本文转载自微信公众号「大数据技术与数仓」,作者西贝。转载本文请联系大数据技术与数仓公众号。
引言
Apache YARN(Yet Another Resource Negotiator)是 Hadoop 的集群资源管理器。Yarn 是在 Hadoop 2.x 中引入的。
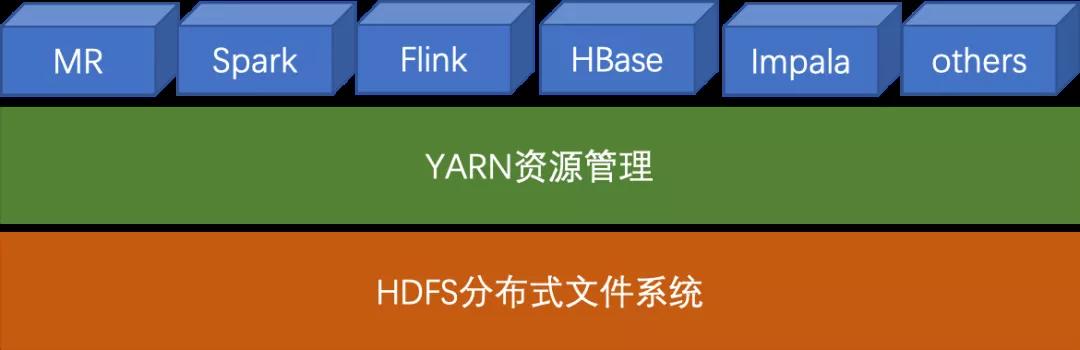
Yarn 允许不同的数据处理引擎,如图形处理、交互处理、流处理以及批处理来运行和处理存储在 HDFS(Hadoop 分布式文件系统)中的数据。其实,YARN不仅负责资源分配,而且也会负责作业的调度。
MapReduce1.0既是一个计算框架,也是一个资源管理调度框架。到了Hadoop2.0以后,MapReduce1.0中的资源管理调度功能,被单独分离出来形成了YARN,它是一个纯粹的资源管理调度框架,而不是一个计算框架。被剥离了资源管理调度功能的MapReduce 框架就变成了MapReduce2.0,它是运行在YARN之上的一个纯粹的计算框架,不再自己负责资源调度管理服务,而是由YARN为其提供资源管理调度服务。
如下图所示:目前主流的大数据计算框架都可以运行在YARN上。
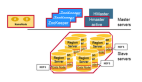
YARN的体系结构
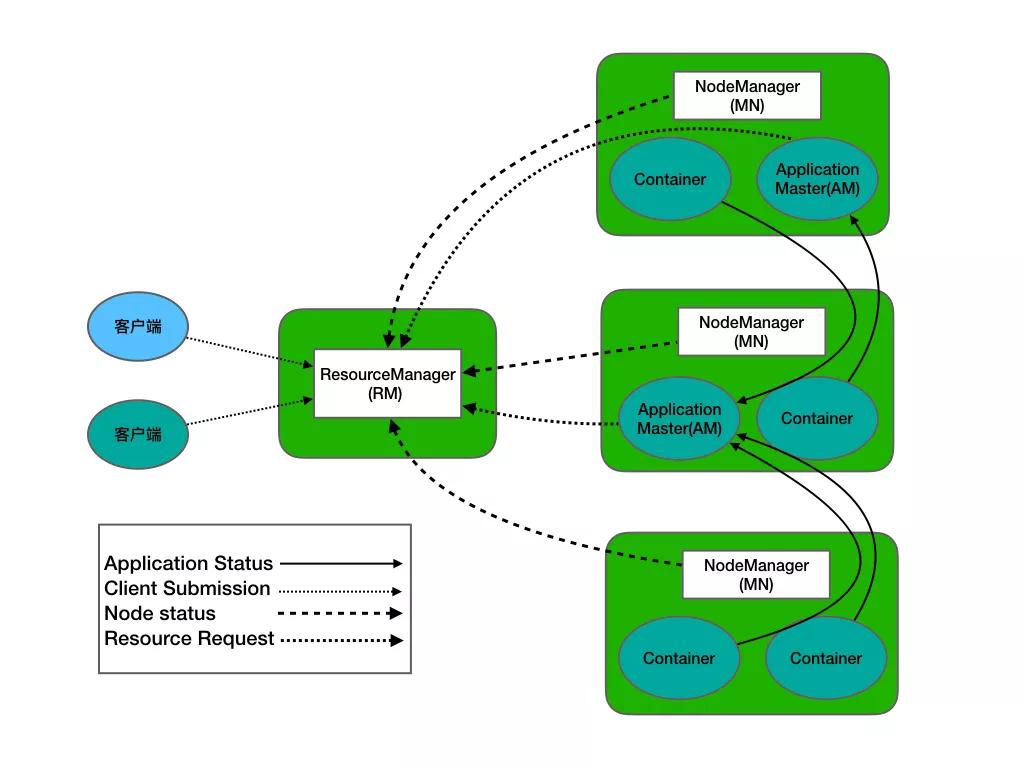
YARN总体上仍然是Master/Slave结构。在整个资源管理框架中,ResourceManager为Master,NodeManager为Slave,ResourceManager负责对各个NodeManager上的资源进行统一管理和调度。当用户提交一个应用程序时,需要提供一个用以跟踪和管理这个程序的ApplicationMaster,它负责向ResourceManager申请资源,并要求NodeManger启动可以占用一定资源的任务。由于不同的ApplicationMaster被分布到不同的节点上,因此它们之间不会相互影响。
- ResourceManager
一个纯粹的调度器,专门负责集群中可用资源的分配和管理。
- 调度器Scheduler
- 应用程序管理器(Applications Manager)
- NodeManager
负责节点本地资源的管理,包括启动应用程序的Container,监控它们的资源使用情况,并报告给RM
- ApplicationMaster
特定框架库的一个实例,负责有RM协商资源,并和NM协调工作来执行和监控Container以及它们的资源消耗。AM也是以一个的Container身份运行。
ResourceManager
ResourceManager(RM)是一个全局的资源管理器,负责整个系统的资源管理和分配,主要包括两个组件,即调度器(Scheduler)和应用程序管理器(Applications Manager)。
调度器接收来自ApplicationMaster的应用程序资源请求,把集群中的资源以“容器”的形式分配给提出申请的应用程序,容器的选择通常会考虑应用程序所要处理的数据的位置,进行就近选择,从而实现“计算向数据靠拢”。
容器(Container)作为动态资源分配单位,每个容器中都封装了一定数量的CPU、内存、磁盘等资源,从而限定每个应用程序可以使用的资源量。
调度器被设计成是一个可插拔的组件,YARN不仅自身提供了许多种直接可用的调度器,也允许用户根据自己的需求重新设计调度器。
应用程序管理器(Applications Manager)负责系统中所有应用程序的管理工作,主要包括应用程序提交、与调度器协商资源以启动ApplicationMaster、监控ApplicationMaster运行状态并在失败时重新启动等。
NodeManager
NodeManager是驻留在一个YARN集群中的每个节点上的代理,主要负责:
- 容器生命周期管理
- 监控每个容器的资源(CPU、内存等)使用情况
- 跟踪节点健康状况
- 以“心跳”的方式与ResourceManager保持通信
- 向ResourceManager汇报作业的资源使用情况和每个容器的运行状态
- 接收来自ApplicationMaster的启动/停止容器的各种请求
需要说明的是,NodeManager主要负责管理抽象的容器,只处理与容器相关的事情,而不具体负责每个任务(Map任务或Reduce任务)自身状态的管理,因为这些管理工作是由ApplicationMaster完成的,ApplicationMaster会通过不断与NodeManager通信来掌握各个任务的执行状态。
ApplicationMaster
ResourceManager接收用户提交的作业,按照作业的上下文信息以及从NodeManager收集来的容器状态信息,启动调度过程,为用户作业启动一个ApplicationMaster。
ApplicationMaster的主要功能是:
- 当用户作业提交时,ApplicationMaster与ResourceManager协商获取资源,ResourceManager会以容器的形式为ApplicationMaster分配资源;
- 把获得的资源进一步分配给内部的各个任务(Map任务或Reduce任务),实现资源的“二次分配”;
- 与NodeManager保持交互通信进行应用程序的启动、运行、监控和停止,监控申请到的资源的使用情况,对所有任务的执行进度和状态进行监控,并在任务发生失败时执行失败恢复(即重新申请资源重启任务);
- 定时向ResourceManager发送“心跳”消息,报告资源的使用情况和应用的进度信息;
- 当作业完成时,ApplicationMaster向ResourceManager注销容器,执行周期完成。
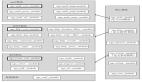
YARN的工作流程
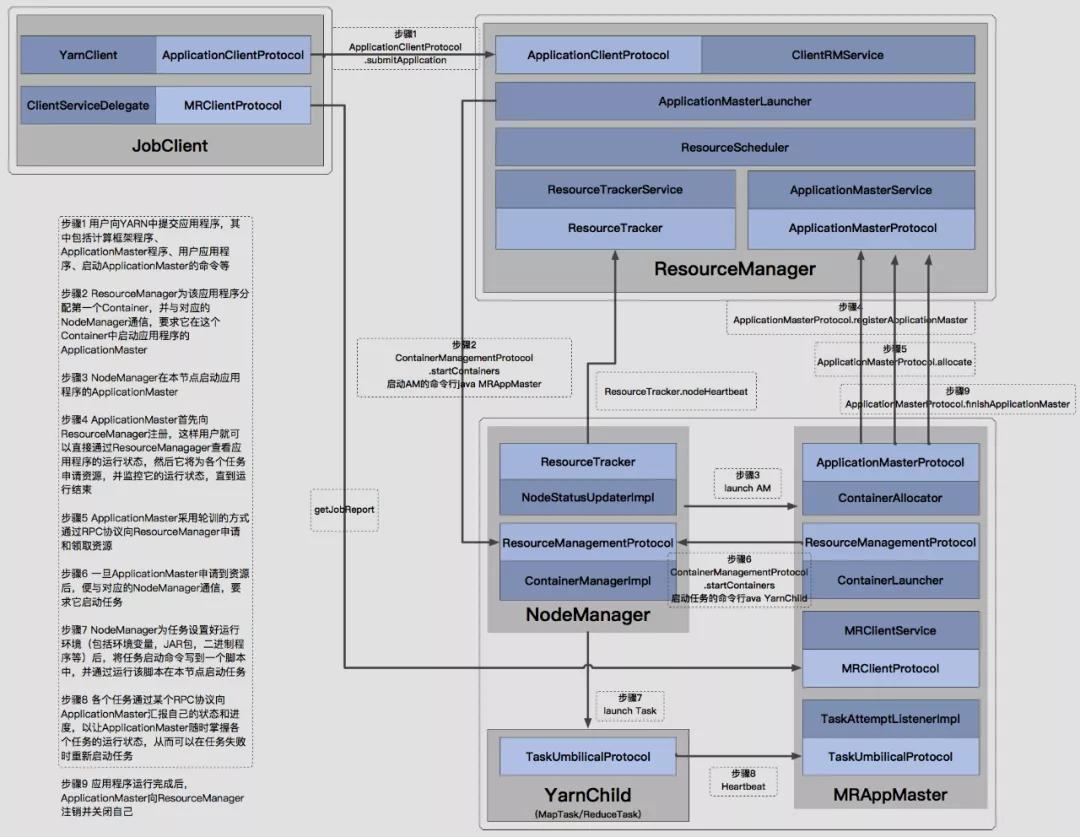
简单流程示意图如下:
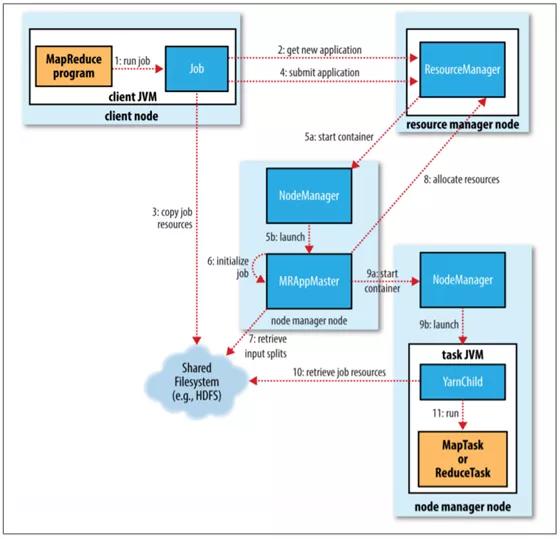
1.作业提交
JobSubmitter 实现的作业提交过程执行以下操作:
- 向资源管理器询问新的应用程序 ID,用于 MapReduce 作业 ID(步骤 2)。
- 检查作业的输出规范。例如,如果没有指定输出目录或已经存在,则不提交作业,并向 MapReduce 程序抛出错误。
- 计算作业的输入分片。如果无法计算分片(例如,因为输入路径不存在),则不会提交作业,并向 MapReduce 程序抛出错误。
- 将运行作业所需的资源(包括作业 JAR 文件、配置文件和计算的输入分片)复制到以作业 ID 命名的目录中的HDFS共享文件系统(步骤 3)。作业 JAR 会被复制多个副本,以便节点管理器(node managers)在为作业运行任务时可以访问集群中的大量副本。
- 通过在资源管理器上调用 submitApplication() 提交作业(步骤 4)。
2.作业初始化
- 当资源管理器收到对其 submitApplication() 方法的调用时,它会将请求移交给 YARN 调度程序。调度器分配一个容器,然后资源管理器启动appmaster。
- MapReduce 作业的app master是一个 Java 应用程序,初始化作业并跟踪任务的完成进度(步骤 6)。
- 接下来,它从共享文件系统中检索在客户端计算的输入分片(步骤 7)。然后它为每个split创建一个map任务以及一些reduce任务。
- app master决定如何运行构成 MapReduce 作业的任务。如果作业很小,app master可能会选择在与自己相同的 JVM 中运行任务。
任务分配
- 如果该作业不符合与app master在相同的JVM中运行的条件,app master会向资源管理器请求该作业中所有 map 和 reduce 任务的container(步骤 8)。
- 对 map 任务的请求首先进行,并且具有比 reduce 任务更高的优先级,因为所有 map 任务必须在 reduce 的排序阶段开始之前完成。直到 5% 的 map 任务完成后才会请求 reduce 任务。
- Reduce 任务可以在集群中的任何位置运行,但对 map 任务具有数据本地性的限制。
- 在最佳情况下,任务是本地数据,即在分片所在的同一节点上运行。或者,任务可能是机架本地的:与分片在同一机架上,但不在同一节点上。有些任务既不在同一节点又不在同一机架,而是需要从不同机架不同节点中检索数据。
- 请求还指定了任务的内存和CPU要求 。默认情况下,每个 map 和 reduce 任务都分配了 1024 MB 的内存和一个虚拟内核。
任务执行
- 一旦资源管理器的调度程序为特定节点上的容器分配了资源,app master将通过联系nodemanager来启动容器(步骤 9a 和 9b)。
- 最后,它运行 map 或 reduce 任务(步骤 11)。
作业完成
- 当app master收到作业的最后一个任务已完成的通知时,它会将作业的状态更改为“成功”。
- 然后,当 Job 轮询状态时,它得知作业已成功完成,会打印一条消息告诉用户,然后从 waitForCompletion() 方法返回。
- 此时作业统计信息和计数器会打印到控制台。
- 最后,在作业完成时,app master和任务容器清理它们的工作状态(中间输出被删除)。作业信息由作业历史服务器存档,以便用户以后在需要时查询。
总结
Hadoop生态系统是工业界应用最广泛的大数据生态系统。作为Hadoop 生态圈的重要一员,YARN在开源大数据领域有着重要的地位,很多计算框架都能够运行在YARN上,比如Spark,Flink,Storm等。对于大多数公司的大数据计算场景,采用YARN来管理集群,是一个比较常见的解决方案。