本文转载自微信公众号「python与大数据分析」,作者 一只小小鸟鸟 。转载本文请联系python与大数据分析公众号。
最近工作实在有点忙,前阵子关于梯度和导数的事情把人折腾的够呛,数学学不好,搞机器学习和神经网络真是头疼;想转到应用层面轻松一下,想到了自然语言处理,one hot模型是基础也是入门,看起来很简单的一个列表转矩阵、词典的功能,想着手工实现一下,结果看了一下CountVectorizer,发现不是那么回事儿,还是放弃了。
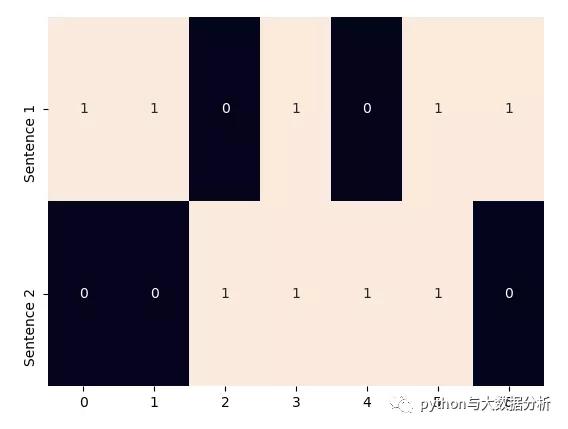
顾名思义,单热表示从一个零向量开始,如果单词出现在句子或文档中,则将向量中的相应条目设置为 1。
对句子进行标记,忽略标点符号,并将所有的单词都用小写字母表示,就会得到一个大小为 8 的词汇表: {time, fruit, flies, like, a, an, arrow, banana} 。所以,我们可以用一个八维的单热向量来表示每个单词。在本书中,我们使用 1[w] 表示标记/单词 w 的单热表示。
对于短语、句子或文档,压缩的单热表示仅仅是其组成词的逻辑或的单热表示。短语 like a banana 的单热表示将是一个 3×8 矩阵,其中的列是 8 维的单热向量。通常还会看到“折叠”或二进制编码,其中文本/短语由词汇表长度的向量表示,用 0 和 1 表示单词的缺失或存在。like a banana 的二进制编码是: [0,0,0,1,1,0,0,1] 。
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
import seaborn as sns
import matplotlib.pyplot as plt
import jieba
import jieba.analyse
# 单热表示从一个零向量开始,如果单词出现在句子或文档中,则将向量中的相应条目设置为 1。
# 英文的处理和展示
corpus = ['Time flies flies like an arrow.', 'Fruit flies like a banana.']
one_hot_vectorizer = CountVectorizer(binary=True)
one_hot = one_hot_vectorizer.fit_transform(corpus).toarray()
sns.heatmap(one_hot, annot=True, cbar=False, yticklabels=['Sentence 1', 'Sentence 2'])
plt.show()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
# 中文的处理和展示
# 获取停用词列表
def get_stopwords_list(stopwordfile):
stopwords = [line.strip() for line in open(stopwordfile, encoding='UTF-8').readlines()]
return stopwords
# 移除停用词
def movestopwords(sentence):
stopwords = get_stopwords_list('stopwords.txt') # 这里加载停用词的路径
santi_words = [x for x in sentence if len(x) > 1 and x not in stopwords]
return santi_words
# 语料
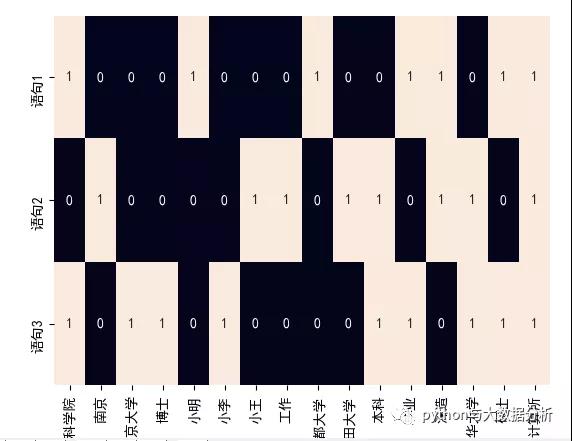
corpus = ["小明硕士毕业于中国科学院计算所,后在日本京都大学深造。",
"小王本科在清华大学,后在南京计算所工作和深造,后在日本早稻田大学深造",
"小李本科在清华大学,硕士毕业于中国科学院计算所,博士在南京大学"]
newcorpus = []
for str in corpus:
orgwordlist = jieba.lcut(str) # jieba分词
wordlist = movestopwords(orgwordlist) # 移除停用词
newword = " ".join(wordlist) # 按照语料库要求进行空格分隔
newcorpus.append(newword) # 按照语料库要求转换成列表
# newcorpus
# ['小明 硕士 毕业 中国科学院 计算所 日本京都大学 深造',
# '小王 本科 清华大学 南京 计算所 工作 深造 日本早稻田大学 深造',
# '小李 本科 清华大学 硕士 毕业 中国科学院 计算所 博士 南京大学']
one_hot_vectorizer = CountVectorizer(binary=True) # 创建词袋数据结构
one_hot = one_hot_vectorizer.fit_transform(newcorpus).toarray() # 转换语料,并矩阵化
# 下面为热词的输出结果
# one_hot_vectorizer.vocabulary_
# {'小明': 4, '硕士': 14, '毕业': 11, '中国科学院': 0, '计算所': 15, '日本京都大学': 8, '深造': 12, '小王': 6, '本科': 10, '清华大学': 13, '南京': 1, '工作': 7, '日本早稻田大学': 9, '小李': 5, '博士': 3, '南京大学': 2}
# one_hot_vectorizer.get_feature_names()
# ['中国科学院', '南京', '南京大学', '博士', '小明', '小李', '小王', '工作', '日本京都大学', '日本早稻田大学', '本科', '毕业', '深造', '清华大学', '硕士', '计算所']
# one_hot
# [[1 0 0 0 1 0 0 0 1 0 0 1 1 0 1 1]
# [0 1 0 0 0 0 1 1 0 1 1 0 1 1 0 1]
# [1 0 1 1 0 1 0 0 0 0 1 1 0 1 1 1]]
sns.set_style({'font.sans-serif': ['SimHei', 'Arial']})
sns.heatmap(one_hot, annot=True, cbar=False, xticklabels=one_hot_vectorizer.get_feature_names(),
yticklabels=['语句1', '语句2', '语句3'])
plt.show()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
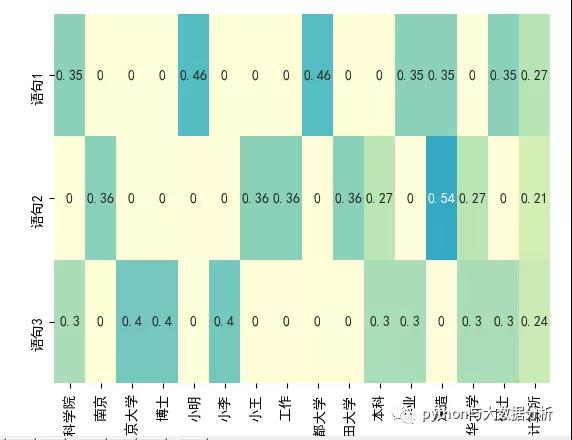
IDF 表示惩罚常见的符号,并奖励向量表示中的罕见符号。符号 w 的 IDF(w) 对语料库的定义为其中 n[w] 是包含单词 w 的文档数量, N 是文档总数。TF-IDF 分数就是 TF(w) * IDF(w) 的乘积。首先,请注意在所有文档(例如, n[w] = N ), IDF(w) 为 0, TF-IDF 得分为 0,完全惩罚了这一项。其次,如果一个术语很少出现(可能只出现在一个文档中),那么 IDF 就是 log n 的最大值
tfidf_vectorizer = TfidfVectorizer() # 创建词袋数据结构
tfidf = tfidf_vectorizer.fit_transform(newcorpus).toarray() # 转换语料,并矩阵化
# 下面为热词的输出结果
# tfidf_vectorizer.vocabulary_
# '小明': 4, '硕士': 14, '毕业': 11, '中国科学院': 0, '计算所': 15, '日本京都大学': 8, '深造': 12, '小王': 6, '本科': 10, '清华大学': 13, '南京': 1, '工作': 7, '日本早稻田大学': 9, '小李': 5, '博士': 3, '南京大学': 2}
# tfidf_vectorizer.get_feature_names()
# ['中国科学院', '南京', '南京大学', '博士', '小明', '小李', '小王', '工作', '日本京都大学', '日本早稻田大学', '本科', '毕业', '深造', '清华大学', '硕士', '计算所']
# tfidf
# [[0.35221512 0. 0. 0. 0.46312056 0. 0. 0. 0.46312056 0. 0. 0.35221512 0.35221512 0. 0.35221512 0.27352646]
# [0. 0.35761701 0. 0. 0. 0. 0.35761701 0.35761701 0. 0.35761701 0.27197695 0. 0.54395391 0.27197695 0. 0.21121437]
# [0.30443385 0. 0.40029393 0.40029393 0. 0.40029393 0. 0. 0. 0. 0.30443385 0.30443385 0. 0.30443385 0.30443385 0.23642005]]
sns.heatmap(tfidf, annot=True, cbar=False, xticklabels=tfidf_vectorizer.get_feature_names(),
yticklabels=['语句1', '语句2', '语句3'], vmin=0, vmax=1, cm
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.