













前言
Android的三级缓存,其中主要的就是内存缓存和硬盘缓存。这两种缓存机制的实现都应用到了LruCache算法,今天我们就从使用到源码解析,来彻底理解Android中的缓存机制;
一、LruCache概念介绍
1.什么是LruCache?
LruCache是Android 3.1所提供的一个缓存类,所以在Android中可以直接使用LruCache实现内存缓存。而DisLruCache目前在Android 还不是Android SDK的一部分,但Android官方文档推荐使用该算法来实现硬盘缓存;
LruCache是个泛型类,主要算法原理是把最近使用的对象用强引用(即我们平常使用的对象引用方式)存储在 LinkedHashMap 中。当缓存满时,把最近最少使用的对象从内存中移除,并提供了get和put方法来完成缓存的获取和添加操作;
2.LruCache的使用
LruCache的使用非常简单,我们就已图片缓存为例
int maxMemory = (int) (Runtime.getRuntime().totalMemory()/1024);
int cacheSize = maxMemory/8;
mMemoryCache = new LruCache<String,Bitmap>(cacheSize){
@Override
protected int sizeOf(String key, Bitmap value) {
return value.getRowBytes()*value.getHeight()/1024;
}
};
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
①设置LruCache缓存的大小,一般为当前进程可用容量的1/8;
②重写sizeOf方法,计算出要缓存的每张图片的大小;
注意:缓存的总容量和每个缓存对象的大小所用单位要一致;
二、LruCache的实现原理
LruCache的核心思想很好理解,就是要维护一个缓存对象列表,其中对象列表的排列方式是按照访问顺序实现的,即一直没访问的对象,将放在队尾,即将被淘汰。而最近访问的对象将放在队头,最后被淘汰;
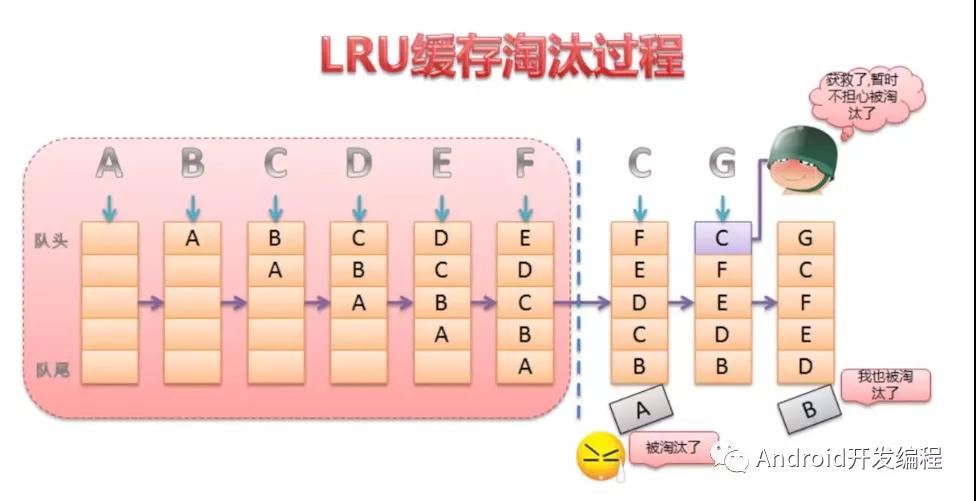
1、构造函数
public LruCache(int maxSize) {
if (maxSize <= 0) {
throw new IllegalArgumentException("maxSize <= 0");
}
this.maxSize = maxSize;
this.map = new LinkedHashMap<K, V>(0, 0.75f, true);
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
创建LruCache对象时,它内部做的工作如下:
- 记录下制定的最大容量maxSize;
- 创建一个初始容量为0的LinkedHashMap,用来保存对象;
- 所以,在创建LruCache对象时,我们需要指定一个最大容量值maxSize,它可以是具体数值,也可以是内存空间,与它对应的是sizeOf方法:
protected int sizeOf(K key, V value) {
return 1;
}
- 1.
- 2.
- 3.
如果我们想以数量的方式来控制缓存,可以看到,默认的sizeOf方法返回值为1,也就是说每次添加一条数据,它所占用的空间为1,直到添加的内容数量达到maxSize,这时候再添加数据,系统就会挑选出使用频率最低的值,将他们移除;
如果以内存空间作为缓存限制,需要重写size,返回对象所占用的空间大小:
int maxMemory = (int) (Runtime.getRuntime().maxMemory())/1024;//获取可用内存,转换为单位KB
int maxCache = maxMemory/10;//缓存大小为可用内存的1/10
LruCache mMemoryCache = new LruCache<String,Bitmap>(maxCache){
@Override//重写sizeOf方法,返回每条数据占用的内存
protected int sizeOf(String key, Bitmap value) {
return value.getRowBytes()*value.getHeight() / 1024;
//return value.getByteCount() / 1024;
}
};
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
2、读取内容
读取内容对应的是get方法,源码如下:
public final V get(K key) {
if (key == null) { //如果key为null,直接抛出异常
throw new NullPointerException("key == null");
}
V mapValue;
synchronized (this) {
mapValue = map.get(key); //读取key对应的值
if (mapValue != null) {
hitCount++;
return mapValue; //如果获取到内容,返回
}
missCount++; //如果未读到内容,missCount计数增加,继续向下执行
}
/*尝试创建value,可能会消耗一定的时间,当创建完成时,map可能已经发生变化
如果此时发现创建时使用的key已经存在,导致冲突,丢弃掉create创建的值
* Attempt to create a value. This may take a long time, and the map
* may be different when create() returns. If a conflicting value was
* added to the map while create() was working, we leave that value in
* the map and release the created value.
*/
//如果未获取到value,调用create方法,尝试创建对象
//create方法默认返回null,可以覆写该方法,决定获取不到值时的添加方法
V createdValue = create(key);
if (createdValue == null) {
return null;
}
//以下部分为创建之后对map的修改动作,包括存放对象,调整size等。
synchronized (this) {
createCount++;
mapValue = map.put(key, createdValue);
if (mapValue != null) {
// There was a conflict so undo that last put
map.put(key, mapValue);
} else {
size += safeSizeOf(key, createdValue);
}
}
if (mapValue != null) {
entryRemoved(false, key, createdValue, mapValue);
return mapValue;
} else {
trimToSize(maxSize);
return createdValue;
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
get方法尝试根据传入的key来读取内容,如果读取不到,可以选择是否创建一个对象,如果选择创建对象,需要我们覆写create方法来返回要创建的对象,使用也很简单;
3、存储内容
存储内容使用的是put方法:
public final V put(K key, V value) {
if (key == null || value == null) {
throw new NullPointerException("key == null || value == null");
}
V previous;
synchronized (this) {
putCount++;
size += safeSizeOf(key, value);
previous = map.put(key, value);
if (previous != null) {
size -= safeSizeOf(key, previous);
}
}
if (previous != null) {
entryRemoved(false, key, previous, value);
}
trimToSize(maxSize);
return previous;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
在存放内容的时候,可以看到是怎样控制缓存size的:存放内容之后会将执行size += safeSizeOf(key, value);,safeSizeOf的默认实现就是sizeOf方法。每存放一个对象,就会将size增加对应的值。如果存放的key已经存在数据,那么size不变;
同时还提供了一个entryRemoved方法,该方法在数据被移除时(调用remove移除,新值覆盖,超出缓存被删除)调用,默认实现为空;
在put的最后则是调用了trimToSize,这是控制缓存大小的方法,每当有新的数据存入时,该方法都会被调用。当前size超出缓存最大值之后,会通过此方法删除最近最少使用的数据;
除了正常的存储,读取之外,LruCache还提供了一个一次性读取全部缓存对象的方法:
public synchronized final Map<K, V> snapshot() {
return new LinkedHashMap<K, V>(map);
}
- 1.
- 2.
- 3.
4、trimToSize()方法
public void trimToSize(int maxSize) {
//死循环
while (true) {
K key;
V value;
synchronized (this) {
//如果map为空并且缓存size不等于0或者缓存size小于0,抛出异常
if (size < 0 || (map.isEmpty() && size != 0)) {
throw new IllegalStateException(getClass().getName()
+ ".sizeOf() is reporting inconsistent results!");
}
//如果缓存大小size小于最大缓存,或者map为空,不需要再删除缓存对象,跳出循环
if (size <= maxSize || map.isEmpty()) {
break;
}
//迭代器获取第一个对象,即队尾的元素,近期最少访问的元素
Map.Entry<K, V> toEvict = map.entrySet().iterator().next();
key = toEvict.getKey();
value = toEvict.getValue();
//删除该对象,并更新缓存大小
map.remove(key);
size -= safeSizeOf(key, value);
evictionCount++;
}
entryRemoved(true, key, value, null);
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
总结
LruCache中维护了一个集合LinkedHashMap,该LinkedHashMap是以访问顺序排序的。当调用put()方法时,就会在结合中添加元素,并调用trimToSize()判断缓存是否已满,如果满了就用LinkedHashMap的迭代器删除队尾元素,即近期最少访问的元素。当调用get()方法访问缓存对象时,就会调用LinkedHashMap的get()方法获得对应集合元素,同时会更新该元素到队头;















