内存 是操作系统非常重要的资源,操作系统要运行一个程序,必须先把程序代码段的指令和数据段的变量从硬盘加载到内存中,然后才能被运行。如下图所示:

但内存资源是有限的,随着系统中运行的进程越来越多,系统中可用的内存就会越来越少。那么,当可用内存不足时,Linux 内核是怎么处理的呢?
本文将会介绍,当可用内存不足时,Linux 内核的处理方式。
一、内存不足的处理方式
我们思考一下,当系统的可用内存不足时,进程继续申请内存会发生什么事情?
当系统的可用内存不足时,内核为了保证进程有足够的内存可用,将会对内存进行回收工作。内存回收工作主要包括以下几个步骤:
- 内核为了加速某些操作(如文件 I/O),会对操作的结果进行缓存(如文件页缓存),而缓存使用的内存是可以被回收的。所以,当可用内存不足时,首先会回收内核中的缓存。
- 如果回收内核缓存后,系统的可用内存仍然处于不足。那么,内核将会触发 swap 机制。swap 机制会将某些进程所占用的内存交换(写入)到硬盘中,然后释放这些内存,从而让系统有更多可用的内存。本文将会重点介绍 swap 机制。
- 如果触发 swap 机制后,系统的可用内存仍不能满足系统需求,那么将会触发 OOM(Out Of Memory) 机制。OOM 机制将会挑选一些进程,然后将这些进程杀死来,从而获取更多可用内存。
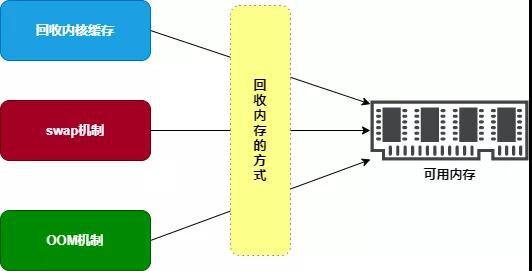
由于回收内存的方式有三种,所以本文重点以 swap 机制作为分析对象,来介绍当内存不足时,内核是怎么进行内存回收工作的。
二、swap机制原理
在分析 swap 机制的实现前,我们先来介绍一下 swap 机制的原理。
本文使用 Linux-2.6.23 版本内核。
swap 这个单词是 交换 的意思,顾名思义就是把某些进程所占用的内存交换(写入)到硬盘,然后把内存释放给操作系统,这样操作系统就有更多可用的内存。如下图所示:

由于 swap 机制的本质是将进程所占用的内存写入到硬盘中,然后释放这些内存。那么,就涉及到应该将哪些进程的内存交换到硬盘中。
每个进程都不希望自己占用的内存被交换到硬盘中,因为内存被交换到硬盘后,如果进程要使用到这些内存时,必须先将这些内存从硬盘中加载到内存中,才能继续使用,这样进程的性能将会大打折扣。正因为这个原因,内核必须提供一种最优的方案来挑选一些内存交换到硬盘,并且对进程性能的影响降到最小。
由于进程的内存空间分为多个段,如 代码段、数据段、mmap段、堆段 和 栈段 等。那么,哪些段的内存会被交换到硬盘中呢?
答案就是:所有段的内存都有可能交换到硬盘。不过对于 代码段 和 mmap段 这些与文件有映射关系的内存区,只需要将数据写回到文件即可(由于代码段的内容不会改变,所以不用进行回写)。
而对于 数据段、堆段 和 栈段 这些段中的内存页,由于没有与文件进行映射(称为 匿名内存页),所以内核必须提供一个文件(或硬盘分区)来存储这些内存页的数据,这个文件(或硬盘分区)被称为 交换分区。
从上面的分析可以得出两个重要的信息:
匿名内存页:没有与任何文件进行映射的内存页。
交换分区:用于存储匿名内存页数据的文件或硬盘分区。
下面主要介绍当系统内存不足时,内核是怎样将进程的 匿名内存页 写入到 交换分区 中,并且回收这些 匿名内存页 的。
1. LRU 内存淘汰算法
当系统内存不足,并且触发 swap机制 时,内核应该选择哪些 匿名内存页 写入到 交换分区 中呢?如果随机选择一些 匿名内存页 写入到 交换分区,就有可能出现如下问题:
把某个进程的 匿名内存页 写入到 交换分区 后,进程又马上访问这个内存页,从而又要把这个内存页从 交换分区 中读入到内存中。这样只会增加系统的负荷,并且不能解决系统内存不足的问题。
为了解决这个问题,Linux 内核引入了 LRU内存淘汰算法,用过 Memcached 或者 Redis 的同学应该都了解过 LRU算法。当系统内存不足时,Memcached 和 Redis 都是使用 LRU算法 来淘汰内存的。
LRU(Least Recently Used) 中文翻译是 最近最少使用 的意思,其原理就是:当内存不足时,淘汰系统中最少使用的内存,这样对系统性能的损耗是最小的。
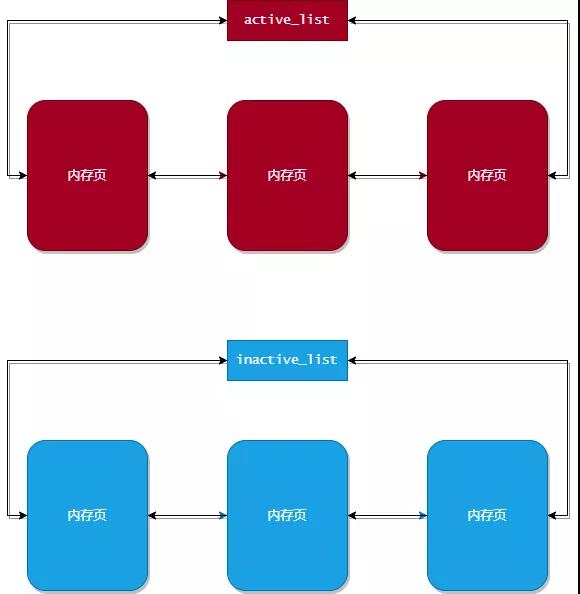
为了实现 LRU算法,内核维护了两个双向链表:active_list 和 inactive_list。下面介绍下这两个链表的作用:
- active_list:活跃内存页链表。也就是说进程会经常访问这个链表中的内存页,所以进行内存淘汰时,不应该淘汰这个链表中的内存页。
- inactive_list:不活跃内存页链表。也就是说进程很少会访问这个链表中的内存页,所以进行内存淘汰时,主要淘汰这个链表中的内存页。
在 Linux 内核中,每个 内存区(zone) 都会维护着一个 active_list 和一个 inactive_list。内存区 是内存管理中的一个对象,为了描述更加清晰,我们暂时当成内核中只有一个内存区,也就是说暂时认为内核中只维护着一个 active_list 和一个 inactive_list。如下图所示:
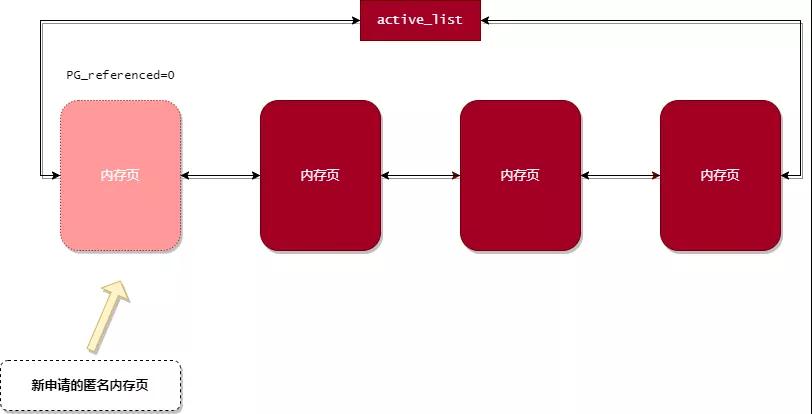
另外,每个内存页都有个 PG_referenced 的标志位,表示此内存页是否被访问过,这个标志位在内存回收过程中起着至关重要的作用。
当某个进程申请一个匿名内存页时,内核会把这个内存页添加到 活跃内存页链表(active_list) 中,并且将 PG_referenced 标志位设置为 0。如下图所示:
而当某个匿名内存页被进程访问时,根据内存页所在的 LRU 链表作不同的操作:
- 如果内存页原来处于 活跃链表 中,那么就会把此内存页的 PG_referenced 设置为 1。
- 如果内存页原来处于 非活跃链表 中,并且 PG_referenced 为 0。那么将内存页的 PG_referenced 标志位设置为 1。
- 如果内存页原来处于 非活跃链表 中,并且 PG_referenced 为 1。那么将会把内存页从 非活跃链表 移动到 活跃链表,并且将 PG_referenced 设置为 0。
下图展示了上述各种情况的流转过程:
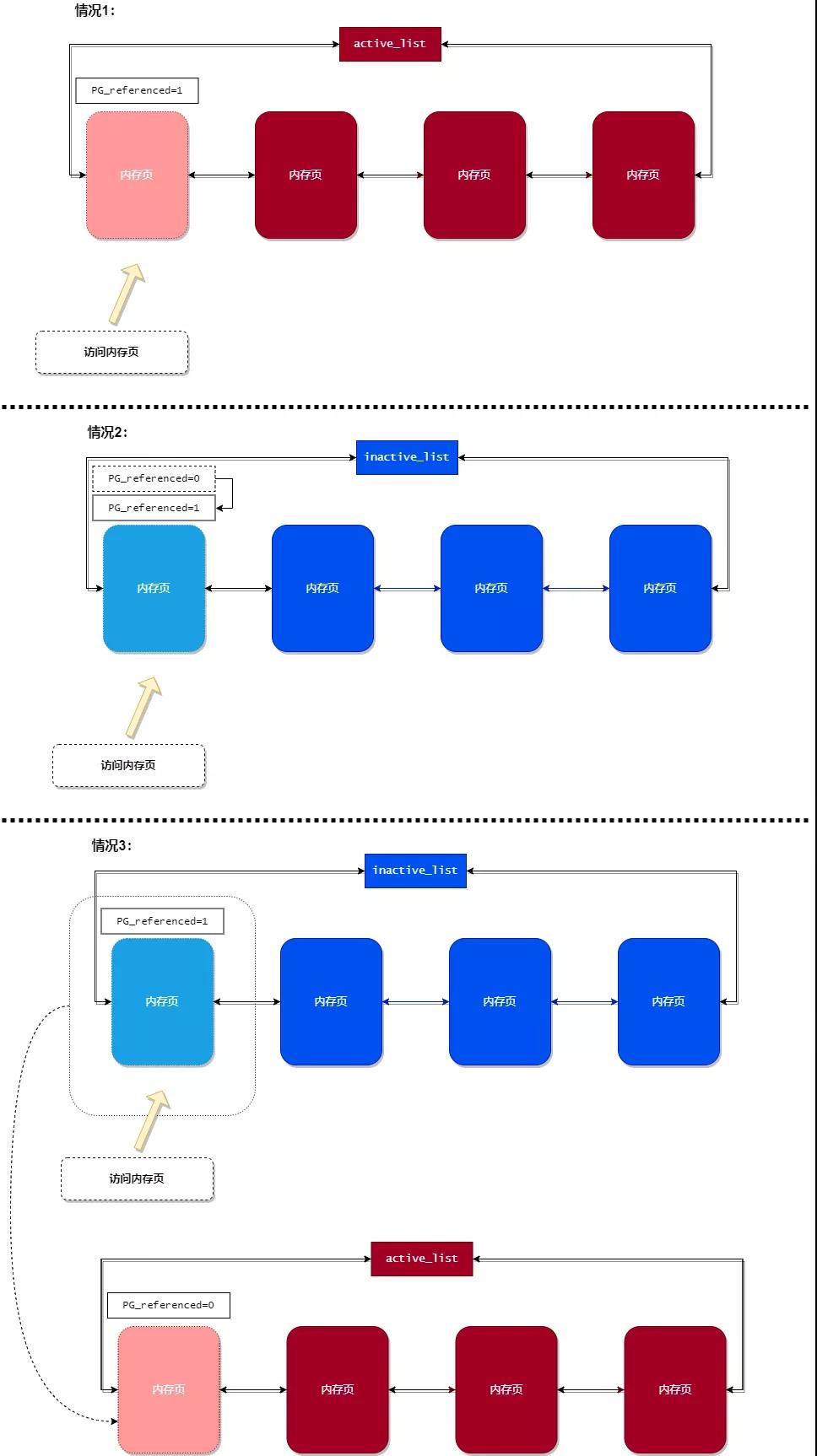
而当系统内存不足时,需要进行内存淘汰过程。内存页淘汰过程与上述过程刚好相反,下面介绍一下内存页淘汰的过程。
内存淘汰时,只能从 非活跃链表 中进行淘汰,淘汰过程如下:
- 从 非活跃链表 的尾部开始进行内存淘汰,如果内存页的 PG_referenced 标志位为 1 时,将跳过此内存页,并且将此内存页的 PG_referenced 标志位设置为 0。
- 如果内存页的 PG_referenced 标志位为 0 时,那么将此内存页写入到 交换分区 中,并且将所有与此内存页的映射解除绑定,然后释放此内存页。
上述过程是由 shrink_inactive_list 函数完成,如下图所示:

另外,处于 活跃链表 的内存页也有衰退的过程,衰退过程如下:
- 如果内存页的 PG_referenced 标志位为 1,那么衰退过程将会把此内存页的 PG_referenced 标志位设置为 0。
- 如果内存页的 PG_referenced 标志位为 0,那么衰退过程将会把此内存页移动到 非活跃链表 中。
上述过程是由 shrink_active_list 函数完成,如下图所示:

2. LRU算法状态流转
我们最后以一张状态流转图来描述 LRU 算法的过程:

三、总结
本文主要介绍了 Linux 内核内存回收过程中使用的 LRU 算法的原理,在下一篇文章中,我们将会介绍 Linux 内核是如何实现内存回收的,有兴趣的敬请期待。