前言
大家好!我是古月星辰,大三本科生,数学专业,Python爬虫爱好者一枚。今天给大家带来JD数据的简单采集和可视化分析,希望大家可以喜欢。

一、目标数据
随着移动支付的普及,电商网站不断涌现,由于电商网站产品太多,由用户产生的评论数据就更多了,这次我们以京东为例,针对某一单品的评论数据进行数据采集,并且做简单数据分析。
二、页面分析
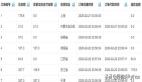
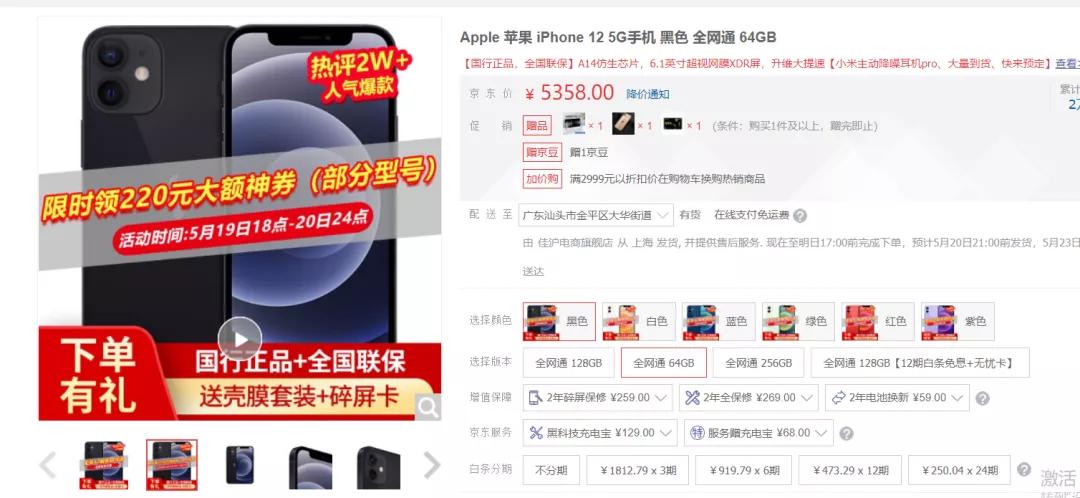
这个是某一手机页面的详情页,对应着手机的各种参数以及用户评论信息,页面URL是:
- https://item.jd.com/10022971060622.html#none
然后通过分析找到评论数据对应的数据接口,如下图所示:
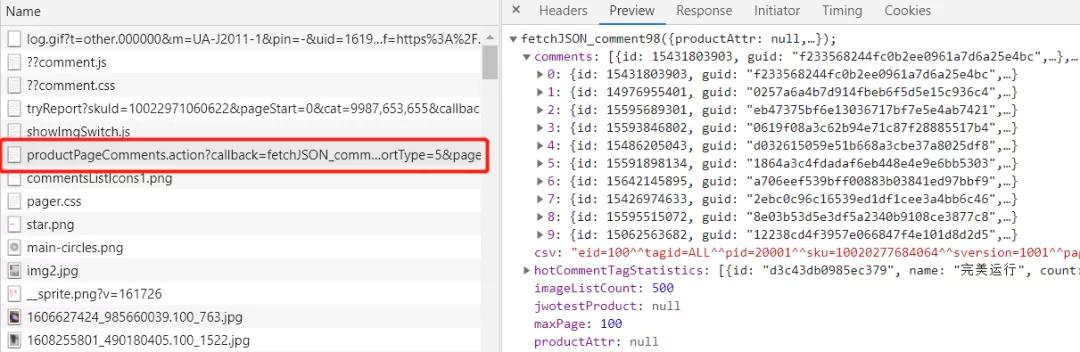
它的请求url:
- https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_com
- ment98& productId=10022971060622 &score=0&sortType=5& page=0 &pageSize=10&isShadowSk
- u=0&fold=1
注意看到这两个关键参数
1. productId: 每个商品有一个id
2. page: 对应的评论分页
三、解析数据
对评论数据的url发起请求:
- url:https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comm
- ent98& productId=10022971060622 &score=0&sortType=5& page=0 &pageSize=10&isShado
- wSku=0&fold=1
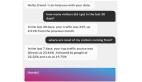
json.cn 打开json数据(我们的评论数据是以json形式与页面进行交互传输的),如下图所示:
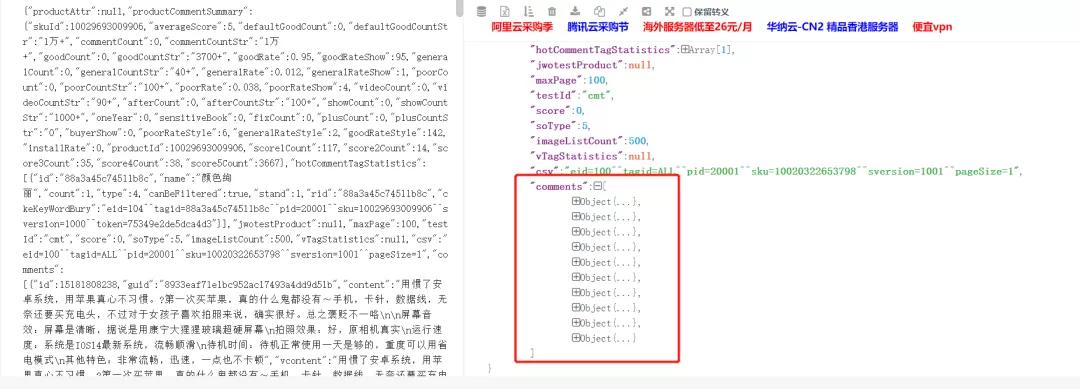
分析可知,评论url中对应十条评论数据,对于每一条评论数据,我们需要获取3条数
据,contents,color,size(注意到上图的maxsize,100,也就是100*10=1000条评论)。
四、程序
1.导入相关库
- import requests
- import json
- import time
- import openpyxl #第三方模块,用于操作Excel文件的
- #模拟浏览器发送请求并获取响应结果
- import random
2.获取评论数据
- def get_comments(productId,page):
- url='https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId={0}&score=0&sortType=5&page={1}&pageSize=10&isShadowSku=0&fold=1'.format(productId,page) # 商品id
- resp=requests.get(url,headers=headers)
- #print(resp.text) #响应结果进行显示输出
- s1=resp.text.replace('fetchJSON_comment98(','') #fetchJSON_comment98(
- s=s1.replace(');','')
- #将str类型的数据转成json格式的数据
- # print(s,type(s))
- # print('*'*100)
- res=json.loads(s)
- print(type(res))
- return res
3.获取最大页数(也可以不写)
- def get_max_page(productId):
- dic_data=get_comments(productId,0) #调用刚才写的函数,向服务器发送请求,获取字典数据
- return dic_data['maxPage']
4.提取数据
- def get_info(productId):
- #调用函数获取商品的最大评论页数
- #max_page=get_max_page(productId)
- # max_page=10
- lst=[] #用于存储提取到的商品数据
- for page in range(0,get_max_page(productId)): #循环执行次数
- #获取每页的商品评论
- comments=get_comments(productId,page)
- comm_lst=comments['comments'] #根据key获取value,根据comments获取到评论的列表(每页有10条评论)
- #遍历评论列表,分别获取每条评论的中的内容,颜色,鞋码
- for item in comm_lst: #每条评论又分别是一个字典,再继续根据key获取值
- content=item['content'] #获取评论中的内容
- color=item['productColor'] #获取评论中的颜色
- size=item['productSize'] #鞋码
- lst.append([content,color,size]) #将每条评论的信息添加到列表中
- time.sleep(3) #延迟时间,防止程序执行速度太快,被封IP
- save(lst) #调用自己编写的函数,将列表中的数据进行存储
5.用于将爬取到的数据存储到Excel中
- def save(lst):
- wk=openpyxl.Workbook () #创建工作薄对象
- sheet=wk.active #获取活动表
- #遍历列表,将列表中的数据添加到工作表中,列表中的一条数据,在Excel中是 一行
- for item in lst:
- sheet.append(item)
- #保存到磁盘上
- wk.save('销售数据.xlsx')
6.运行程序
- if __name__ == '__main__':
- productId='10029693009906' # 单品id
- get_info(productId)
五、简单数据
1.简单配置
- # 导入相关库
- import pandas as pd
- import matplotlib.pyplot as plt
- # 这两行代码解决 plt 中文显示的问题
- plt.rcParams['font.sans-serif'] = ['SimHei']
- plt.rcParams['axes.unicode_minus'] = False
- # 由于采集的时候没有设置表头,此处设置表头
- data = pd.read_excel('./销售数据.xlsx', header=None, names = ['comments','color','intro'] ) #
- data.head()

2.手机颜色数量对比
- x = ['白色','黑色','绿色','蓝色','红色','紫色']
- y = [314,295,181,173,27,10]
- plt.bar(x,y)
- plt.title('各种颜色手机数量对比')
- plt.xlabel('颜色')
- plt.ylabel('数量')
- # plt.legend() # 显示图例
- plt.show()
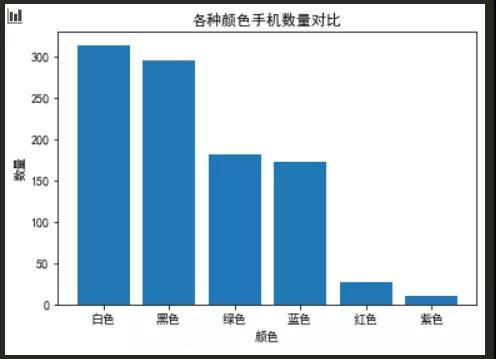
可以看出用户购买的手机白色和黑色的机型比较多.占据了60%多。3.评论词云展示1)先要提取评论数据
- import xlrd
- def strs(row):
- values = "";
- for i in range(len(row)):
- if i == len(row) - 1:
- values = values + str(row[i])
- else:
- values = values + str(row[i])
- return values
- # 打卡文件
- data = xlrd.open_workbook("./销售数据.xlsx")
- sqlfile = open("data.txt", "a") # 文件读写方式是追加
- table = data.sheets()[0] # 表头
- nrows = table.nrows # 行数
- ncols = table.ncols # 列数
- colnames = table.row_values(1) # 某一行数据
- # 打印出行数列数
- for ronum in range(1, nrows):
- row = table.cell_value(rowx=ronum, colx = 0) #只需要修改你要读取的列数-1
- values = strs(row) # 调用函数,将行数据拼接成字符串
- sqlfile.writelines(values + "\n") # 将字符串写入新文件
- sqlfile.close() # 关闭写入的文件
2)词云展示
- # 导入相应的库
- import jieba
- from PIL import Image
- import numpy as np
- from wordcloud import WordCloud
- import matplotlib.pyplot as plt
- # 导入文本数据并进行简单的文本处理
- # 去掉换行符和空格
- text = open("./data.txt",encoding='gbk').read()
- text = text.replace('\n',"").replace("\u3000","")
- # 分词,返回结果为词的列表
- text_cut = jieba.lcut(text)
- # 将分好的词用某个符号分割开连成字符串
- text_cut = ' '.join(text_cut)
注意: 这里我们不能使用encoding='uth-8',会报出一个错误:
- > 'utf-8' codec can't decode byte 0xd3 in position 0: invalid continuation byte
所以我们需要改成 gbk。
- word_list = jieba.cut(text)
- space_word_list = ' '.join(word_list)
- print(space_word_list)
- # 调用包PIL中的open方法,读取图片文件,通过numpy中的array方法生成数组
- mask_pic = np.array(Image.open("./xin.png"))
- word = WordCloud(
- font_path='C:/Windows/Fonts/simfang.ttf', # 设置字体,本机的字体
- mask=mask_pic, # 设置背景图片
- background_color='white', # 设置背景颜色
- max_font_size=150, # 设置字体最大值
- max_words=2000, # 设置最大显示字数
- stopwords={'的'} # 设置停用词,停用词则不在词云途中表示
- ).generate(space_word_list)
- image = word.to_image()
- word.to_file('2.png') # 保存图片
- image.show()
最后得到的效果图,如下图所示:

本文转载自微信公众号「Python爬虫与数据挖掘」,可以通过以下二维码关注。转载本文请联系Python爬虫与数据挖掘公众号。