本文转载自微信公众号「神光的编程秘籍」,作者神说要有光。转载本文请联系神光的编程秘籍公众号。
都说 Node.js 可以实现高性能的服务器,那什么是高性能呢?
所有的软件代码最终都是通过 CPU 来跑的,能不能把 CPU 高效利用起来是区分性能高低的标志,也就是说不能让它空转。
那什么时候会空转呢?
- 当程序在进行网络和磁盘的 IO 的时候,这时候 CPU 是空闲的,也就是在空转。
- 多核 CPU 可以同时跑多个程序,如果只利用了其中一核,那么其他核也是在空转。
所以,要想达到高性能,就要解决这两个问题。
操作系统提供了线程的抽象,对应代码不同的执行分支,都是可以同时上不同的 CPU 跑的,这是利用好多核 CPU 性能的方式。
而如果有的线程在进行 IO 了,也就是要阻塞的等待读写完成,这种是比较低效的方式,所以操作系统实现了 DMA 的机制,就是设备控制器,由硬件来负责从设备到内存的搬运,在搬完了告诉 CPU 一声。这样当有的线程在 IO 的时候就可以把线程暂停掉,等收到 DMA 运输数据完成的通知再继续跑。
多线程、DMA,这是利用好多核 CPU 优势、解决 CPU 阻塞等 IO 的问题的操作系统提供的解决方案。
而各种编程语言对这种机制做了封装,Node.js 也是,Node.js 之所以是高性能,就是因为异步 IO 的设计。
Node.js 的异步 IO 的实现在 libuv,基于操作系统提供的异步的系统调用,这种一般是硬件级别的异步,比如 DMA 搬运数据。但是其中有一些同步的系统调用,通过 libuv 封装以后也会变成异步的,这是因为 libuv 内有个线程池,来执行这些任务,把同步的 API 变成异步的。这个线程池的大小可以通过 UV_THREADPOOL_SIZE 的环境变量设置,默认是 4。
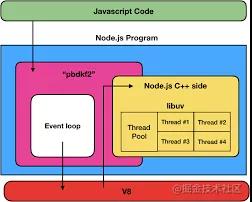
我们在代码里调用的异步 API,很多都是通过线程来实现的。
比如:
- const fsPromises = require('fs').promises;
- const data = await fsPromises.readFile('./filename');
但是,这种异步 API 只解决了 IO 的问题,那如何利用多核 CPU 的优势来做计算呢?
Node.js 在 10.5 实验性的引入(在 12 正式引入)了 worker_thread 模块,可以创建线程,最终用多个 CPU 跑,这是利用多核 CPU 的做计算的方式。
异步 API 可以利用多线程做 IO,而 worker_thread 可以创建线程做计算,用于不同的目的。
要聊清楚 worker_thread,还得从浏览器的 web worker 聊起。
浏览器的 web worker
浏览器也同样面临不能利用多核 CPU 做计算的问题,所以 html5 引入了 web worker,可以通过另一个线程做计算。
我们创建一个 Worker 对象,指定跑在另一个线程的 js 代码,然后通过 postMessage 传递消息给它,通过 onMessage 接收消息。这个过程也是异步的,我们进一步把它封装成了 promise。
然后在 webWorker.js 里面接收数据,做计算,之后通过 postMessage 传回结果。
- <!DOCTYPE html>
- <html lang="en">
- <head></head>
- <body>
- <script>
- (async function () {
- const res = await runCalcWorker(2, 3, 3, 3);
- console.log(res);
- })();
- function runCalcWorker(...nums) {
- return new Promise((resolve, reject) => {
- const calcWorker = new Worker('./webWorker.js');
- calcWorker.postMessage(nums)
- calcWorker.onmessage = function (msg) {
- resolve(msg.data);
- };
- calcWorker.onerror = reject;
- });
- }
- </script>
- </body>
- </html>
这样,我们就利用了另一个 CPU 核来跑了这段计算,对写代码来说和普通的异步代码没啥区别。但这个异步实际上不是 IO 的异步,而是计算的异步。
Node.js 的 worker thread 和 web worker 类似,我甚至怀疑 worker thread 的名字就是受 web worker 影响的。
Node.js 的 worker thread
把上面那段异步计算的逻辑在 Node.js 里面实现话,是这样的:
- const runCalcWorker = require('./runCalcWorker');
- (async function () {
- const res = await runCalcWorker(2, 3, 3, 3);
- console.log(res);
- })();
以异步的方式调用,因为异步计算和异步 IO 在使用方式上没啥区别。
- // runCalcWorker.js
- const { Worker } = require('worker_threads');
- module.exports = function(...nums) {
- return new Promise(function(resolve, reject) {
- const calcWorker = new Worker('./nodeWorker.js');
- calcWorker.postMessage(nums);
- calcWorker.on('message', resolve);
- calcWorker.on('error', reject);
- });
- }
然后异步计算的实现是通过创建 Worker 对象,指定在另一个线程跑的 JS,然后通过 postMessage 传递消息,通过 message 接收消息。这个和 web worker 很类似。
- // nodeWorker.js
- const {
- parentPort
- } = require('worker_threads');
- parentPort.on('message', (data) => {
- const res = data.reduce((total, cur) => {
- return total += cur;
- }, 0);
- parentPort.postMessage(res);
- });
在具体执行计算的 nodeWorker.js 里面,监听 message 消息,然后进行计算,通过 parentPost.postMessage 传回数据。
对比下 web worker,你会发现特别的像。所以,我觉得 Node.js 的 worker thread 的 api 是参考 web worker 来设计的。
但是,其实 worker thread 也支持在创建的时候就通过 wokerData 传递数据:
- const { Worker } = require('worker_threads');
- module.exports = function(...nums) {
- return new Promise(function(resolve, reject) {
- const calcWorker = new Worker('./nodeWorker.js', {
- workerData: nums
- });
- calcWorker.on('message', resolve);
- calcWorker.on('error', reject);
- });
- }
然后 worker 线程里通过 workerData 来取:
- const {
- parentPort,
- workerData
- } = require('worker_threads');
- const data = workerData;
- const res = data.reduce((total, cur) => {
- return total += cur;
- }, 0);
- parentPort.postMessage(res);
因为有个传递消息的机制,所以要做序列化和反序列化,像函数这种无法被序列化的数据就无法传输了。这也是 worker thread 的特点。
Node.js 的 worker thread 和 浏览器 web woker 的对比
从使用上来看,都可以封装成普通的异步调用,和其他异步 API 用起来没啥区别。
都要经过数据的序列化反序列化,都支持 postMessage、onMessage 来收发消息。
除了 message,Node.js 的 worker thread 支持传递数据的方式更多,比如还有 workerData。
但从本质上来看,两者都是为了实现异步计算,充分利用多核 CPU 的性能,没啥区别。
总结
高性能的程序也就是要充分利用 CPU 资源,不要让它空转,也就是 IO 的时候不要让 CPU 等,多核 CPU 也要能同时利用起来做计算。操作系统提供了线程、DMA的机制来解决这种问题。Node.js 也做了相应的封装,也就是 libuv 实现的异步 IO 的 API,但是计算的异步是 Node 12 才正式引入的,也就是 worker thread,API 设计参考了浏览器的 web worker,传递消息通过 postMessage、onMessage,需要做数据的序列化,所以函数是没法传递的。
从使用上来看异步计算、异步 IO 使用方式一样,但是异步 IO 只是让 cpu 不同阻塞的等待 IO 完成,异步计算是利用了多核 CPU 同时进行并行的计算。