiveserver2 的日志中,查看到 securityManager 验证用户身份的相关日志:
同样的,细心的小伙伴,能在 hiveserver2 的日志中,查看到 hive 启动 spark on yarn 集群的相关日志:
- 2021-09-02 14:19:10,067 INFO org.apache.hive.spark.client.SparkClientImpl: [HiveServer2-Background-Pool: Thread-110]: Running client driver with argv: kinit hive/uf30-1@CDH.COM -k -t hive.keytab; /opt/cloudera/parcels/CDH-6.3.2-1
- .cdh6.3.2.p0.1605554/lib/spark/bin/spark-submit --executor-cores 4 --executor-memory 6442450944b --proxy-user dap --jars /opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/hive-kryo-registrator-2.1.1-cdh6.3.2.jar --propert
- ies-file /tmp/spark-submit.7174671910364719325.properties --class org.apache.hive.spark.client.RemoteDriver /opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/hive-exec-2.1.1-cdh6.3.2.jar --remote-host uf30-1 --remote-port
- 39677 --remote-driver-conf hive.spark.client.future.timeout=60000 --remote-driver-conf hive.spark.client.connect.timeout=1000 --remote-driver-conf hive.spark.client.server.connect.timeout=90000 --remote-driver-conf hive.spark.cli
- ent.channel.log.level=null --remote-driver-conf hive.spark.client.rpc.max.size=52428800 --remote-driver-conf hive.spark.client.rpc.threads=8 --remote-driver-conf hive.spark.client.secret.bits=256 --remote-driver-conf hive.spark.cl
- ient.rpc.server.address=null --remote-driver-conf hive.spark.client.rpc.server.port=null
5 问题解决
知道了问题的根本原因,问题的解决也就顺理成章了。 有两个解决办法:
- 关闭集群的 kerberos 安全认证,此时向 yarn 申请资源时,yarn 不再需要验证用户的身份,hive sql 作业不管再底层用什么身份执行,都不会有用户身份认证问题;(当然,用户权限问题是另一回事);
- 保留集群的 kerberos 安全认证,但关闭 hive的代理功能,即hive.server2.enable.doAs=false:此时 hive 可以使用各种认证方式(hive.server2.authentication= none/ldap/kerberos), 各个业务用户正常提交 HIVE SQL 作业给 HIVESERVER2 并可配置使用 MR/TEZ/SPARK 任一执行引擎,HIVESERVER2 经解析编译优化生成 MR/TEZ/SPARK任务后,会以 hive 用户身份跟 yarn/hdfs 进行交互和身份认证,由于集群已经配好了 HIVE 用户的相关配置(其实底层是在 hive-site.xml 中配置好了 hive 这个用户的 principal 和对应的keytab文件,所以 hive 用户跟 hdfs/yarn的交互和认证都没有问题),所以此时 hivesql 作业可以提交执行。
6 知识总结
- hive 可以配置使用各种认证方式 (hive.server2.authentication= none/ldap/kerberos);
- hive 可以配置使用各种执行引擎 (hive.execution.engine= mr/tez/spark);
- hive 有代理功能,可以开启也可以关闭:hive.server2.enable.doAs=false/TRUE,"Setting this property to true will have HiveServer2 execute Hive operations as the user making the calls to it." (一些安全插件如 SENTRY/RANGER 要求关闭该功能);
- 终端业务用户比如 xyz 提交给 HIVESERVER2 的 SQL作业,经过 HIVESERVER2 的解析编译和优化后,一般会生成 MR/TEZ/SPARK 任务(之所以说一般,是因为有的 SQL 是直接在HIVESERVER2中执行的,不会生成分布式的 MR/TEZ/SPARK 任务),这些 MR/TEZ/SPARK 任务最终访问底层的基础设施 HDFS 和 YARN 时,一样要经过这些基础设施 hdfs/yarn的 安全认证;
- 当启用了 HIVE 的代理机制时(hive.server.enable.doAs=true),业务终端用户如 xyz 提交的 HIVE SQL 作业底层的 MR/TEZ/SPARK 任务访问 HDFS/YARN 时,HDFS/YARN 验证的是业务终端用户 xyz 的身份 (后续 HDFS/YARN 的权限校验,校验的也是 xyz 用户的权限);
- 当没有启用 HIVE 的代理机制时(hive.server.enable.doAs=false),业务终端用户提交的 HIVE SQL 作业底层的 MR/TEZ/SPARK 任务访问 HDFS/YARN 时,需要验证的是 hiveserver2 服务对应的用户,即 hive 的身份 (后续 HDFS/YARN 的权限校验,校验的也是 hive 用户的权限);
- 当我们说启用大数据集群的 kerberos 安全认证,一般是整个集群层面的各个服务,都启用 kerberos 安全认证:因为当底层的基础设施 hdfs/yarn 启用 kerberos 安全认证后,任何和 hdfs/yarn 交互的组件,都需要经过 kerberos 安全认证;
- 发行版的大数据集群如 CDH 一般都已经配好了 HIVE 用户的相关 kerberos 安全配置,其实底层是在 hive-site.xml 中配置好了 hive 这个用户的 principal 和对应的keytab文件,所以 hive 用户跟 hdfs/yarn的交互和认证都没有问题;