本文实例讲述了Python爬虫实现爬取百度百科词条功能。分享给大家供大家参考,具体如下:
以下我写了一个爬取百度百科词条的实例。
爬虫主程序入口
- from crawler_test.html_downloader import UrlDownLoader
- from crawler_test.html_outer import HtmlOuter
- from crawler_test.html_parser import HtmlParser
- from crawler_test.url_manager import UrlManager
- # 爬虫主程序入口
- class MainCrawler():
- def __init__(self):
- # 初始值,实例化四大处理器:url管理器,下载器,解析器,输出器
- self.urls = UrlManager()
- self.downloader = UrlDownLoader()
- self.parser = HtmlParser()
- self.outer = HtmlOuter()
- # 开始爬虫方法
- def start_craw(self, main_url):
- print('爬虫开始...')
- count = 1
- self.urls.add_new_url(main_url)
- while self.urls.has_new_url():
- try:
- new_url = self.urls.get_new_url()
- print('爬虫%d,%s' % (count, new_url))
- html_cont = self.downloader.down_load(new_url)
- new_urls, new_data = self.parser.parse(new_url, html_cont)
- # 将解析出的url放入url管理器,解析出的数据放入输出器中
- self.urls.add_new_urls(new_urls)
- self.outer.conllect_data(new_data)
- if count >= 10:# 控制爬取的数量
- break
- count += 1
- except:
- print('爬虫失败一条')
- self.outer.output()
- print('爬虫结束。')
- if __name__ == '__main__':
- main_url = 'https://baike.baidu.com/item/Python/407313'
- mc = MainCrawler()
- mc.start_craw(main_url)
URL管理器
- # URL管理器
- class UrlManager():
- def __init__(self):
- self.new_urls = set() # 待爬取
- self.old_urls = set() # 已爬取
- # 添加一个新的url
- def add_new_url(self, url):
- if url is None:
- return
- elif url not in self.new_urls and url not in self.old_urls:
- self.new_urls.add(url)
- # 批量添加url
- def add_new_urls(self, urls):
- if urls is None or len(urls) == 0:
- return
- else:
- for url in urls:
- self.add_new_url(url)
- # 判断是否有url
- def has_new_url(self):
- return len(self.new_urls) != 0
- # 从待爬取的集合中获取一个url
- def get_new_url(self):
- new_url = self.new_urls.pop()
- self.old_urls.add(new_url)
- return new_url
网页下载器
- from urllib import request
- # 网页下载器
- class UrlDownLoader():
- def down_load(self, url):
- if url is None:
- return None
- else:
- rt = request.Request(urlurl=url, method='GET') # 发GET请求
- with request.urlopen(rt) as rp: # 打开网页
- if rp.status != 200:
- return None
- else:
- return rp.read() # 读取网页内容
网页解析器
- import re
- from urllib import parse
- from bs4 import BeautifulSoup
- # 网页解析器,使用BeautifulSoup
- class HtmlParser():
- # 每个词条中,可以有多个超链接
- # main_url指url公共部分,如“https://baike.baidu.com/”
- def _get_new_url(self, main_url, soup):
- # baike.baidu.com/
- # <a target="_blank" href="/item/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%A8%8B%E5%BA%8F%E8%AE%BE%E8%AE%A1%E8%AF%AD%E8%A8%80" rel="external nofollow" >计算机程序设计语言</a>
- new_urls = set()
- # 解析出main_url之后的url部分
- child_urls = soup.find_all('a', href=re.compile(r'/item/(\%\w{2})+'))
- for child_url in child_urls:
- new_url = child_url['href']
- # 再拼接成完整的url
- full_url = parse.urljoin(main_url, new_url)
- new_urls.add(full_url)
- return new_urls
- # 每个词条中,只有一个描述内容,解析出数据(词条,内容)
- def _get_new_data(self, main_url, soup):
- new_datas = {}
- new_datas['url'] = main_url
- # <dd class="lemmaWgt-lemmaTitle-title"><h1>计算机程序设计语言</h1>...
- new_datas['title'] = soup.find('dd', class_='lemmaWgt-lemmaTitle-title').find('h1').get_text()
- # class="lemma-summary" label-module="lemmaSummary"...
- new_datas['content'] = soup.find('div', attrs={'label-module': 'lemmaSummary'},
- class_='lemma-summary').get_text()
- return new_datas
- # 解析出url和数据(词条,内容)
- def parse(self, main_url, html_cont):
- if main_url is None or html_cont is None:
- return
- soup = BeautifulSoup(html_cont, 'lxml', from_encoding='utf-8')
- new_url = self._get_new_url(main_url, soup)
- new_data = self._get_new_data(main_url, soup)
- return new_url, new_data
输出处理器
- # 输出器
- class HtmlOuter():
- def __init__(self):
- self.datas = []
- # 先收集数据
- def conllect_data(self, data):
- if data is None:
- return
- self.datas.append(data)
- return self.datas
- # 输出为HTML
- def output(self, file='output_html.html'):
- with open(file, 'w', encoding='utf-8') as fh:
- fh.write('<html>')
- fh.write('<head>')
- fh.write('<meta charset="utf-8"></meta>')
- fh.write('<title>爬虫数据结果</title>')
- fh.write('</head>')
- fh.write('<body>')
- fh.write(
- '<table style="border-collapse:collapse; border:1px solid gray; width:80%; word-break:break-all; margin:20px auto;">')
- fh.write('<tr>')
- fh.write('<th style="border:1px solid black; width:35%;">URL</th>')
- fh.write('<th style="border:1px solid black; width:15%;">词条</th>')
- fh.write('<th style="border:1px solid black; width:50%;">内容</th>')
- fh.write('</tr>')
- for data in self.datas:
- fh.write('<tr>')
- fh.write('<td style="border:1px solid black">{0}</td>'.format(data['url']))
- fh.write('<td style="border:1px solid black">{0}</td>'.format(data['title']))
- fh.write('<td style="border:1px solid black">{0}</td>'.format(data['content']))
- fh.write('</tr>')
- fh.write('</table>')
- fh.write('</body>')
- fh.write('</html>')
效果(部分):
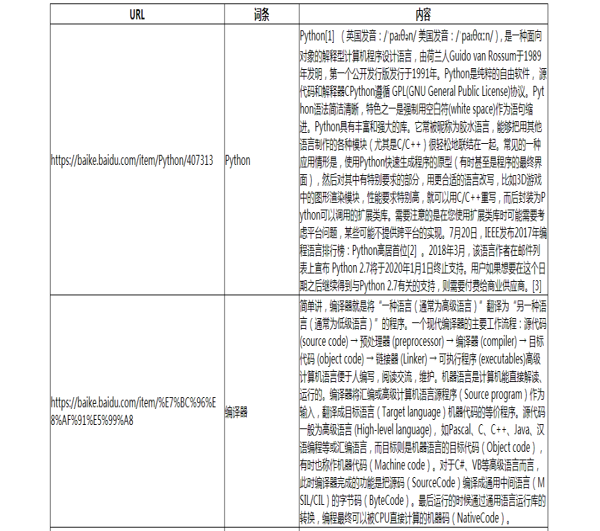
希望本文所述对大家Python程序设计有所帮助。