












1.序篇-本文结构
前面的章节铺垫了那么多,终于在本节走入一条 query 了。
针对 datastream api 大家都比较熟悉了,还是那句话,在 datastream 中,你写的代码逻辑是什么样的,它最终的执行方式就是什么样的。
但是对于 flink sql 的执行过程,大家还是不熟悉的。
因此本文通过以下章节使用 ETL,group agg(sum,count等)简单聚合类 query 带大家走进一条 flink sql query 逻辑的世界。帮大家至少能够熟悉在 flink sql 程序运行时知道 flink 程序在干什么。
- 背景篇-大家不了解 flink sql 什么?
- 目标篇-本文能帮助大家了解 flink sql 什么?
- 实战篇-简单的 query 案例和运行原理
- 总结与展望篇
先说说结论:
场景问题:flink sql 很适合简单 ETL,以及基本全部场景下的聚合类指标。
语法问题:flink sql 语法其实是和其他 sql 语法基本一致的。基本不会产生语法问题阻碍使用 flink sql。
运行问题:查看 flink sql 任务时的一些技巧:
- 去 flink webui 看看这个任务目前在做什么。包括算子名称都会给直接展示给我们目前哪个算子在干啥事情,在处理啥逻辑。
- 如果你想知道你的 flink 任务执行了什么代码,就去看看 sql 最后转换成的 transformation 里面具体要执行哪些操作。flink sql 生成的代码也在里面。
- 如果你不确定线上任务执行原理,可以直接在本地尝试运行。
2.背景篇-大家不了解 flink sql 什么?
首先从大家用 flink sql 的一个初衷和状态出发,想一下大家在开始上手 flink sql 时,是什么样的一个想法?
博主大概整理了下,在初步上手 flink sql,一般从入手到踩坑整个过程中,一般都会有以下几种问题或者想法:
- 场景问题:首先 flink sql 是用来提效的,那相比 datastream,哪些场景很适合 flink sql 去做?
- 语法问题:我写 sql 时 flink sql 语法会不会和其他 sql 语法有不同?
- 运行问题:我写了一条 sql,运行起来了,但是对我来说是黑盒的,我怎么知道这个任务正在执行什么操作?有没有什么好办法帮我去理解 flink sql 的运行机制?
- 理解误区:在理解 flink sql 的运算机制上有哪些误区?
- 坑:flink sql 一般都有啥坑?提前了解帮我们避免踩坑。
就是上面这些想法,会让很多想在公司内部引入 flink sql 的同学望而却步。
3.目标篇-本文能帮助大家了解 flink sql 什么?
来看看本文的目标:
- 场景问题:帮大家理解哪些场景是非常适合 flink sql 的
- 语法问题:帮大家简单熟悉 flink sql 的语法
- 运行问题:使用一条简单的 query sql 看看其运行起来的过程,其运行的机制
- 理解误区:运算机制上的常见误区
- 坑:看看 sql 一般会有啥坑
由于一篇文章不能覆盖所有概念,本文主要介绍一些最简单的 ETL,聚合场景,主要集中于前三点。
后两点在后续系列文章中会按照场景详细展开。
4.实战篇-简单的 query 案例和运行原理
4.1.场景问题:有哪些场景适合 flink sql?
不装了,我坦白了,flink sql 其实很适合干的活就是 dwd 清洗,dws 聚合。
此处主要针对实时数仓的场景来说。flink sql 能干 dwd 清洗,dws 聚合,基本上实时数仓的大多数场景都能给覆盖了。
flink sql 牛逼!!!
但是!!!
经过博主使用 flink sql 经验来看,并不是所有的 dwd,dws 聚合场景都适合 flink sql(截止发文阶段来说)!!!
其实这些目前不适合 flink sql 的场景总结下来就是在处理上比 datastream 还是会有一定的损失。
先总结下使用场景:
1. dwd:简单的清洗、复杂的清洗、维度的扩充、各种 udf 的使用
2. dws:各类聚合
然后分适合的场景和不适合的场景来说,因为只这一篇不能覆盖所有的内容,所以本文此处先大致给个结论,之后会结合具体的场景详细描述。
适合的场景:
简单的 dwd 清洗场景
全场景的 dws 聚合场景
目前不太适合的场景:
复杂的 dwd 清洗场景:举例比如使用了很多 udf 清洗,尤其是使用很多的 json 类解析清洗
关联维度场景:举例比如 datastream 中经常会有攒一批数据批量访问外部接口的场景,flink sql 目前对于这种场景虽然有 localcache、异步访问能力,但是依然还是一条一条访问外部缓存,这样相比批量访问还是会有性能差距。
4.2.语法\运行问题
其实总结来说,对于接触过 sql 的同学来说,除了 flink sql 中窗口聚合类的写法来说,其他的 sql 语法都是相同的,很容易理解。
本节会针对具体的案例进行详细介绍。
4.2.1.ETL
最简单的 ETL 类型任务。
SELECT select_list FROM table_expression [ WHERE boolean_expression ]
- 1.
1.场景:简单的 dwd 清洗过滤场景
源码公众号后台回复不会连最适合 flink sql 的 ETL 和 group agg 场景都没见过吧获取。
数据源表:
CREATE TABLE source_table (
order_number BIGINT,
price DECIMAL(32,2)
) WITH (
'connector' = 'datagen',
'rows-per-second' = '10',
'fields.order_number.min' = '10',
'fields.order_number.max' = '11'
)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
数据汇表:
CREATE TABLE sink_table (
order_number BIGINT,
price DECIMAL(32,2)
) WITH (
'connector' = 'print'
)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
ETL 逻辑:
insert into sink_table
select * from source_table
where order_number = 10
- 1.
- 2.
- 3.
2.运行:可以看到,其实在 flink sql 任务中,其会把对应的处理逻辑给写到算子名称上面。
Notes - 观察 flink sql 技巧 1:这个其实就是我们观察 flink sql 任务的第一个技巧。如果你想知道你的 flink 任务在干啥,第一反应是去 flink webui 看看这个任务目前在做什么。包括算子名称都会给直接展示给我们目前哪个算子在干啥事情,在处理啥逻辑
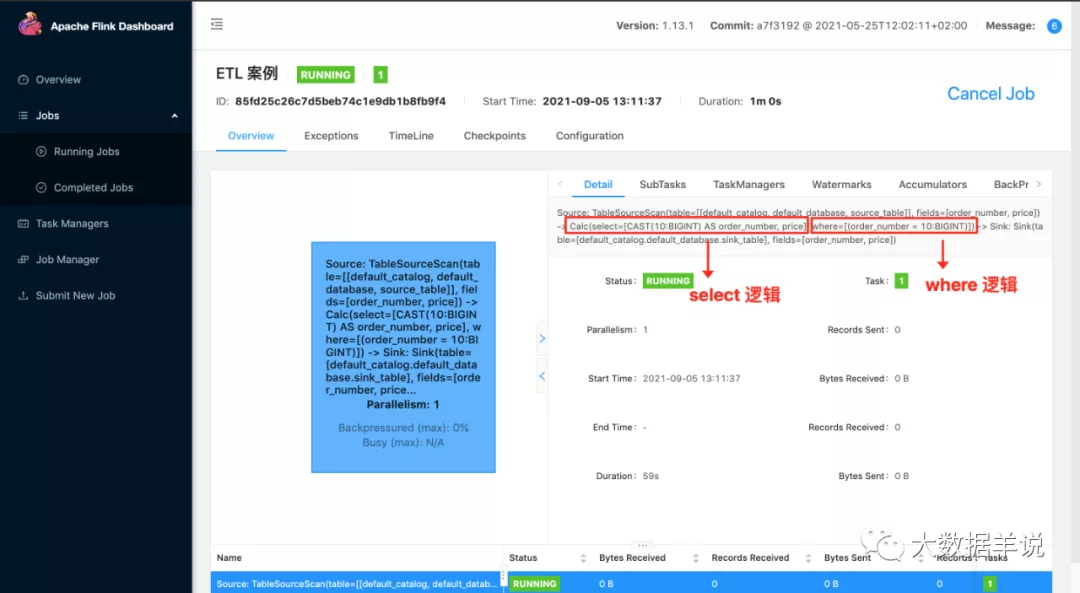
3.结果
+I[10, 337546916355686018150362513408.00]
+I[10, 734895198061906189720381030400.00]
+I[10, 496632591763800912960818249728.00]
+I[10, 495090465926828588045441171456.00]
+I[10, 167305033642317182838130081792.00]
+I[10, 409466913112794578407573684224.00]
+I[10, 894352160414515330502514180096.00]
+I[10, 680063350384451712068576346112.00]
+I[10, 50807402446574997641386524672.00]
+I[10, 646597093362022945955245981696.00]
+I[10, 233317961584082024331537809408.00]
...
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
4.原理:
先看一下一个 flink sql 任务的入口执行逻辑。
首先看看建表语句的执行和 query 语句执行的逻辑有什么不同。
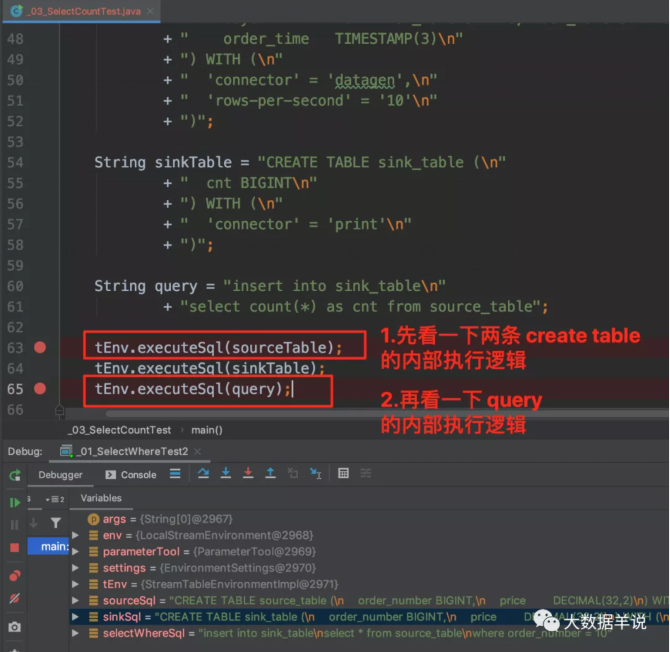
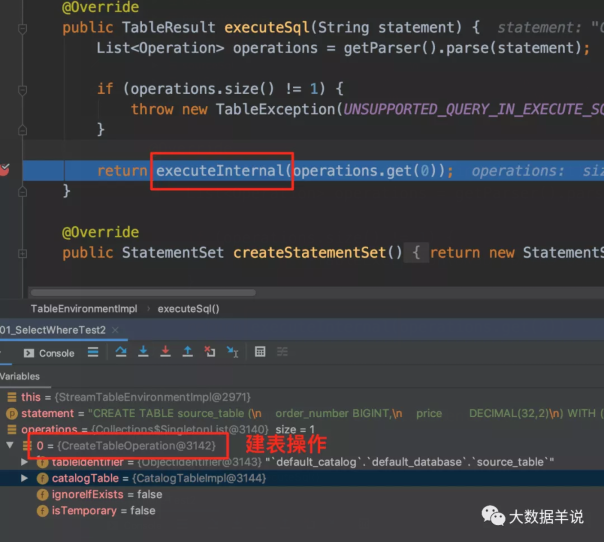
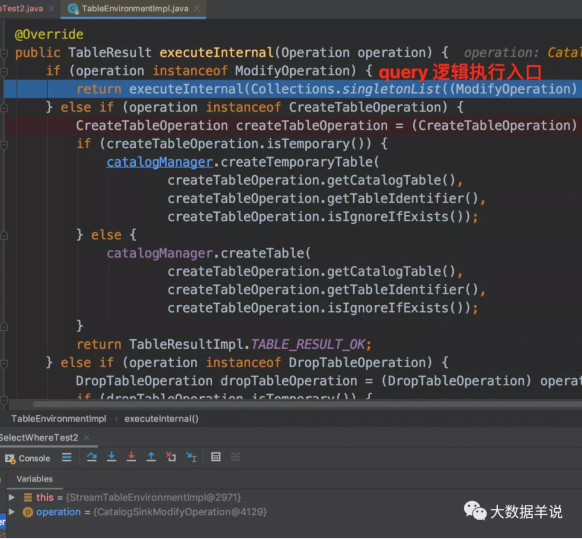
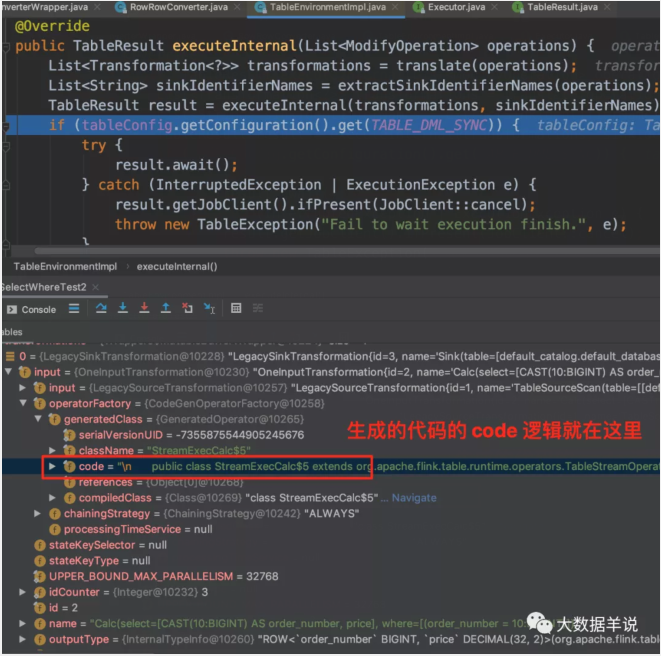
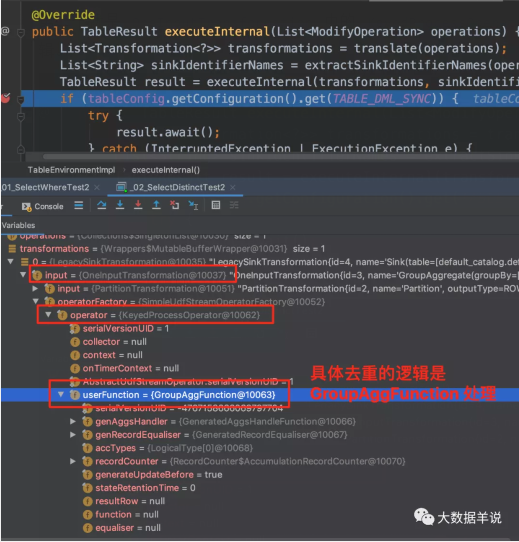
可以发现执行到 executeInternal 时会针对具体的 operation 来执行不同的操作。
执行建表操作就是具体的 CreateTableOperation 时,会将表的信息保存到 catalogManager。
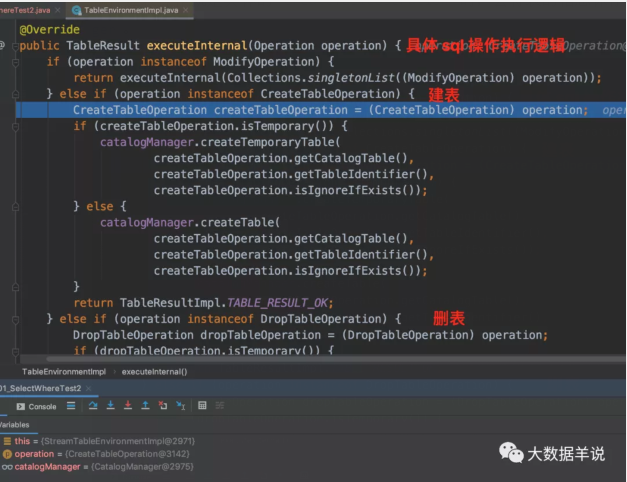
执行 query 操作就是具体的 ModifyOperation 时,会将对应的逻辑转换成对应的 Transformation。
Transformation 中就包含了执行的整体逻辑以及对应要执行的 sql 代码内容。
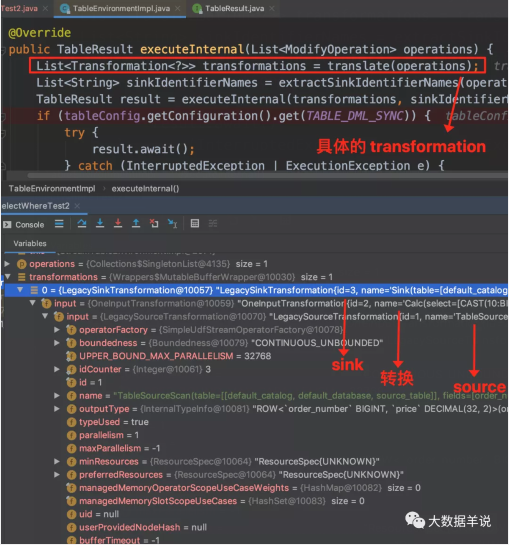
接下来我们详细看下对应的 transform 中包含了什么内容。
首先是最外层 LegacySinkTransformation,即 sink 算子,如图就是 print sink function。比较好理解。
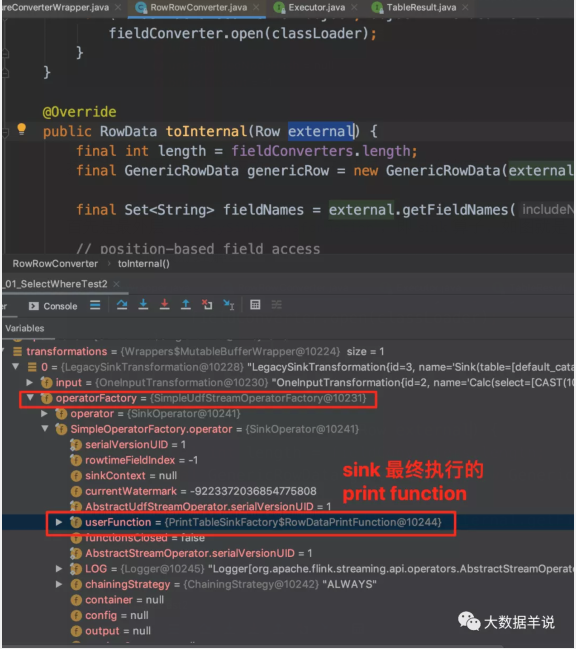
然后是中间层 OneInputTransformation,即 sql 中过滤和转换操作(select * from source_table where order_number = 10),如图是代码生成的具体过滤和转换逻辑。
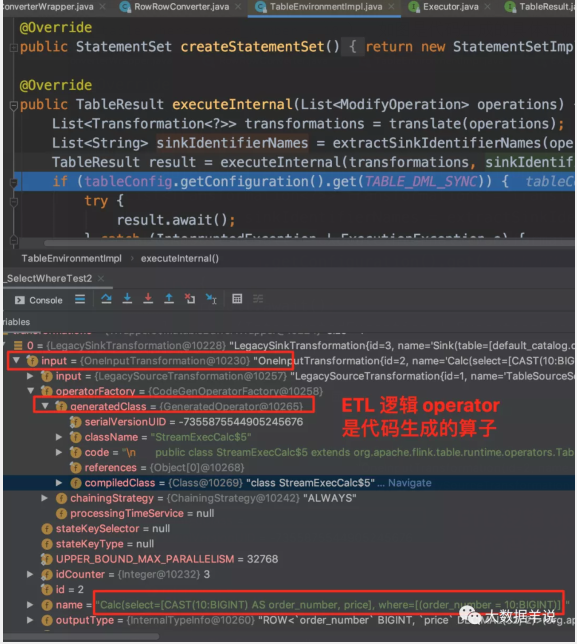
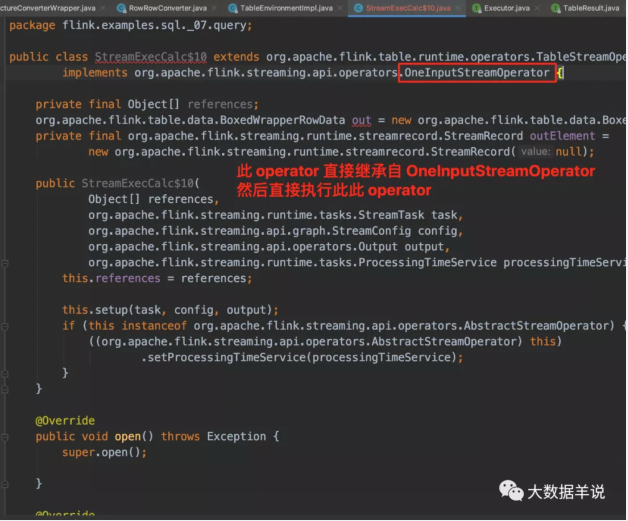
生成的代码就在 GeneratedOperator 中的 code 字段。我们将对应的 code 复制到一个新的文件夹中。
这个算子是直接继承了 OneInputStreamOperator 进行直接执行逻辑,跳过了 datastream 那一层。
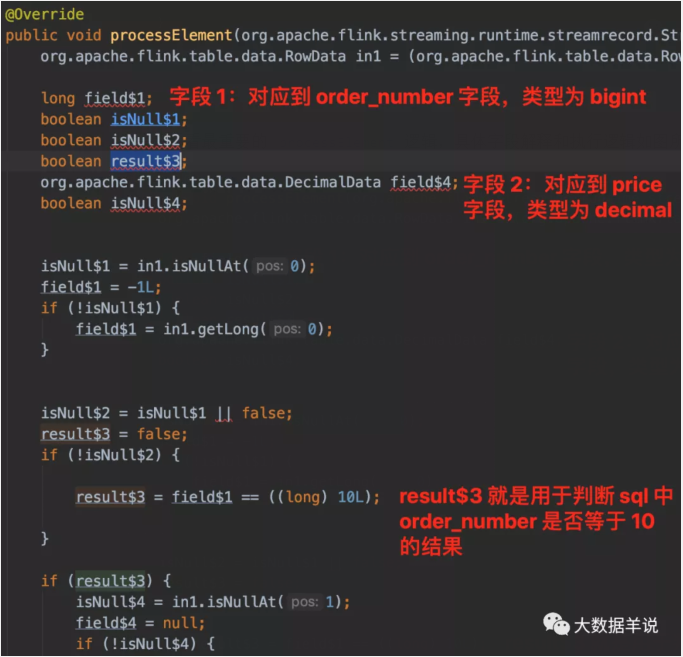
我们来看看最重要的 processElement 逻辑,具体字段解释和执行逻辑如图所示。
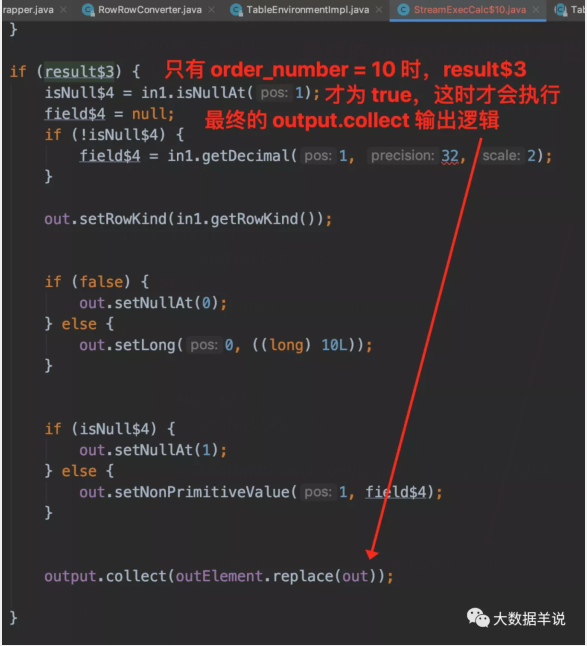
Notes - 观察 flink sql 技巧 2:这个其实就是我们观察 flink sql 任务的第二个技巧。如果你想知道你的 flink 任务执行了什么代码,就去看看 sql 最后转换成的 transformation 里面具体要执行哪些操作。
4.2.2.去重场景
1.场景:最简单的去重场景
源码公众号后台回复不会连最适合 flink sql 的 ETL 和 group agg 场景都没见过吧获取。
数据源:
CREATE TABLE source_table (
string_field STRING
) WITH (
'connector' = 'datagen',
'rows-per-second' = '10',
'fields.string_field.length' = '3'
)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
数据汇:
CREATE TABLE sink_table (
string_field STRING
) WITH (
'connector' = 'print'
)
- 1.
- 2.
- 3.
- 4.
- 5.
数据处理:
insert into sink_table
select distinct string_field
from source_table
- 1.
- 2.
- 3.
2.运行:可以看到,其实在 flink sql 任务中,其会把对应的处理逻辑给写到算子名称上面。
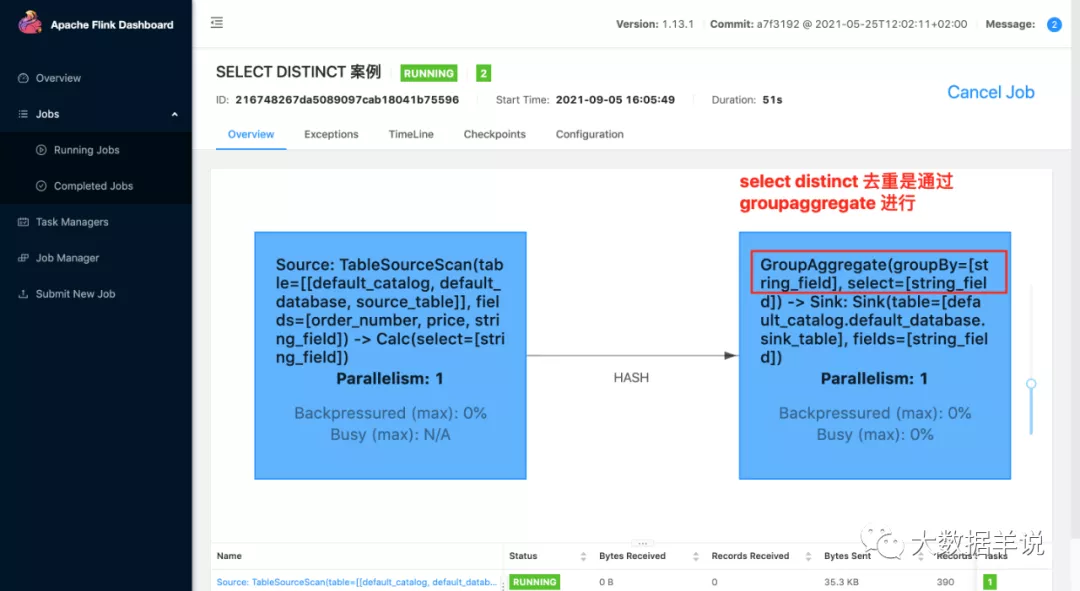
3.上面这个案例的结果:
+I[cd3]
+I[8fc]
+I[b0c]
+I[1d8]
+I[e28]
+I[c5f]
+I[e7d]
+I[dfa]
+I[1fe]
...
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
4.原理:
此处我们只关注和上面不同的逻辑。
第一个就是 PartitionTransform 中的 KeyGroupStreamPartitioner,就是对应的分区逻辑。来看看生成代码的逻辑。
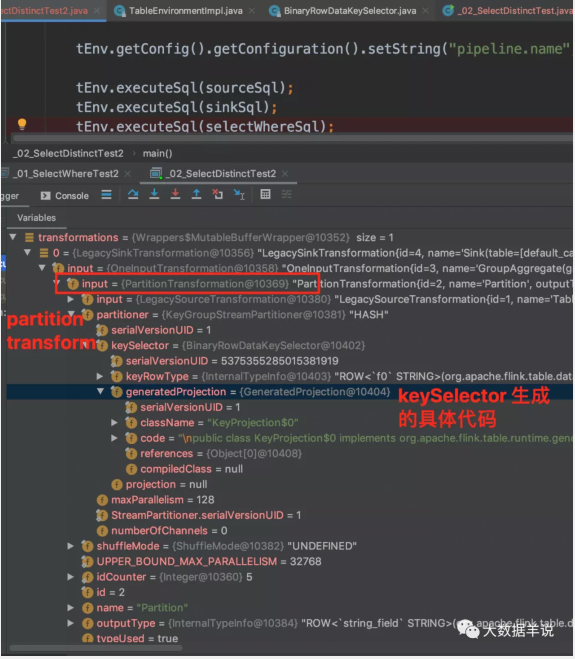
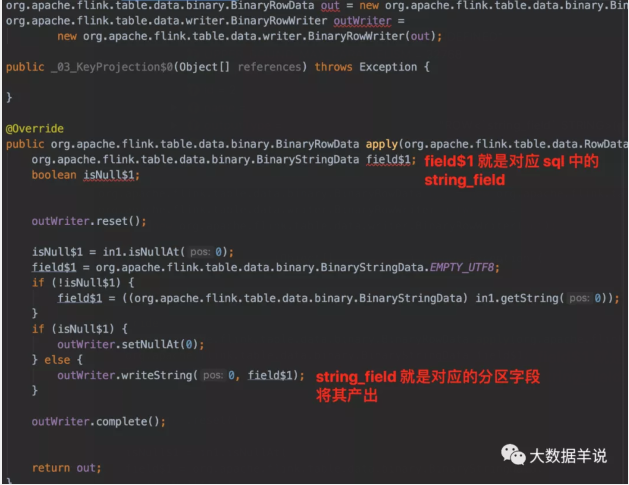
其中做 shuffle 逻辑时,是按照 string_field 作为 key 进行 shuffle。
第二个就是 OneInputTransformation 中的 KeyedProcessOperator,就是对应的去重逻辑。
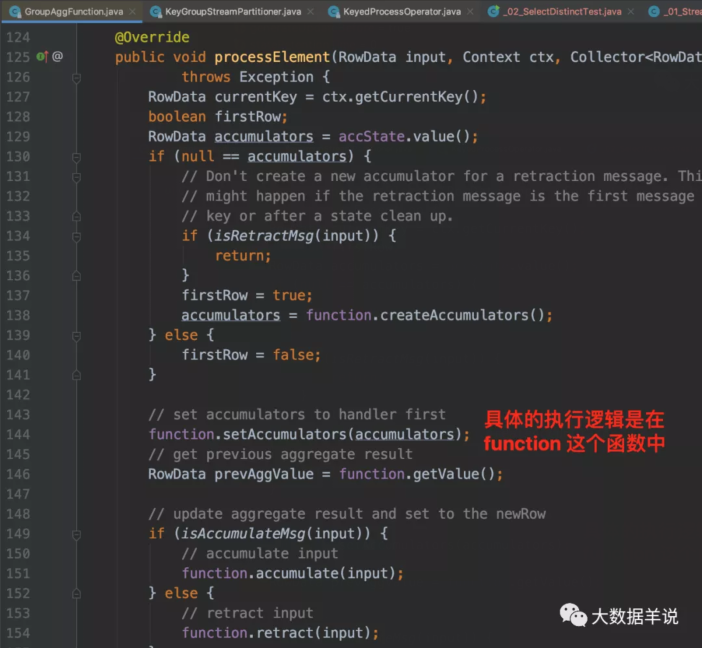
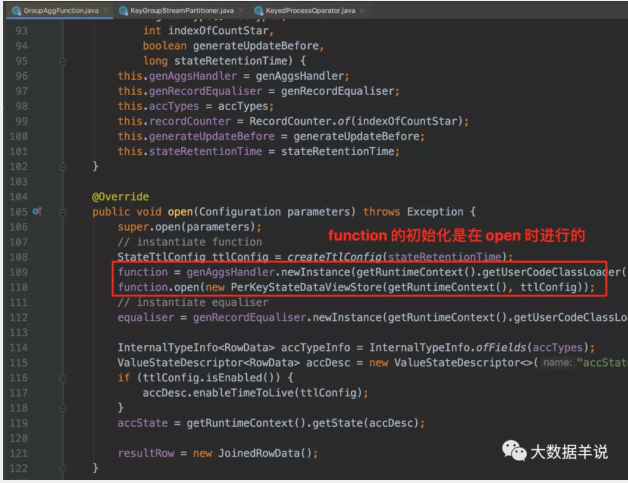
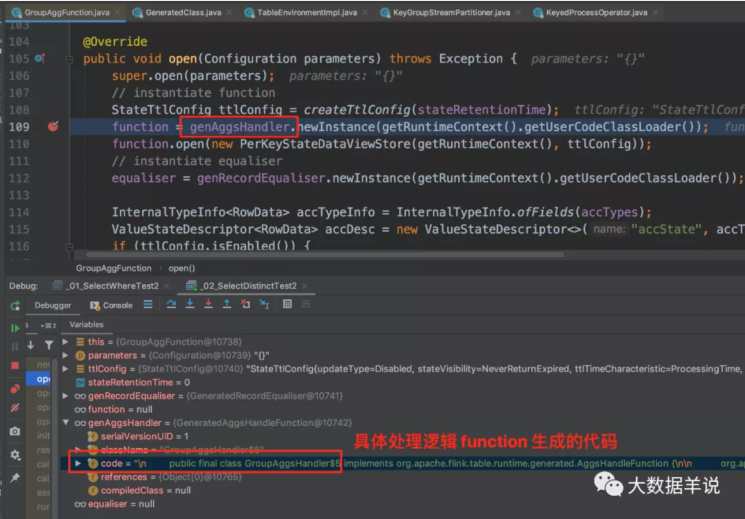
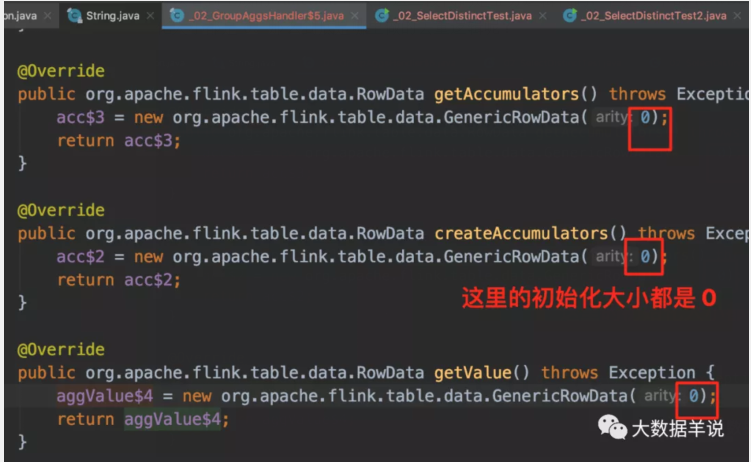
可以看到生成的 function 中只有这三段代码是业务逻辑代码,但是其中的 RowData 初始化大小都是 0。那么到底是哪里做的去重逻辑呢?
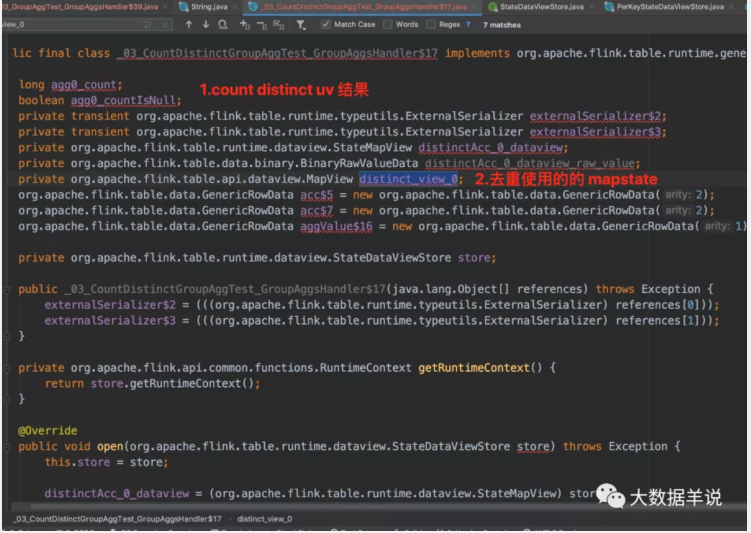
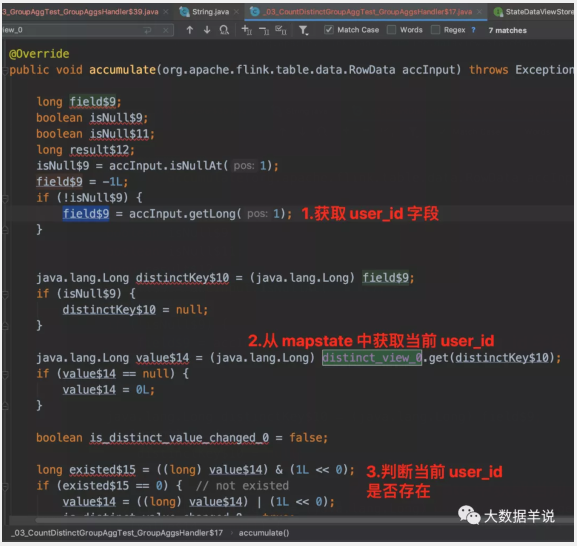
我们跟一下处理逻辑会发现。去重逻辑主要集中在 GroupAggFunction#processElement。
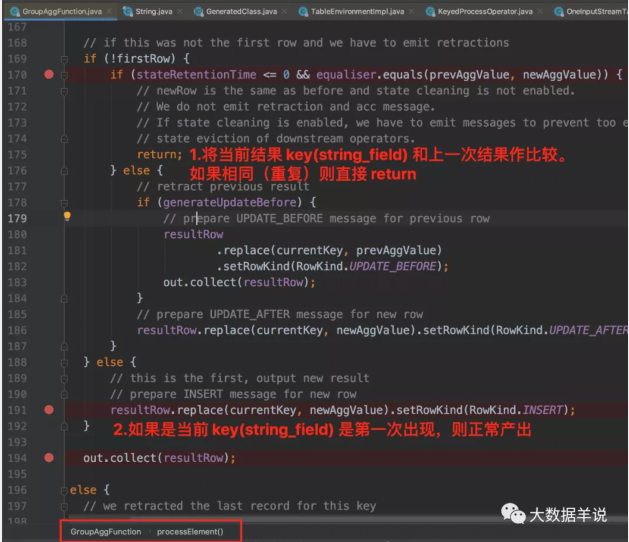
4.2.3.group 聚合场景
4.2.3.1.简单聚合场景
1.场景:最简单的聚合场景
源码公众号后台回复不会连最适合 flink sql 的 ETL 和 group agg 场景都没见过吧获取。
count,sum,avg,max,min 等:
数据源:
CREATE TABLE source_table (
order_id STRING,
price BIGINT
) WITH (
'connector' = 'datagen',
'rows-per-second' = '10',
'fields.order_id.length' = '1',
'fields.price.min' = '1',
'fields.price.max' = '1000000'
)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
数据汇:
CREATE TABLE sink_table (
order_id STRING,
count_result BIGINT,
sum_result BIGINT,
avg_result DOUBLE,
min_result BIGINT,
max_result BIGINT
) WITH (
'connector' = 'print'
)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
数据处理逻辑:
insert into sink_table
select order_id,
count(*) as count_result,
sum(price) as sum_result,
avg(price) as avg_result,
min(price) as min_result,
max(price) as max_result
from source_table
group by order_id
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
2.运行:
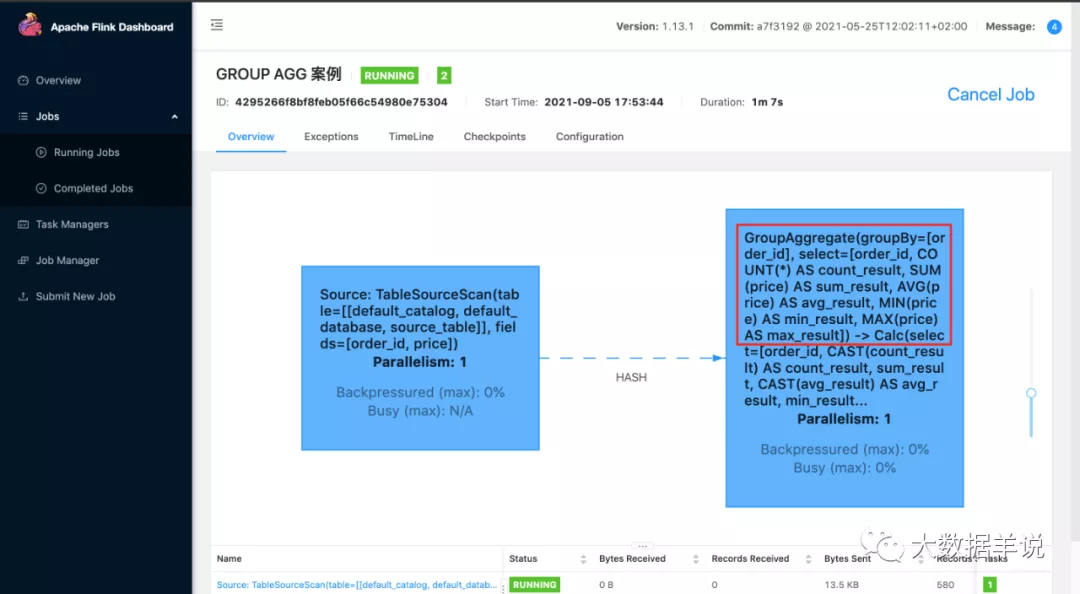
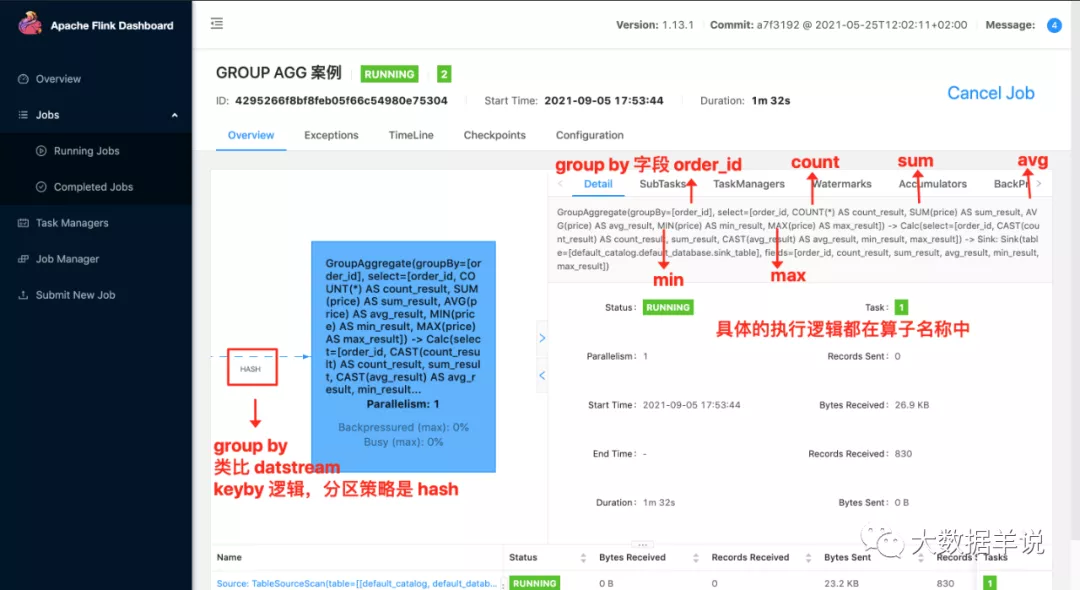
3.上面这个案例的结果:
+I[1, 1, 415300, 415300.0, 415300, 415300]
+I[d, 1, 416878, 416878.0, 416878, 416878]
+I[0, 1, 120837, 120837.0, 120837, 120837]
+I[c, 1, 337749, 337749.0, 337749, 337749]
+I[7, 1, 387053, 387053.0, 387053, 387053]
+I[8, 1, 387042, 387042.0, 387042, 387042]
+I[2, 1, 546317, 546317.0, 546317, 546317]
+I[e, 1, 22131, 22131.0, 22131, 22131]
+I[9, 1, 651731, 651731.0, 651731, 651731]
-U[0, 1, 120837, 120837.0, 120837, 120837]
+U[0, 2, 566664, 283332.0, 120837, 445827]
+I[b, 1, 748659, 748659.0, 748659, 748659]
-U[7, 1, 387053, 387053.0, 387053, 387053]
+U[7, 2, 1058056, 529028.0, 387053, 671003]
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
4.原理:
来瞅一眼 transformation。
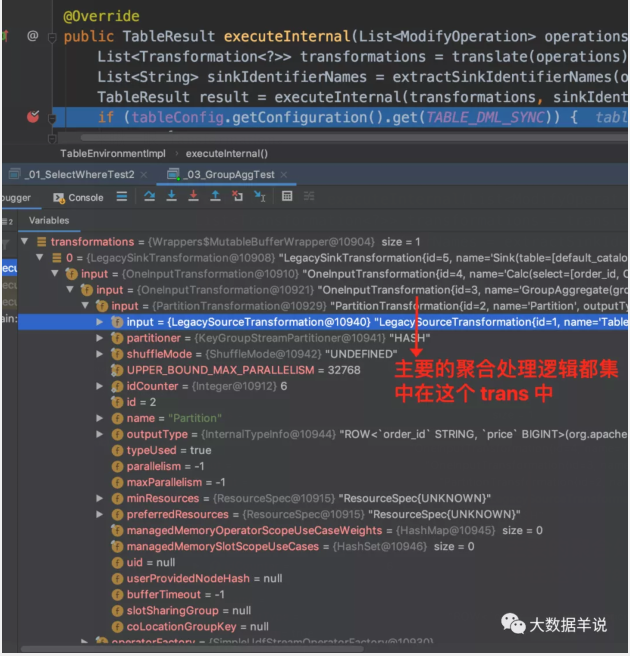
还是和之前的逻辑一样,跟一下 GroupAggFunction 的逻辑。如下图,有五个执行步骤执行计算。
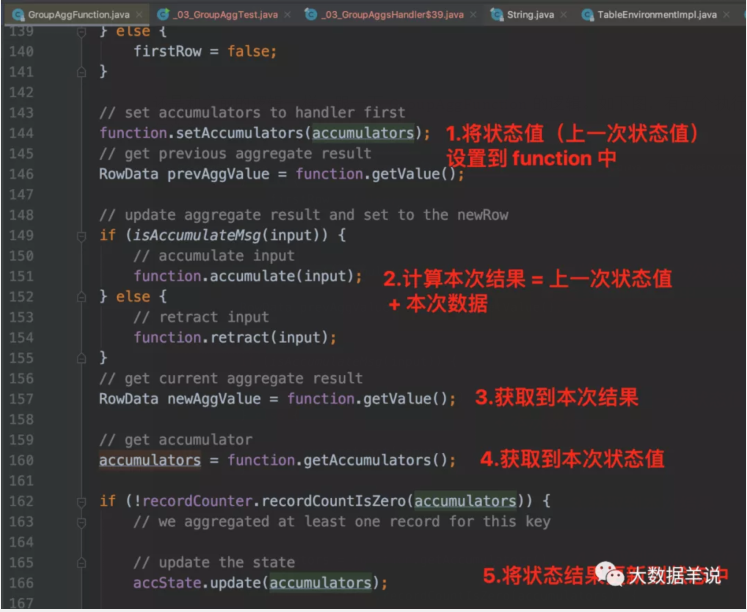
再看最终生成的 function 代码逻辑。
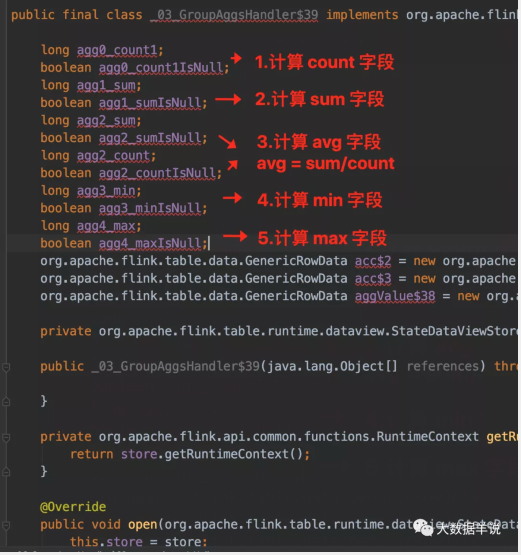
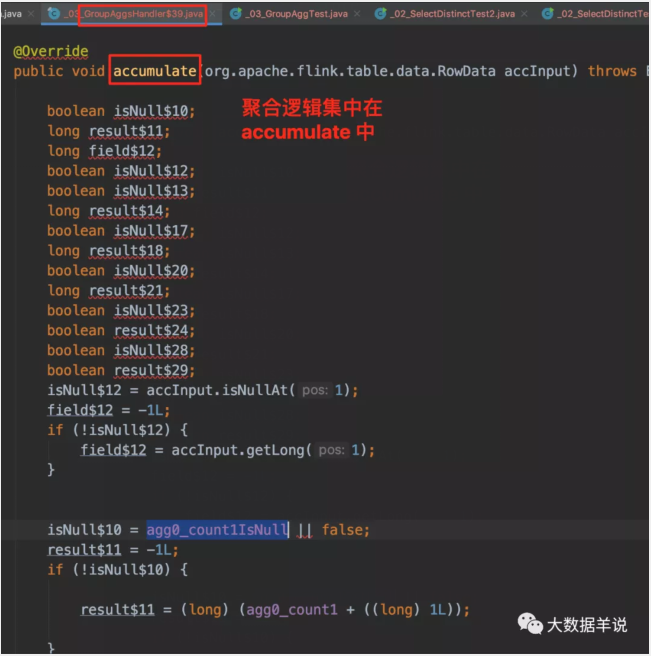
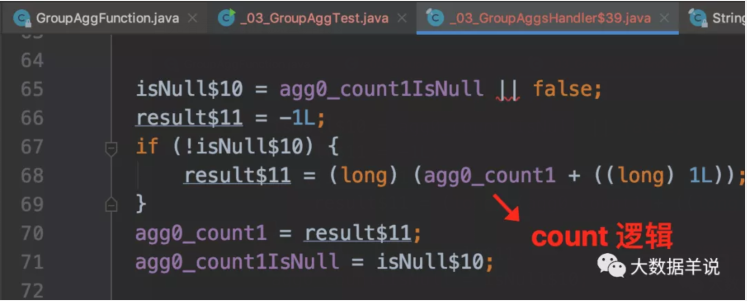
首先看看 count 怎么算的。
sum 怎么算的。

4.2.3.2.去重聚合场景
1.场景:去重聚合场景
数据源:
CREATE TABLE source_table (
dim STRING,
user_id BIGINT
) WITH (
'connector' = 'datagen',
'rows-per-second' = '10',
'fields.dim.length' = '1',
'fields.user_id.min' = '1',
'fields.user_id.max' = '1000000'
)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
数据汇:
CREATE TABLE sink_table (
dim STRING,
uv BIGINT
) WITH (
'connector' = 'print'
)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
数据处理:
insert into sink_table
select dim,
count(distinct user_id) as uv
from source_table
group by dim
- 1.
- 2.
- 3.
- 4.
- 5.
2.运行:
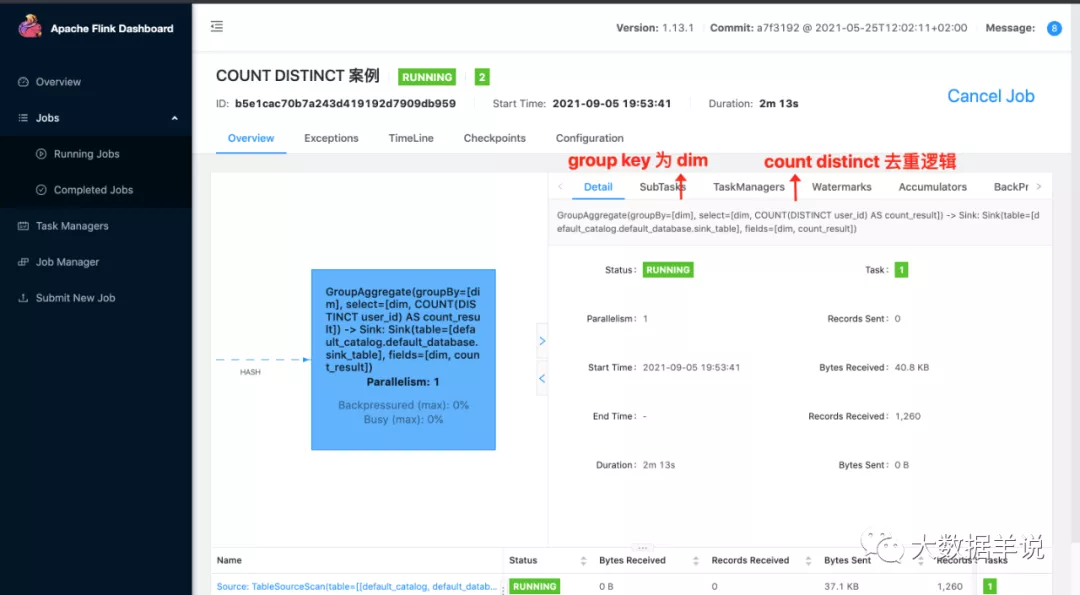
3.上面这个案例的结果:
+U[9, 3097]
-U[a, 3054]
+U[a, 3055]
-U[8, 3030]
+U[8, 3031]
-U[4, 3137]
+U[4, 3138]
-U[6, 3139]
+U[6, 3140]
-U[0, 3082]
+U[0, 3083]
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
4.原理:
此处只看和之前的案例不一样的地方。
4.2.3.3.语法糖
1.grouping sets
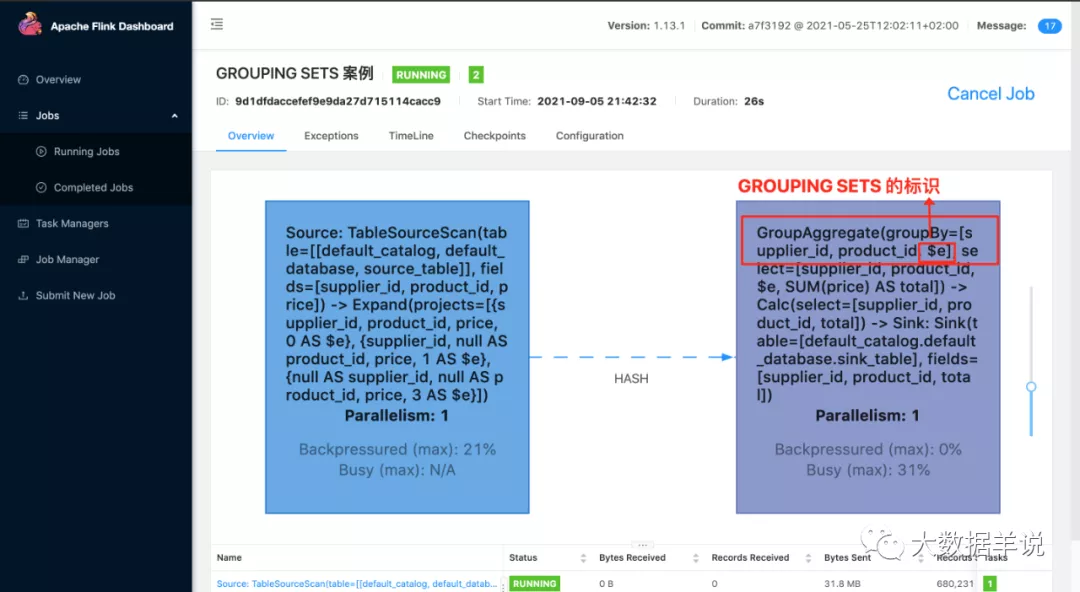
多维计算。相当于语法糖,用户可以根据自己的场景去指定自己想要的维度组合。
数据汇:
CREATE TABLE sink_table (
supplier_id STRING,
product_id STRING,
total BIGINT
) WITH (
'connector' = 'print'
)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
数据处理逻辑:
insert into sink_table
SELECT
supplier_id,
product_id,
COUNT(*) AS total
FROM (VALUES
('supplier1', 'product1', 4),
('supplier1', 'product2', 3),
('supplier2', 'product3', 3),
('supplier2', 'product4', 4))
AS Products(supplier_id, product_id, rating)
GROUP BY GROUPING SETS ((supplier_id, product_id), (supplier_id), ())
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
其结果等同于:
insert into sink_table
SELECT
supplier_id,
product_id,
COUNT(*) AS total
FROM (VALUES
('supplier1', 'product1', 4),
('supplier1', 'product2', 3),
('supplier2', 'product3', 3),
('supplier2', 'product4', 4))
AS Products(supplier_id, product_id, rating)
GROUP BY supplier_id, product_id
UNION ALL
SELECT
supplier_id,
cast(null as string) as product_id,
COUNT(*) AS total
FROM (VALUES
('supplier1', 'product1', 4),
('supplier1', 'product2', 3),
('supplier2', 'product3', 3),
('supplier2', 'product4', 4))
AS Products(supplier_id, product_id, rating)
GROUP BY supplier_id
UNION ALL
SELECT
cast(null as string) AS supplier_id,
cast(null as string) AS product_id,
COUNT(*) AS total
FROM (VALUES
('supplier1', 'product1', 4),
('supplier1', 'product2', 3),
('supplier2', 'product3', 3),
('supplier2', 'product4', 4))
AS Products(supplier_id, product_id, rating)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
结果如下:
+I[supplier1, product1, 1]
+I[supplier1, null, 1]
+I[null, null, 1]
+I[supplier1, product2, 1]
-U[supplier1, null, 1]
+U[supplier1, null, 2]
-U[null, null, 1]
+U[null, null, 2]
+I[supplier2, product3, 1]
+I[supplier2, null, 1]
-U[null, null, 2]
+U[null, null, 3]
+I[supplier2, product4, 1]
-U[supplier2, null, 1]
+U[supplier2, null, 2]
-U[null, null, 3]
+U[null, null, 4]
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
grouping sets 能帮助我们在多维场景下,减少很多冗余代码。关于 grouping sets 原理后面的系列文章会介绍。
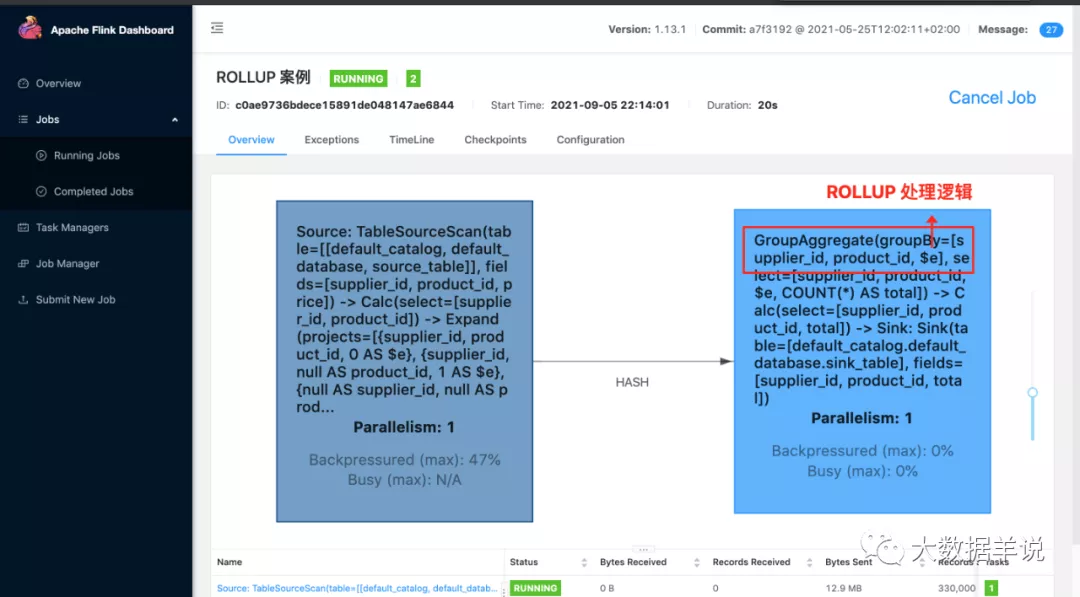
2.rollup
rollup 是上卷计算的一种简化写法。比如可以把 GROUPING SETS ((supplier_id, product_id), (supplier_id), ()) 简化为 ROLLUP (supplier_id, product_id)。
数据汇:
CREATE TABLE sink_table (
supplier_id STRING,
product_id STRING,
total BIGINT
) WITH (
'connector' = 'print'
)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
数据处理逻辑:
SELECT supplier_id, rating, COUNT(*)
FROM (VALUES
('supplier1', 'product1', 4),
('supplier1', 'product2', 3),
('supplier2', 'product3', 3),
('supplier2', 'product4', 4))
AS Products(supplier_id, product_id, rating)
GROUP BY ROLLUP (supplier_id, product_id)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
其结果等同于:
SELECT supplier_id, rating, product_id, COUNT(*)
FROM (VALUES
('supplier1', 'product1', 4),
('supplier1', 'product2', 3),
('supplier2', 'product3', 3),
('supplier2', 'product4', 4))
AS Products(supplier_id, product_id, rating)
GROUP BY GROUPING SET (
( supplier_id, product_id ),
( supplier_id ),
( )
)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
结果如下:
+I[supplier1, product1, 1]
+I[supplier1, null, 1]
+I[null, null, 1]
+I[supplier1, product2, 1]
-U[supplier1, null, 1]
+U[supplier1, null, 2]
-U[null, null, 1]
+U[null, null, 2]
+I[supplier2, product3, 1]
+I[supplier2, null, 1]
-U[null, null, 2]
+U[null, null, 3]
+I[supplier2, product4, 1]
-U[supplier2, null, 1]
+U[supplier2, null, 2]
-U[null, null, 3]
+U[null, null, 4]
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
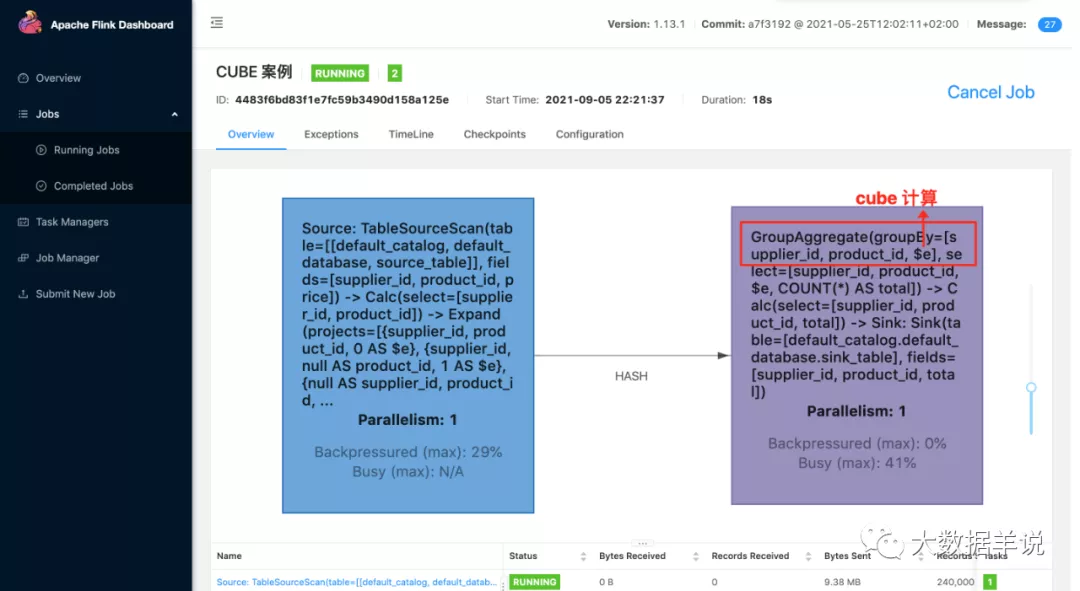
5.CUBE 计算
源码公众号后台回复不会连最适合 flink sql 的 ETL 和 group agg 场景都没见过吧获取。
cube 相当于是一种覆盖了所有维度组合聚合计算。比如 group by a, b, c。其会将 a, b, c 三个维度的所有维度组合进行 group by。
数据汇:
CREATE TABLE sink_table (
supplier_id STRING,
product_id STRING,
total BIGINT
) WITH (
'connector' = 'print'
)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
数据处理逻辑:
SELECT supplier_id, rating, product_id, COUNT(*)
FROM (VALUES
('supplier1', 'product1', 4),
('supplier1', 'product2', 3),
('supplier2', 'product3', 3),
('supplier2', 'product4', 4))
AS Products(supplier_id, product_id, rating)
GROUP BY CUBE (supplier_id, product_id)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
它等同于
SELECT supplier_id, rating, product_id, COUNT(*)
FROM (VALUES
('supplier1', 'product1', 4),
('supplier1', 'product2', 3),
('supplier2', 'product3', 3),
('supplier2', 'product4', 4))
AS Products(supplier_id, product_id, rating)
GROUP BY GROUPING SET (
( supplier_id, product_id ),
( supplier_id ),
( product_id ),
( )
)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
结果如下:
+I[supplier1, product1, 1]
+I[supplier1, null, 1]
+I[null, product1, 1]
+I[null, null, 1]
+I[supplier1, product2, 1]
-U[supplier1, null, 1]
+U[supplier1, null, 2]
+I[null, product2, 1]
-U[null, null, 1]
+U[null, null, 2]
+I[supplier2, product3, 1]
+I[supplier2, null, 1]
+I[null, product3, 1]
-U[null, null, 2]
+U[null, null, 3]
+I[supplier2, product4, 1]
-U[supplier2, null, 1]
+U[supplier2, null, 2]
+I[null, product4, 1]
-U[null, null, 3]
+U[null, null, 4]
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
5.总结与展望篇
本文主要介绍了 ETL,group agg 聚合类指标的一些常见场景案例以及其底层运行原理。我们可以发现 flink sql 的语法其实和 hive sql,mysql 啥的语法都是基本一致的。所以上手 flink sql 时,语法基本不会成为我们的障碍。
而且也介绍了在查看 flink sql 任务时的一些技巧:
去 flink webui 看看这个任务目前在做什么。包括算子名称都会给直接展示给我们目前哪个算子在干啥事情,在处理啥逻辑。
如果你想知道你的 flink 任务执行了什么代码,就去看看 sql 最后转换成的 transformation 里面具体要执行哪些操作。
后续文章会继续介绍 flink sql 窗口聚合,一些理解误区,和坑之类的案例。
本文转载自微信公众号「大数据羊说」

























